No es fácil porque tiene diferentes números de productos coincidentes en la última fila en comparación con las otras filas. Es posible que pueda hacerlo con algún tipo de operador GROUP_CONCAT() (disponible en MySQL; implementable en otros DBMS, como Informix y probablemente PostgreSQL), pero no estoy seguro de eso.
Coincidencia por parejas
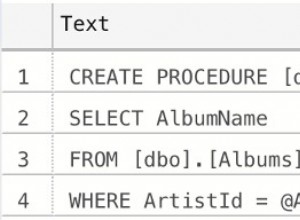
SELECT p1.product_name AS name1, p2.product_name AS name2, COUNT(*)
FROM (SELECT p.product_name, h.transaction_id
FROM products AS p
JOIN transactions_has_products AS h ON h.product_id = p.product_id
) AS p1
JOIN (SELECT p.product_name, h.transaction_id
FROM products AS p
JOIN transactions_has_products AS h ON h.product_id = p.product_id
) AS p2
ON p1.transaction_id = p2.transaction_id
AND p1.product_name < p2.product_name
GROUP BY p1.name, p2.name;
Manejar el partido triple no es trivial; extenderlo más allá de eso es definitivamente bastante difícil.