Cuando tiene tanto el LÍMITE como el ORDEN POR, el optimizador ha decidido que es más rápido recorrer los registros sin filtrar en foo por tecla descendente hasta que obtenga cinco coincidencias para el resto de los criterios. En los demás casos, simplemente ejecuta la consulta como un bucle anidado y devuelve todos los registros.
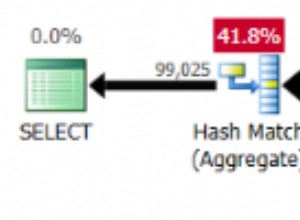
De entrada, diría que el problema es que PG no asimila la articulación distribución de las diversas identificaciones y es por eso que el plan es tan subóptimo.
Para posibles soluciones:asumiré que ha ejecutado ANALYZE recientemente. Si no, hazlo. Eso puede explicar por qué sus tiempos estimados son altos incluso en la versión que regresa rápido. Si el problema persiste, tal vez ejecute ORDER BY como una subselección y aplique LIMIT en una consulta externa.