Postgres puede usar columnas no iniciales en un índice de árbol b, pero en un modo mucho menos eficiente.
Si la primera columna es muy selectiva (solo unas pocas filas por A ) apenas notará una diferencia en el rendimiento ya que cualquiera de los métodos de acceso (incluso un escaneo secuencial sobre el conjunto reducido) es económico. El impacto en el rendimiento crece con el número de filas por A .
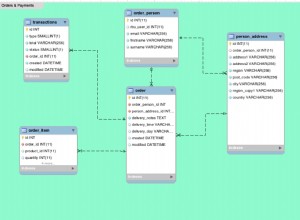
Para el caso que describe, sugiero crear el índice en (A, C, B) o (C, A, B) (solo asegúrese de que B viene en último lugar) para optimizar el rendimiento. De esta manera, obtiene el mejor rendimiento para las consultas en (A, B, C) y en (A, C) iguales.
A diferencia de la secuencia de columnas en el índice, la secuencia de predicados en la consulta no importa.
Hemos discutido esto con gran detalle en dba.SE:
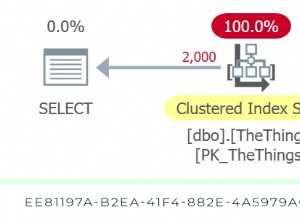
Tenga en cuenta que no importa si lideras con A, C o C, A para el caso que nos ocupa:
También hay algunas otras consideraciones, pero su pregunta no tiene todos los detalles relevantes.