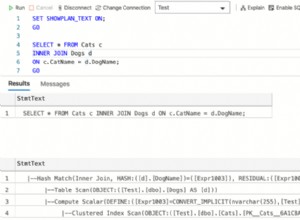
Una vista materializada es el camino a seguir para lo que describiste. Consultar meses anteriores de datos de solo lectura funciona sin actualizarlos. Es posible que desee hacer un caso especial del mes actual si necesita cubrir eso también.
La consulta subyacente aún puede beneficiarse de un índice, y hay dos direcciones que puede tomar:
En primer lugar, índices parciales como tiene ahora no comprará mucho en su escenario, no vale la pena. Si recopila muchos más meses de datos y consulta principalmente por mes (y agrega / suelta filas por mes) particionamiento de tablas podría ser una idea, entonces también tiene sus índices particionados automáticamente. Sin embargo, consideraría Postgres 11 o incluso el próximo Postgres 12 para esto).
Si tus filas son anchas , cree un índice que permita escaneos de solo índice . Me gusta:
CREATE INDEX reportimpression_covering_idx ON reportimpression(datelocal, views, gender);
Relacionado:
O INCLUDE columnas adicionales en Postgres 11 o posterior:
CREATE INDEX reportimpression_covering_idx ON reportimpression(datelocal) INCLUDE (views, gender);
Más , si sus filas están ordenadas físicamente por datelocal , considere un índice BRIN
. Es extremadamente pequeño y probablemente tan rápido como un índice de árbol B para su caso. (Pero al ser tan pequeño, permanecerá en caché mucho más fácilmente y no eliminará tanto otros datos).
CREATE INDEX reportimpression_brin_idx ON reportimpression USING BRIN (datelocal);
Puede estar interesado en CLUSTER
o pg_repack
para ordenar físicamente las filas de la tabla. pg_repack puede hacerlo sin bloqueos exclusivos en la tabla e incluso sin un índice btree (requerido por CLUSTER ). Pero es un módulo adicional que no se envía con la distribución estándar de Postgres.
Relacionado:
- Optimizar la eliminación de Postgres de registros huérfanos
- ¿Cómo recuperar espacio en disco después de eliminar sin reconstruir la tabla?