Bueno, lo primero que haría es dejar caer el análisis de cadenas repugnante en todas partes y reemplazarlo con tipos nativos de PostgreSQL. Para almacenar el estado de replicación en cada registro similar a su solución actual:
CREATE TYPE replication_status AS ENUM (
'no_action',
'replicate_record',
'record_replicated',
'error_1',
'error_2',
'error_3'
);
ALTER TABLE t ADD COLUMN rep_status_array replication_status[];
Esto le cuesta un poco más de espacio de almacenamiento:los valores de enumeración son de 4 bytes en lugar de 1 y las matrices tienen cierta sobrecarga. Sin embargo, al enseñarle a la base de datos sus conceptos en lugar de ocultarlos, puede escribir cosas como:
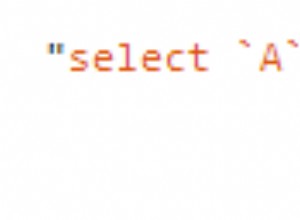
-- find all records that need to be replicated to host 4
SELECT * FROM t WHERE rep_status_array[4] = 'replicate_record';
-- find all records that contain any error status
SELECT * FROM t WHERE rep_status_array &&
ARRAY['error_1', 'error_2', 'error_3']::replication_status[];
Puede poner un índice GIN directamente en rep_status_array si eso ayuda a su caso de uso, pero es mejor mirar sus consultas y crear índices específicamente para lo que usa:
CREATE INDEX t_replication_host_4_key ON t ((rep_status_array[4]));
CREATE INDEX t_replication_error_key ON t (id)
WHERE rep_status_array && ARRAY['error_1', 'error_2', 'error_3']::replication_status[];
Dicho esto, dadas 200 tablas, estaría tentado a dividir esto en una sola tabla de estado de replicación, ya sea una fila con una matriz de estados o una fila por host, según cómo funcione el resto de la lógica de replicación. Todavía usaría esa enumeración:
CREATE TABLE adhoc_replication (
record_id bigint not null,
table_oid oid not null,
host_id integer not null,
replication_status status not null default 'no_action',
primary key (record_id,table_oid,host_id)
);
PostgreSQL asigna internamente a cada tabla un OID (pruebe SELECT *, tableoid FROM t LIMIT 1 ), que es un identificador numérico estable conveniente dentro de un único sistema de base de datos. Dicho de otra manera, cambia si la tabla se elimina y se vuelve a crear (lo que puede suceder si, por ejemplo, volca y restaura la base de datos), y por esta misma razón es muy probable que sea diferente entre el desarrollo y la producción. Si prefiere que estas situaciones funcionen a cambio de interrupciones cuando agrega o cambia el nombre de una tabla, use una enumeración en lugar de un OID.
El uso de una sola tabla para toda la replicación le permitiría reutilizar fácilmente activadores y consultas y demás, desvinculando la mayor parte de la lógica de replicación de los datos que está replicando. También le permite consultar según el estado de un host determinado en todas sus tablas de origen al hacer referencia a un solo índice, lo que podría ser importante.
En cuanto al tamaño de la tabla, PostgreSQL definitivamente puede manejar 10 millones de filas en la misma tabla. Si optó por una tabla dedicada relacionada con la replicación, siempre podría partición por anfitrión. (La partición por tabla tiene poco sentido para mí; parece peor que almacenar el estado de replicación en cada fila ascendente). La forma de partición o si es apropiada o no depende completamente del tipo de preguntas que pretenda hacer a su base de datos, y qué tipo de actividad ocurre en las tablas base. (Dividir significa mantener muchos blobs más pequeños en lugar de unos pocos grandes, y potencialmente acceder a muchos blobs más pequeños para realizar una sola operación). Realmente es una cuestión de elegir cuándo desea que su disco suceda.