Esta es la segunda entrega de una serie de dos partes sobre repmgr de 2ndQuadrant, una herramienta de código abierto de alta disponibilidad para PostgreSQL.
En la primera parte, configuramos un clúster PostgreSQL 12 de tres nodos junto con un nodo "testigo". El clúster constaba de un nodo principal y dos nodos de reserva. El clúster y el nodo testigo se alojaron en una nube privada virtual (VPC) de Amazon Web Service. Los servidores EC2 que alojan las instancias de Postgres se colocaron en subredes en diferentes zonas de disponibilidad (AZ), como se muestra a continuación:
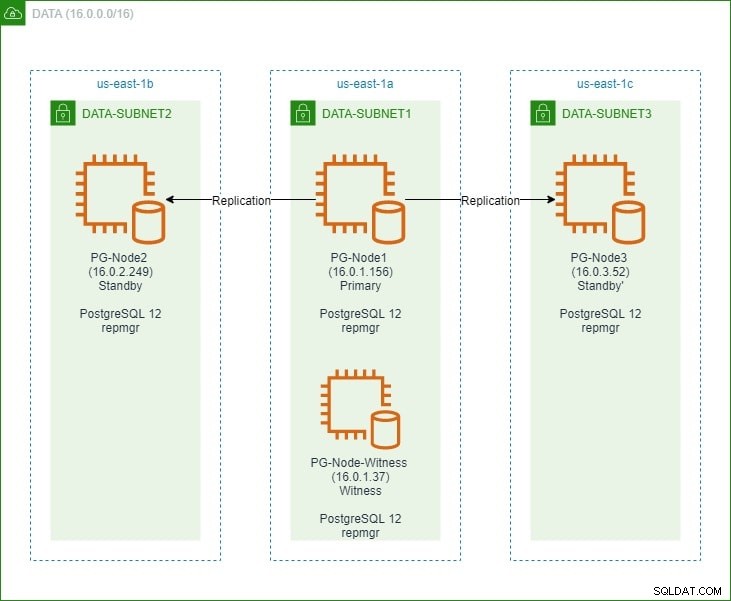
Haremos amplias referencias a los nombres de los nodos y sus direcciones IP, así que aquí está la tabla nuevamente con los detalles de los nodos:
| Nombre de nodo | Dirección IP | Rol | Aplicaciones en ejecución |
| PG-Nodo1 | 16.0.1.156 | Principal | PostgreSQL 12 y repmgr |
| PG-Nodo2 | 16.0.2.249 | Espera 1 | PostgreSQL 12 y repmgr |
| PG-Nodo3 | 16.0.3.52 | Espera 2 | PostgreSQL 12 y repmgr |
| Nodo-PG-Testigo | 16.0.1.37 | Testigo | PostgreSQL 12 y repmgr |
Instalamos repmgr en los nodos principal y en espera y luego registramos el nodo principal con repmgr. Luego, clonamos ambos nodos en espera del principal y los iniciamos. Ambos nodos en espera también se registraron con repmgr. El comando "repmgr cluster show" nos mostró que todo funcionaba como se esperaba:

Problema actual
Configurar la replicación de transmisión con repmgr es muy simple. Lo que debemos hacer a continuación es asegurarnos de que el clúster funcione incluso cuando el principal no esté disponible. Esto es lo que cubriremos en este artículo.
En la replicación de PostgreSQL, un primario puede dejar de estar disponible por varias razones. Por ejemplo:
- El sistema operativo del nodo principal puede bloquearse o dejar de responder
- El nodo principal puede perder su conexión de red
- El servicio de PostgreSQL en el nodo principal puede bloquearse, detenerse o dejar de estar disponible de forma inesperada
- El servicio de PostgreSQL en el nodo principal se puede detener de manera intencional o accidental
Cada vez que un primario deja de estar disponible, un standby no promocionarse automáticamente al rol principal. Un standby aún continúa atendiendo consultas de solo lectura, aunque los datos estarán actualizados hasta el último LSN recibido del principal. Cualquier intento de una operación de escritura fallará.
Hay dos formas de mitigar esto:
- El modo de espera es manual actualizado a un rol principal. Este suele ser el caso de una conmutación por error planificada o "conmutación"
- El modo de espera es automático promovido a un rol principal. Este es el caso de las herramientas no nativas que monitorean continuamente la replicación y toman medidas de recuperación cuando la principal no está disponible. repmgr es una de esas herramientas.
Consideraremos el segundo escenario aquí. Sin embargo, esta situación tiene algunos desafíos adicionales:
- Si hay más de un recurso auxiliar, ¿cómo decide la herramienta (o los recursos auxiliares) cuál debe promoverse como principal? ¿Cómo funciona el quórum y el proceso de promoción?
- Para múltiples recursos de reserva, si uno se convierte en principal, ¿cómo comienzan los otros nodos a "seguirlo" como el nuevo principal?
- ¿Qué sucede si el principal está funcionando, pero por algún motivo se desconecta temporalmente de la red? Si uno de los recursos de reserva se promociona a principal y luego el principal original vuelve a estar en línea, ¿cómo se puede evitar una situación de "cerebro dividido"?
Respuesta de remgr:nodo testigo y demonio repmgr
Para responder a estas preguntas, repmgr usa algo llamado nodo testigo . Cuando el nodo principal no está disponible, el trabajo del nodo testigo es ayudar a los nodos en espera a alcanzar un quórum si uno de ellos debe ascender a una función principal. Los standby alcanzan este quórum al determinar si el nodo principal está realmente fuera de línea o solo temporalmente. El nodo testigo debe estar ubicado en el mismo centro de datos/segmento de red/subred que el nodo principal, pero NUNCA debe ejecutarse en el mismo host físico que el nodo principal.
Recuerde que en la primera parte de esta serie, implementamos un nodo testigo en la misma zona de disponibilidad y subred que el nodo principal. Lo llamamos PG-Node-Witness e instalamos una instancia de PostgreSQL 12 allí. En esta publicación, también instalaremos repmgr allí, pero hablaremos de eso más adelante.
El segundo componente de la solución es el demonio repmgr (repmgrd) ejecutándose en todos los nodos del clúster y el nodo testigo. Nuevamente, no iniciamos este demonio en la primera parte de esta serie, pero lo haremos aquí. El daemon viene como parte del paquete repmgr:cuando está habilitado, se ejecuta como un servicio regular y monitorea continuamente el estado del clúster. Inicia una conmutación por error cuando se alcanza un quórum sobre la desconexión principal. No solo puede promocionar automáticamente un standby, sino que también puede reiniciar otros standby en un clúster de varios nodos para seguir al nuevo principal .
El proceso de quórum
Cuando un standby se da cuenta de que no puede ver el primario, consulta con otros standby. Todos los recursos de reserva que se ejecutan en el clúster alcanzan un quórum para elegir un nuevo servidor principal mediante una serie de comprobaciones:
- Cada standby interroga a otros standby sobre la última vez que "vio" el primario. Si el último LSN replicado de un standby o la hora de la última comunicación con el principal es más reciente que el último LSN replicado del nodo actual o la hora de la última comunicación, el nodo no hace nada y espera a que se restablezca la comunicación con el principal
- Si ninguno de los recursos de reserva puede ver el principal, verifican si el nodo testigo está disponible. Si tampoco se puede acceder al nodo testigo, los recursos de reserva asumen que hay una interrupción de la red en el lado primario y no proceden a elegir un nuevo primario.
- Si se puede contactar al testigo, los recursos de reserva asumen que el principal está inactivo y proceden a elegir un principal
- Luego se promoverá el nodo que se configuró como principal "preferido". Cada standby tendrá su replicación reiniciada para seguir al nuevo primario.
Configuración del clúster para conmutación por error automática
Ahora configuraremos el clúster y el nodo testigo para la conmutación por error automática.
Paso 1:instalar y configurar repmgr en Witness
Ya vimos cómo instalar el paquete repmgr en nuestro último artículo. También hacemos esto en el nodo testigo:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Y luego:
# yum install repmgr12 -y
A continuación, agregamos las siguientes líneas en el archivo postgresql.conf del nodo testigo:
listen_addresses = '*' shared_preload_libraries = 'repmgr'
También agregamos las siguientes líneas en el archivo pg_hba.conf en el nodo testigo. Tenga en cuenta cómo estamos utilizando el rango CIDR del clúster en lugar de especificar direcciones IP individuales.
local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 16.0.0.0/16 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 16.0.0.0/16 trust
Nota
[Los pasos descritos aquí son solo para fines de demostración. Nuestro ejemplo aquí es el uso de direcciones IP accesibles externamente para los nodos. El uso de listen_address ='*' junto con el mecanismo de seguridad de "confianza" de pg_hba, por lo tanto, representa un riesgo de seguridad y NO debe usarse en escenarios de producción. En un sistema de producción, todos los nodos estarán dentro de una o más subredes privadas, accesibles a través de IP privadas desde jumphosts.]
Con los cambios realizados en postgresql.conf y pg_hba.conf, creamos el usuario repmgr y la base de datos repmgr en el testigo, y cambiamos la ruta de búsqueda predeterminada del usuario repmgr:
[[email protected] ~]$ createuser --superuser repmgr [[email protected] ~]$ createdb --owner=repmgr repmgr [[email protected] ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
Finalmente, agregamos las siguientes líneas al archivo repmgr.conf, ubicado en /etc/repmgr/12/
node_id=4 node_name='PG-Node-Witness' conninfo='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2' data_directory='/var/lib/pgsql/12/data'
Una vez que se establecen los parámetros de configuración, reiniciamos el servicio PostgreSQL en el nodo testigo:
# systemctl restart postgresql-12.service
Para probar la conectividad con el nodo testigo repmgr, podemos ejecutar este comando desde el nodo principal:
[[email protected] ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
A continuación, registramos el nodo testigo con repmgr ejecutando el comando "regmgr testigo registro" como usuario de postgres. Tenga en cuenta cómo estamos usando la dirección del principal nodo, y NO el nodo testigo en el siguiente comando:
[[email protected] ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf witness register -h 16.0.1.156
Esto se debe a que el comando "regmgr testigo registro" agrega los metadatos del nodo testigo a la base de datos repmgr del nodo principal y, si es necesario, inicializa el nodo testigo instalando la extensión repmgr y copiando los metadatos repmgr en el nodo testigo.
La salida se verá así:
INFO: connecting to witness node "PG-Node-Witness" (ID: 4) INFO: connecting to primary node NOTICE: attempting to install extension "repmgr" NOTICE: "repmgr" extension successfully installed INFO: witness registration complete NOTICE: witness node "PG-Node-Witness" (ID: 4) successfully registered
Finalmente, verificamos el estado de la configuración general desde cualquier nodo:
[[email protected] ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
La salida se ve así:

Paso 2:Modificar el archivo sudoers
Con el clúster y el testigo ejecutándose, agregamos las siguientes líneas en el archivo sudoers En cada nodo del clúster y el nodo testigo:
Defaults:postgres !requiretty postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service, /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.service
Paso 3:Configuración de parámetros repmgrd
Ya hemos agregado cuatro parámetros en el archivo repmgr.conf en cada nodo. Los parámetros añadidos son los básicos necesarios para el funcionamiento de repmgr. Para habilitar el demonio repmgr y la conmutación por error automática, es necesario habilitar/agregar otros parámetros. En las siguientes subsecciones, describiremos cada parámetro y el valor que se establecerá en cada nodo.
conmutación por error
El parámetro de conmutación por error es uno de los parámetros obligatorios para el demonio repmgr. Este parámetro le dice al daemon si debe iniciar una conmutación por error automática cuando se detecta una situación de conmutación por error. Puede tener cualquiera de dos valores:"manual" o "automático". Estableceremos esto en automático en cada nodo:
failover='automatic'
comando_promover
Este es otro parámetro obligatorio para el demonio repmgr. Este parámetro le dice al daemon repmgr qué comando debe ejecutar para promover un modo de espera. El valor de este parámetro será normalmente el comando "repmgr standby promover" o la ruta a un script de shell que llama al comando. Para nuestro caso de uso, establecemos esto a lo siguiente en cada nodo:
promote_command='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'
seguir_comando
Este es el tercer parámetro obligatorio para el demonio repmgr. Este parámetro le dice a un nodo en espera que siga al nuevo primario. El daemon repmgr reemplaza el marcador de posición %n con el ID de nodo del nuevo principal en tiempo de ejecución:
follow_command='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'
prioridad
El parámetro de prioridad agrega peso a la elegibilidad de un nodo para convertirse en principal. Establecer este parámetro en un valor más alto otorga a un nodo una mayor elegibilidad para convertirse en el nodo principal. Además, establecer este valor en cero para un nodo garantizará que el nodo nunca se promocione como principal.
En nuestro caso de uso, tenemos dos standby:PG-Node2 y PG-Node3. Queremos promocionar PG-Node2 como el nuevo principal cuando PG-Node1 se desconecte, y PG-Node3 para seguir a PG-Node2 como su nuevo principal. Establecemos el parámetro en los siguientes valores en los dos nodos en espera:
| Nombre de nodo | Configuración de parámetros |
| PG-Nodo2 | prioridad =60 |
| PG-Nodo3 | prioridad =40 |
monitor_interval_secs
Este parámetro le dice al daemon repmgr con qué frecuencia (en número de segundos) debe verificar la disponibilidad del nodo ascendente. En nuestro caso, solo hay un nodo aguas arriba:el nodo principal. El valor predeterminado es 2 segundos, pero lo estableceremos explícitamente de todos modos en cada nodo:
monitor_interval_secs=2
tipo_comprobación_de_conexión
El parámetro connection_check_type dicta el protocolo que usará el daemon repmgr para comunicarse con el nodo ascendente. Este parámetro puede tomar tres valores:
- ping :repmgr usa el método PQPing()
- conexión :repmgr intenta crear una nueva conexión con el nodo ascendente
- consulta :repmgr intenta ejecutar una consulta SQL en el nodo ascendente utilizando la conexión existente
Nuevamente, estableceremos este parámetro en el valor predeterminado de ping en cada nodo:
connection_check_type='ping'
reconnect_attempts y reconnect_interval
Cuando el principal deja de estar disponible, el daemon repmgr en los nodos en espera intentará volver a conectarse al principal durante reconnect_attempts veces. El valor predeterminado para este parámetro es 6. Entre cada intento de reconexión, esperará reconnect_interval segundos, que tiene un valor predeterminado de 10. Para fines de demostración, usaremos un intervalo corto y menos intentos de reconexión. Establecemos este parámetro en cada nodo:
reconnect_attempts=4 reconnect_interval=8
primary_visibility_consensus
Cuando el principal deja de estar disponible en un clúster de varios nodos, los servidores de reserva pueden consultarse entre sí para crear un quórum sobre una conmutación por error. Esto se hace preguntando a cada dispositivo de reserva la hora en que vio por última vez al principal. Si la última comunicación de un nodo fue muy reciente y posterior a la hora en que el nodo local vio el principal, el nodo local asume que el principal todavía está disponible y no continúa con una decisión de conmutación por error.
Para habilitar este modelo de consenso, el parámetro primary_visibility_consensus debe establecerse en "verdadero" en cada nodo, incluido el testigo:
primary_visibility_consensus=true
standby_disconnect_on_failover
Cuando el parámetro standby_disconnect_on_failover se establece en "verdadero" en un nodo en espera, el demonio repmgr se asegurará de que su receptor WAL esté desconectado del principal y no reciba ningún segmento WAL. También esperará a que los receptores WAL de otros nodos en espera se detengan antes de tomar una decisión de conmutación por error. Este parámetro debe establecerse en el mismo valor en cada nodo. Estamos configurando esto en "verdadero".
standby_disconnect_on_failover=true
Establecer este parámetro en verdadero significa que cada nodo en espera ha dejado de recibir datos del principal a medida que ocurre la conmutación por error. El proceso tendrá un retraso de 5 segundos más el tiempo que tarda el receptor WAL en detenerse antes de que se tome una decisión de conmutación por error. De forma predeterminada, el demonio repmgr esperará 30 segundos para confirmar que todos los nodos hermanos han dejado de recibir segmentos WAL antes de que ocurra la conmutación por error.
repmgrd_service_start_command y repmgrd_service_stop_command
Estos dos parámetros especifican cómo iniciar y detener el daemon repmgr usando los comandos "repmgr daemon start" y "repmgr daemon stop".
Básicamente, estos dos comandos son envoltorios de los comandos del sistema operativo para iniciar/detener el servicio. Los dos valores de parámetro asignan estos comandos a sus versiones específicas del sistema operativo. Establecemos estos parámetros en los siguientes valores en cada nodo:
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgr12.service' repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgr12.service'
Comandos de inicio/detención/reinicio del servicio de PostgreSQL
Como parte de su funcionamiento, el demonio repmgr a menudo necesitará detener, iniciar o reiniciar el servicio de PostgreSQL. Para asegurarse de que esto suceda sin problemas, es mejor especificar los comandos del sistema operativo correspondientes como valores de parámetros en el archivo repmgr.conf. Estableceremos cuatro parámetros en cada nodo para este propósito:
service_start_command='sudo /usr/bin/systemctl start postgresql-12.service' service_stop_command='sudo /usr/bin/systemctl stop postgresql-12.service' service_restart_command='sudo /usr/bin/systemctl restart postgresql-12.service' service_reload_command='sudo /usr/bin/systemctl reload postgresql-12.service'
historial_de_supervisión
Establecer el parámetro monitoring_history en "sí" garantizará que repmgr guarde sus datos de supervisión del clúster. Establecemos esto en "sí" en cada nodo:
monitoring_history=yes
intervalo_de_estado_de_registro
Establecemos el parámetro en cada nodo para especificar con qué frecuencia el demonio repmgr registrará un mensaje de estado. En este caso, estamos configurando esto cada 60 segundos:
log_status_interval=60
Paso 4:Iniciar el demonio repmgr
Con los parámetros ahora establecidos en el clúster y el nodo testigo, ejecutamos una ejecución en seco del comando para iniciar el demonio repmgr. Probamos esto primero en el nodo principal y luego en los dos nodos en espera, seguidos por el nodo testigo. El comando debe ejecutarse como usuario de postgres:
[[email protected] ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
La salida debería verse así:
INFO: prerequisites for starting repmgrd met DETAIL: following command would be executed: sudo /usr/bin/systemctl start repmgr12.service
A continuación, iniciamos el demonio en los cuatro nodos:
[[email protected] ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
La salida en cada nodo debe mostrar que el daemon se ha iniciado:
NOTICE: executing: "sudo /usr/bin/systemctl start repmgr12.service" NOTICE: repmgrd was successfully started
También podemos verificar el evento de inicio del servicio desde los nodos primarios o en espera:
[[email protected] ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_start
La salida debería mostrar que el daemon está monitoreando las conexiones:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+---------------+----+---------------------+------------------------------------------------------------------ 4 | PG-Node-Witness | repmgrd_start | t | 2020-02-05 11:37:31 | witness monitoring connection to primary node "PG-Node1" (ID: 1) 3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitoring connection to upstream node "PG-Node1" (ID: 1) 2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitoring connection to upstream node "PG-Node1" (ID: 1) 1 | PG-Node1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitoring cluster primary "PG-Node1" (ID: 1)
Finalmente, podemos verificar la salida del daemon del syslog en cualquiera de los standby:
# cat /var/log/messages | grep repmgr | less
Aquí está la salida de PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] connecting to database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:24 PG-Node3 systemd[1]: repmgr12.service: Can't open PID file /run/repmgr/repmgrd-12.pid (yet?) after start: No such file or directory Feb 5 11:37:24 PG-Node3 repmgrd[2014]: INFO: set_repmgrd_pid(): provided pidfile is /run/repmgr/repmgrd-12.pid Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] starting monitoring of node "PG-Node3" (ID: 3) Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] monitoring connection to upstream node "PG-Node1" (ID: 1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [DETAIL] last monitoring statistics update was 2 seconds ago Feb 5 11:39:26 PG-Node3 repmgrd[2014]: [2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state … …
Verificar el syslog en el nodo principal muestra un tipo diferente de salida:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] connecting to database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] starting monitoring of node "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] monitoring cluster primary "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node-Witness" (ID: 4) is not yet attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node3" (ID: 3) is attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node2" (ID: 2) is attached Feb 5 11:37:32 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:32] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:38:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:38:14] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state Feb 5 11:39:15 PG-Node1 repmgrd[2017]: [2020-02-05 11:39:15] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state … …
Paso 5:Simular un primario fallido
Ahora simularemos un primario fallido deteniendo el nodo primario (PG-Node1). Desde el indicador de shell del nodo, ejecutamos el siguiente comando:
# systemctl stop postgresql-12.service
El proceso de conmutación por error
Una vez que el proceso se detiene, esperamos alrededor de uno o dos minutos y luego verificamos el archivo syslog de PG-Node2. Se muestran los siguientes mensajes. Para mayor claridad y simplicidad, tenemos grupos de mensajes codificados por colores y espacios en blanco agregados entre líneas:
… Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] checking state of node 1, 2 of 4 attempts Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] checking state of node 1, 3 of 4 attempts Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of node 1, 4 of 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to reconnect to node 1 after 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] wal receiver not running Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] WAL receiver disconnected on all sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] WAL receiver disconnected on all 2 sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] local node's last receive lsn: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node3" (ID: 3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 3 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] last receive LSN for sibling node "PG-Node3" (ID: 3) is: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has same LSN as current candidate "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has lower priority (40) than current candidate "PG-Node2" (ID: 2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node-Witness" (ID: 4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID: 4) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 4 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promotion candidate is "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] this node is the winner, will now promote itself and inform other nodes … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promoting standby to primary Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] promoting server "PG-Node2" (ID: 2) using pg_promote() Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE successful Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID: 2) was successfully promoted to primary Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] 2 followers to notify Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node3" (ID: 3) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node-Witness" (ID: 4) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] switching to primary monitoring mode Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] monitoring cluster primary "PG-Node2" (ID: 2) Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:55:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:55:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state Feb 5 11:56:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state … …
There is a lot of information here, but let’s break down how the events have unfolded. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
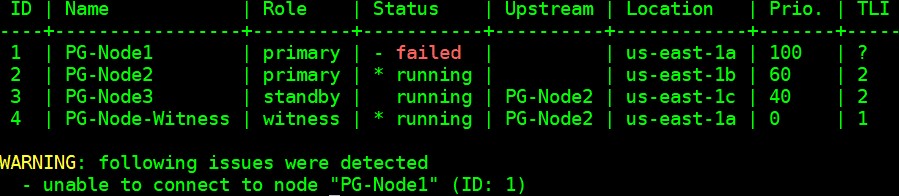
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[[email protected] ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[[email protected] ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------ 3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID: 2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID: 3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID: 4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID: 2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID: 2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID: 2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID: 4) has connected
Conclusión
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1



