Si suelta el SearchRank y solo filtre usando la consulta, usará el índice GIN y funcionará mucho, mucho más rápido:
query = SearchQuery(termo,config='portuguese')
entries = Article.objects.filter(search_vector=query)
Puede agregar .explain()
para finalizar para echar un vistazo a la consulta y ver si se utiliza el índice:
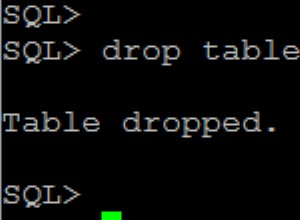
print(entries.explain(analyze=True))
Debería ver la consulta utilizando Bitmap Heap Scan y el tiempo de ejecución debería ser mucho más rápido.
Bitmap Heap Scan on your_table
...
Planning Time: 0.176 ms Execution Time: 0.453 ms
Cuando anota como lo hace arriba, está anotando cada Article objeto - por lo que postgres decide realizar un Seq Scan (o Parallel Seq Scan) que decide que es más eficiente. Más información aquí
Intente agregar .explain(verbose=True) o .explain(analyze=True) a su método SearchRank inicial para comparar.
query = SearchQuery(termo,config='portuguese')
search_rank = SearchRank(F('search_vector'), query)
entries = Article.objects.annotate(rank=search_rank).filter(search_vector=query).order_by('-rank')
print(entries.explain(analyze=True))
Yo mismo me enfrento a este problema, con una tabla con 990k entradas que tarda ~10 segundos. Si puede filtrar la consulta antes de la anotación usando cualquier otro campo, hará que el planificador de consultas vuelva a usar el Índice.