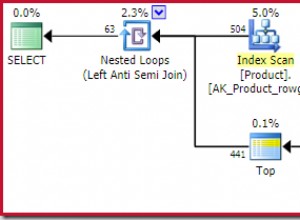
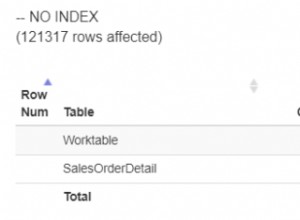
Bueno, para cada fila en "grupos", postgresql está haciendo un escaneo completo de categorías_productos, lo cual no es bueno. No es necesariamente un problema de configuración, pero ¿quizás la consulta podría establecerse sin anidar subconsultas como esa?
SELECT count(DISTINCT "groups".id) AS count_all
FROM "groups"
WHERE exists(
select 1 from products p where groups.id = p.group_id
join products_categories pc on pc.product_id = p.id
where pc.category_id in (2,3)
) and groups.id <> 3
También hace products_categories tener un índice en product_id ?