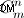Para buscar todas las filas con números de teléfono duplicados (entre columnas):
SELECT *
FROM contacts c
WHERE EXISTS (
SELECT FROM contacts x
WHERE x.mobile_phone IN (c.mobile_phone, c.home_phone)
OR x.home_phone IN (c.mobile_phone, c.home_phone)
AND x.contact_id <> c.contact_id -- except self
);
Para encontrar todos los números de teléfono duplicados en las dos columnas:
SELECT DISTINCT phone
FROM (
SELECT mobile_phone AS phone
FROM contacts c
WHERE EXISTS (
SELECT FROM mobile_phone x
WHERE c.mobile_phone IN (x.mobile_phone, x.home_phone)
AND c.contact_id <> x.contact_id -- except self
)
UNION ALL
SELECT home_phone
FROM contacts c
WHERE EXISTS (
SELECT FROM mobile_phone x
WHERE c.home_phone = x.home_phone -- cross-over covered by 1s SELECT
AND c.contact_id <> x.contact_id -- except self
)
) sub;
Repetir el mismo número en ambas columnas de la misma fila no califica No creo que quieras incluirlos. (Seguiría siendo un ruido que valdría la pena rechazar con un CHECK restricción.)