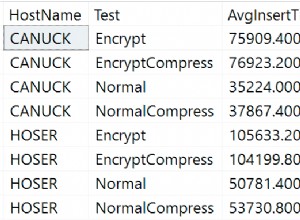
Lo más importante es que JOIN y GROUP sobre todo solo para obtener max(created) . Obtenga este valor por separado.
Mencionaste todos los índices que se necesitan aquí:en report_rank.created y en las claves foráneas. Lo estás haciendo bien allí. (Si está interesado en algo mejor que "bien", siga leyendo !)
El LEFT JOIN report_site se verá obligado a un simple JOIN por el WHERE cláusula. Sustituí un simple JOIN . También simplifiqué mucho tu sintaxis.
Actualizado en julio de 2015 con consultas más simples y rápidas y funciones más inteligentes.
Solución para varias filas
report_rank.created es no único y quieres todo las últimas filas.
Usando la función de ventana rank()
en una subconsulta.
SELECT r.id, r.keyword_id, r.site_id
, r.rank, r.url, r.competition
, r.source, r.country, r.created -- same as "max"
FROM (
SELECT *, rank() OVER (ORDER BY created DESC NULLS LAST) AS rnk
FROM report_rank r
WHERE EXISTS (
SELECT *
FROM report_site s
JOIN report_profile p ON p.site_id = s.id
JOIN crm_client c ON c.id = p.client_id
JOIN auth_user u ON u.id = c.user_id
WHERE s.id = r.site_id
AND u.is_active
AND c.is_deleted = FALSE
)
) sub
WHERE rnk = 1;
Por qué DESC NULLS LAST ?
Solución para una fila
Si report_rank.created es único o está satisfecho con cualquier fila con max(created) :
SELECT id, keyword_id, site_id
, rank, url, competition
, source, country, created -- same as "max"
FROM report_rank r
WHERE EXISTS (
SELECT 1
FROM report_site s
JOIN report_profile p ON p.site_id = s.id
JOIN crm_client c ON c.id = p.client_id
JOIN auth_user u ON u.id = c.user_id
WHERE s.id = r.site_id
AND u.is_active
AND c.is_deleted = FALSE
)
-- AND r.created > f_report_rank_cap()
ORDER BY r.created DESC NULLS LAST
LIMIT 1;
Debería ser más rápido, aún. Más opciones:
Ultimate Speed con índice parcial ajustado dinámicamente
Es posible que haya notado la parte comentada en la última consulta:
AND r.created > f_report_rank_cap()
Mencionaste 50 millones. filas, eso es mucho. Aquí hay una manera de acelerar las cosas:
- Cree un
IMMUTABLEsimple función que devuelve una marca de tiempo que garantiza que es más antigua que las filas de interés y que es lo más joven posible. - Cree un índice parcial solo en filas más jóvenes, según esta función.
- Use un
WHEREcondición en las consultas que coincide con la condición del índice. - Cree otra función que actualice estos objetos a la fila más reciente con DDL dinámico. (Menos un margen seguro en caso de que las filas más nuevas se eliminen o desactiven, si eso puede suceder)
- Invoque esta función secundaria en momentos de inactividad con un mínimo de actividad simultánea por cronjob o bajo demanda. Con la frecuencia que desee, no puede hacer daño, solo necesita un breve bloqueo exclusivo en la mesa.
Aquí hay una demostración de trabajo completa .
@erikcw, deberá activar la parte comentada como se indica a continuación.
CREATE TABLE report_rank(created timestamp);
INSERT INTO report_rank VALUES ('2011-11-11 11:11'),(now());
-- initial function
CREATE OR REPLACE FUNCTION f_report_rank_cap()
RETURNS timestamp LANGUAGE sql COST 1 IMMUTABLE AS
$y$SELECT timestamp '-infinity'$y$; -- or as high as you can safely bet.
-- initial index; 1st run indexes whole tbl if starting with '-infinity'
CREATE INDEX report_rank_recent_idx ON report_rank (created DESC NULLS LAST)
WHERE created > f_report_rank_cap();
-- function to update function & reindex
CREATE OR REPLACE FUNCTION f_report_rank_set_cap()
RETURNS void AS
$func$
DECLARE
_secure_margin CONSTANT interval := interval '1 day'; -- adjust to your case
_cap timestamp; -- exclude older rows than this from partial index
BEGIN
SELECT max(created) - _secure_margin
FROM report_rank
WHERE created > f_report_rank_cap() + _secure_margin
/* not needed for the demo; @erikcw needs to activate this
AND EXISTS (
SELECT *
FROM report_site s
JOIN report_profile p ON p.site_id = s.id
JOIN crm_client c ON c.id = p.client_id
JOIN auth_user u ON u.id = c.user_id
WHERE s.id = r.site_id
AND u.is_active
AND c.is_deleted = FALSE)
*/
INTO _cap;
IF FOUND THEN
-- recreate function
EXECUTE format('
CREATE OR REPLACE FUNCTION f_report_rank_cap()
RETURNS timestamp LANGUAGE sql IMMUTABLE AS
$y$SELECT %L::timestamp$y$', _cap);
-- reindex
REINDEX INDEX report_rank_recent_idx;
END IF;
END
$func$ LANGUAGE plpgsql;
COMMENT ON FUNCTION f_report_rank_set_cap()
IS 'Dynamically recreate function f_report_rank_cap()
and reindex partial index on report_rank.';
Llamar:
SELECT f_report_rank_set_cap();
Ver:
SELECT f_report_rank_cap();
Descomente la cláusula AND r.created > f_report_rank_cap() en la consulta anterior y observe la diferencia. Verifique que el índice se use con EXPLAIN ANALYZE .
El manual sobre concurrencia y REINDEX
: