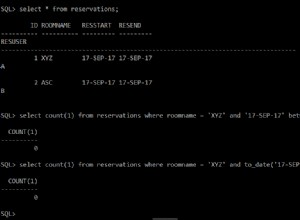
El primer enfoque que me viene a la mente es usar row_number() para anotar la tabla, luego agrupar por bloques de 16 filas.
SELECT min(id) as first_id, max(id) AS last_id, avg(rainfall) AS avg_this_16
FROM (
SELECT id, rainfall, row_number() OVER (order by id) AS n
FROM the_table
) x(id,rainfall,n)
GROUP BY n/16
ORDER BY n/16;
Tenga en cuenta que esto no incluirá necesariamente 16 muestras para el último grupo.
Alternativamente, puede calcular un promedio móvil usando avg() como función de ventana:
SELECT id, avg(rainfall) OVER (ORDER BY id ROWS 15 PRECEDING)
FROM the_table;
... posiblemente anotando eso con el número de fila y seleccionando los que desea:
SELECT id AS greatest_id_in_group, avg_last_16_inclusive FROM (
SELECT
id,
avg(rainfall) OVER (ORDER BY id ROWS 15 PRECEDING) AS avg_last_16_inclusive,
row_number() OVER (ORDER BY id) AS n
FROM the_table
) x WHERE n % 16 = 0;
Esto ignorará las últimas n<16 muestras y no devolverá una fila para ellas.
Tenga en cuenta que asumo que no se garantiza que las ID sean contiguas. Si no tienen espacios, puede simplemente group by id/16 y evitar la función de ventana.