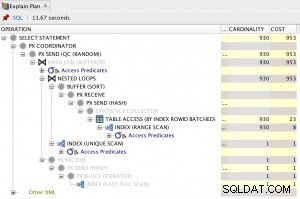
Independientemente de cuántos índices haya creado en la relación, solo uno de ellos se utilizará en una determinada consulta (que depende de la consulta, las estadísticas, etc.). Entonces, en su caso, no obtendría una ventaja acumulativa al crear dos índices de una sola columna. Para obtener el máximo rendimiento del índice, sugeriría usar el índice compuesto en (ubicación, marca de tiempo).
Tenga en cuenta que las consultas como ... WHERE timestamp BETWEEN smth AND smth no usará el índice anterior mientras consultas como ... WHERE location = 'smth' o ... WHERE location = 'smth' AND timestamp BETWEEN smth AND smth voluntad. Es porque el primer atributo en el índice es crucial para buscar y clasificar.
No te olvides de realizar
ANALYZE;
después de la creación del índice para recopilar estadísticas.
Actualización: Como @MondKin mencionado en los comentarios, ciertas consultas pueden usar varios índices en la misma relación. Por ejemplo, consulta con OR cláusulas como a = 123 OR b = 456 (asumiendo que hay índices para ambas columnas). En este caso, postgres realizaría escaneos de índices de mapas de bits para ambos índices, crearía una unión de los mapas de bits resultantes y la usaría para escanear montones de mapas de bits. En ciertas condiciones, se puede usar el mismo esquema para AND consultas pero en lugar de unión habría una intersección.