Como explicó Frank, PostgreSQL rechazará cualquier consulta que no devuelva un conjunto reproducible de filas.
Suponga que tiene una consulta como:
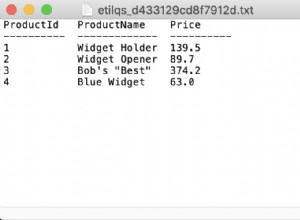
select a, b, agg(c)
from tbl
group by a
PostgreSQL lo rechazará porque b se deja sin especificar en el group by declaración. Ejecute eso en MySQL, por el contrario, y será aceptado. En el último caso, sin embargo, active algunas inserciones, actualizaciones y eliminaciones, y el orden de las filas en las páginas del disco terminará siendo diferente.
Si la memoria sirve, los detalles de implementación son para que MySQL realmente clasifique por a, b y devuelva la primera b en el conjunto. Pero en lo que respecta al estándar SQL, el comportamiento no está especificado y, por supuesto, PostgreSQL no. siempre ordene antes de ejecutar funciones agregadas.
Potencialmente, esto podría resultar en diferentes valores de b en el conjunto de resultados en PostgreSQL. Y por lo tanto, PostgreSQL genera un error a menos que sea más específico:
select a, b, agg(c)
from tbl
group by a, b
Lo que Frank destacó es que, en PostgreSQL 9.1, si a es la clave principal, puede dejar b no especificado:se le ha enseñado al planificador a ignorar los campos subsiguientes de agrupación cuando las claves primarias aplicables implican una fila única.
Para su problema en particular, debe especificar su grupo como lo hace actualmente, más cada campo en el que está basando su agregado, es decir, "widgets"."id", "widgets"."user_id", [snip] pero no cosas como sum(amount) , que son las llamadas a funciones agregadas.
Como nota al margen fuera del tema, no estoy seguro de cómo funciona su ORM/modelo, pero el SQL que está generando no es óptimo. Muchas de esas uniones externas izquierdas parecen que deberían ser uniones internas. Esto permitirá que el planificador elija un orden de unión apropiado cuando corresponda.