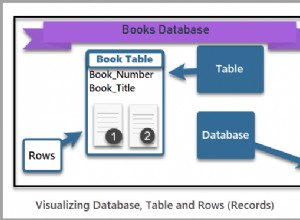
Creo que debería leer sobre Normalización de bases de datos y decide por ti mismo. Sin embargo, en resumen, hay una serie de problemas con su propuesta, pero puede decidir que puede vivir con ellos.
Los más obvios son:
- ¿Qué sucede si se agrega una etiqueta adicional a la fila (1)? ¿Tiene que analizar primero, verificar si ya está presente y luego actualizar la fila para que sea
tags.append(newTag). - ¿Peor aún, eliminar una etiqueta? Buscar etiquetas, está presente, volver a crear etiquetas.
- ¿Qué sucede si una etiqueta debe cambiar de nombre? ¿Quizás algún proceso de moderación?
- Peor aún, ¿qué pasa con las diferentes personas que especifican un nombre de etiqueta de manera diferente? Sería difícil de racionalizar.
- ¿Qué pasa si desea consultar datos basados en etiquetas? Su consulta se vuelve mucho más compleja de lo que debería ser.
- Presentación:el cliente tiene que analizar la etiqueta para usarla. ¿Qué pasa con el campo separador? Cambie eso y todos los clientes tendrán que cambiar.
En definitiva, todas estas operaciones se vuelven más duras y engorrosas. La normalización está diseñada para superar tales problemas. Probablemente, la única razón para hacer lo que dice, en mi opinión, es que está capturando los datos como únicos y solo informativos, es decir, tiene sentido para un usuario pero no para un sistema per se. Esto es como decir que probablemente sea mejor evitarlo (otra vez, en mi opinión).