Mientras ajusta postgresql.conf , es posible que haya notado que hay una opción llamada full_page_writes . El comentario al lado dice algo sobre escrituras de páginas parciales, y la gente generalmente lo deja configurado en on – lo cual es algo bueno, como explicaré más adelante en esta publicación. Sin embargo, es útil comprender qué hacen las escrituras de página completa, porque el impacto en el rendimiento puede ser bastante significativo.
A diferencia de mi publicación anterior sobre el ajuste del punto de control, esta no es una guía sobre cómo ajustar el servidor. En realidad, no hay mucho que pueda modificar, pero le mostraré cómo algunas decisiones a nivel de aplicación (por ejemplo, la elección de tipos de datos) pueden interactuar con las escrituras de página completa.
Escrituras parciales/páginas rotas
Entonces, ¿sobre qué se escribe a página completa? Como comentario en postgresql.conf dice que es una forma de recuperarse de escrituras de páginas parciales:PostgreSQL usa páginas de 8kB (de manera predeterminada), pero otras partes de la pila usan diferentes tamaños de fragmentos. Los sistemas de archivos de Linux generalmente usan páginas de 4kB (es posible usar páginas más pequeñas, pero 4kB es el máximo en x86), y a nivel de hardware, las unidades antiguas usaban sectores de 512B mientras que los dispositivos nuevos a menudo escriben datos en porciones más grandes (a menudo 4kB o incluso 8kB) .
Entonces, cuando PostgreSQL escribe la página de 8kB, las otras capas de la pila de almacenamiento pueden dividirla en partes más pequeñas, administradas por separado. Esto presenta un problema con respecto a la atomicidad de escritura. La página PostgreSQL de 8kB se puede dividir en dos páginas de sistema de archivos de 4kB y luego en sectores de 512B. Ahora, ¿qué sucede si el servidor falla (falla de energía, error del kernel, …)?
Incluso si el servidor usa un sistema de almacenamiento diseñado para lidiar con tales fallas (SSD con capacitores, controladores RAID con baterías, …), el kernel ya dividió los datos en páginas de 4kB. Por lo tanto, es posible que la base de datos haya escrito una página de datos de 8 kB, pero solo una parte llegó al disco antes del bloqueo.
En este punto, probablemente esté pensando que esta es exactamente la razón por la que tenemos el registro de transacciones (WAL), ¡y tiene razón! Entonces, después de iniciar el servidor, la base de datos leerá WAL (desde el último punto de control completado) y aplicará los cambios nuevamente para asegurarse de que los archivos de datos estén completos. Sencillo.
Pero hay un problema:la recuperación no aplica los cambios a ciegas, a menudo necesita leer las páginas de datos, etc. Lo que supone que la página aún no está dañada de alguna manera, por ejemplo, debido a una escritura parcial. Lo que parece un poco contradictorio, porque para corregir la corrupción de datos asumimos que no hay corrupción de datos.
Las escrituras de página completa son una forma de evitar este enigma:cuando se modifica una página por primera vez después de un punto de control, toda la página se escribe en WAL. Esto garantiza que durante la recuperación, el primer registro WAL que toca una página contiene la página completa, lo que elimina la necesidad de leer la página, posiblemente rota, del archivo de datos.
Amplificación de escritura
Por supuesto, la consecuencia negativa de esto es un mayor tamaño de WAL:cambiar un solo byte en la página de 8kB registrará todo en WAL. La escritura de página completa solo ocurre en la primera escritura después de un punto de control, por lo que hacer que los puntos de control sean menos frecuentes es una forma de mejorar la situación; por lo general, hay una breve "ráfaga" de escrituras de página completa después de un punto de control, y luego relativamente pocas escrituras de página completa. hasta el final de un punto de control.
UUID frente a claves BIGSERIAL
Pero hay algunas interacciones inesperadas con las decisiones de diseño que se toman a nivel de la aplicación. Supongamos que tenemos una tabla simple con clave principal, ya sea un BIGSERIAL o UUID , e insertamos datos en él. ¿Habrá una diferencia en la cantidad de WAL generada (asumiendo que insertamos la misma cantidad de filas)?
Parece razonable esperar que ambos casos produzcan aproximadamente la misma cantidad de WAL, pero como ilustran los siguientes gráficos, hay una gran diferencia en la práctica.
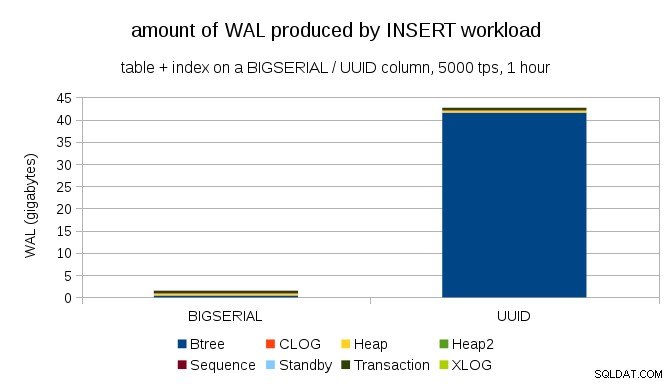
Esto muestra la cantidad de WAL producido durante un punto de referencia de 1 h, acelerado a 5000 inserciones por segundo. Con BIGSERIAL clave principal esto produce ~2GB de WAL, mientras que con UUID es más de 40 GB. Esa es una diferencia bastante significativa, y claramente la mayor parte de la WAL está asociada con el índice que respalda la clave principal. Veamos como tipos de registros WAL.
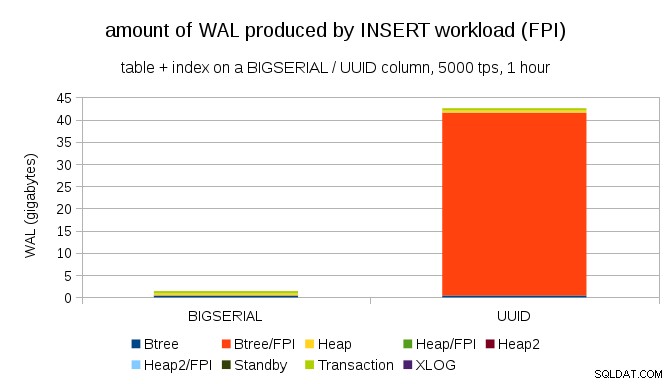
Claramente, la gran mayoría de los registros son imágenes de página completa (FPI), es decir, el resultado de escrituras de página completa. Pero, ¿por qué sucede esto?
Por supuesto, esto se debe al UUID inherente aleatoriedad Con BIGSERIAL new son secuenciales y, por lo tanto, se insertan en las mismas páginas de hoja en el índice btree. Como solo la primera modificación de una página activa la escritura de página completa, solo una pequeña fracción de los registros WAL son FPI. Con UUID es un caso completamente diferente, por supuesto:los valores no son secuenciales en absoluto, de hecho, es probable que cada inserción toque una página de hoja de índice de hoja completamente nueva (suponiendo que el índice sea lo suficientemente grande).
No hay mucho que la base de datos pueda hacer:la carga de trabajo es simplemente aleatoria por naturaleza, lo que desencadena muchas escrituras de página completa.
No es difícil obtener una amplificación de escritura similar incluso con BIGSERIAL llaves, por supuesto. Solo requiere una carga de trabajo diferente, por ejemplo, con UPDATE carga de trabajo, actualizando aleatoriamente registros con distribución uniforme, el gráfico se ve así:
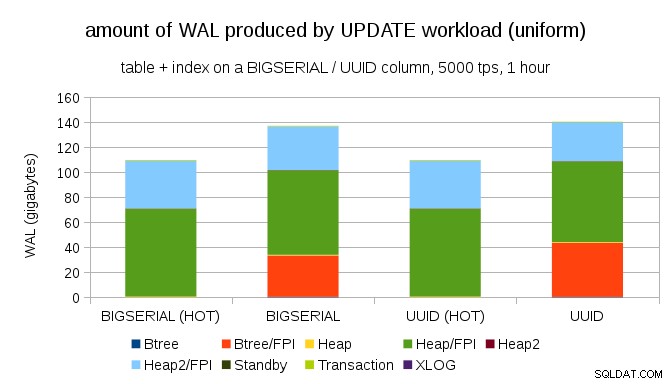
De repente, las diferencias entre los tipos de datos desaparecen:el acceso es aleatorio en ambos casos, lo que da como resultado casi exactamente la misma cantidad de WAL producida. Otra diferencia es que la mayor parte del WAL está asociado con "montón", es decir, tablas, y no índices. Los casos "HOT" se diseñaron para permitir la optimización HOT UPDATE (es decir, actualizar sin tener que tocar un índice), lo que prácticamente elimina todo el tráfico WAL relacionado con el índice.
Pero podría argumentar que la mayoría de las aplicaciones no actualizan todo el conjunto de datos. Por lo general, solo un pequeño subconjunto de datos está "activo":las personas solo acceden a publicaciones de los últimos días en un foro de discusión, pedidos sin resolver en una tienda electrónica, etc. ¿Cómo cambia eso los resultados?
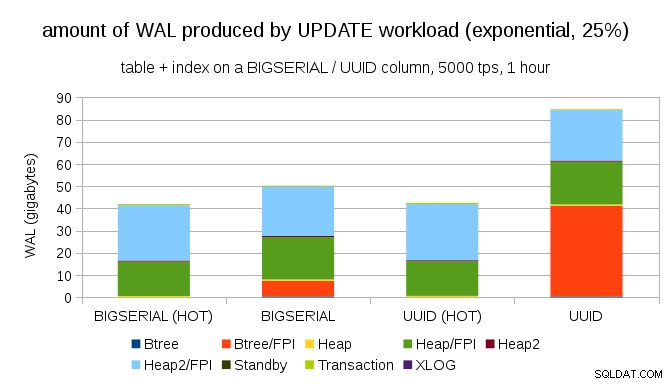
Afortunadamente, pgbench admite distribuciones no uniformes y, por ejemplo, con una distribución exponencial que toca el 1 % del subconjunto de datos ~25 % del tiempo, el gráfico se ve así:
Y después de hacer que la distribución sea aún más sesgada, tocando el subconjunto del 1% ~75% del tiempo:
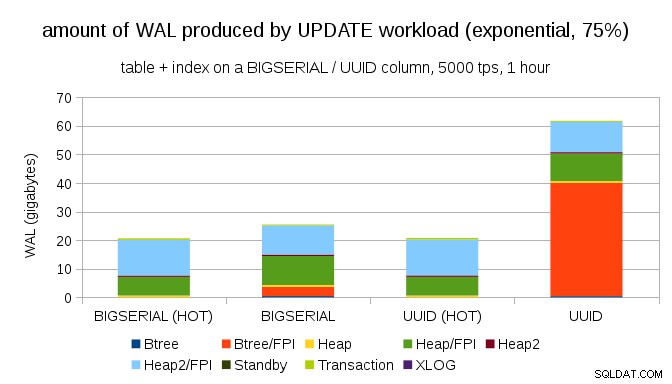
Esto nuevamente muestra la gran diferencia que puede hacer la elección de los tipos de datos, y también la importancia de ajustar las actualizaciones HOT.
Páginas de 8kB y 4kB
Una pregunta interesante es cuánto tráfico WAL podríamos ahorrar usando páginas más pequeñas en PostgreSQL (que requiere compilar un paquete personalizado). En el mejor de los casos, podría ahorrar hasta un 50 % WAL, gracias al registro de solo 4 kB en lugar de páginas de 8 kB. Para la carga de trabajo con ACTUALIZACIONES uniformemente distribuidas, se ve así:
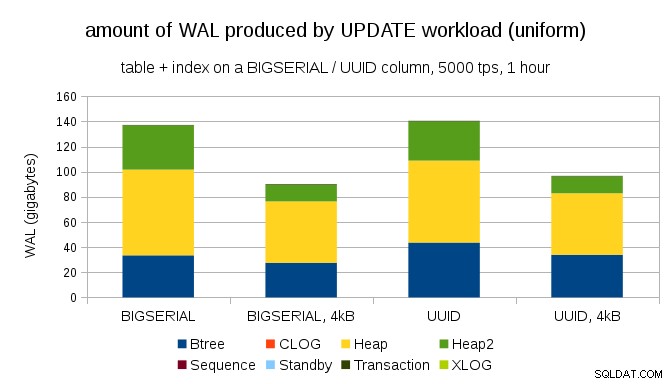
Por lo tanto, el ahorro no es exactamente del 50 %, pero la reducción de ~140 GB a ~90 GB sigue siendo bastante significativa.
¿Todavía necesitamos escrituras de página completa?
Puede parecer ridículo después de explicar el peligro de las escrituras parciales, pero tal vez deshabilitar las escrituras de página completa podría ser una opción viable, al menos en algunos casos.
En primer lugar, me pregunto si los sistemas de archivos Linux modernos siguen siendo vulnerables a las escrituras parciales. El parámetro se introdujo en PostgreSQL 8.1 lanzado en 2005, por lo que quizás algunas de las muchas mejoras del sistema de archivos introducidas desde entonces hacen que esto no sea un problema. Probablemente no sea universal para cargas de trabajo arbitrarias, pero tal vez sería suficiente asumir alguna condición adicional (por ejemplo, usar un tamaño de página de 4kB en PostgreSQL). Además, PostgreSQL nunca sobrescribe solo un subconjunto de la página de 8kB:siempre se escribe toda la página.
He realizado muchas pruebas recientemente para intentar activar una escritura parcial y aún no he logrado causar un solo caso. Por supuesto, eso no es realmente una prueba de que el problema no existe. Pero incluso si sigue siendo un problema, las sumas de verificación de datos pueden ser una protección suficiente (no solucionarán el problema, pero al menos le informarán que hay una página rota).
En segundo lugar, muchos sistemas hoy en día dependen de la transmisión de réplicas de replicación:en lugar de esperar a que el servidor se reinicie después de un problema de hardware (que puede llevar mucho tiempo) y luego pasar más tiempo realizando la recuperación, los sistemas simplemente cambian a un modo de espera activo. Si se elimina la base de datos en el principal fallido (y luego se clona desde el nuevo principal), las escrituras parciales no son un problema.
Pero supongo que si empezáramos a recomendar eso, entonces “¡No sé cómo se corrompieron los datos, acabo de configurar full_page_writes=off en los sistemas!” se convertiría en una de las oraciones más comunes justo antes de la muerte para los DBA (junto con "He visto esta serpiente en reddit, no es venenosa").
Resumen
No hay mucho que pueda hacer para ajustar las escrituras de página completa directamente. Para la mayoría de las cargas de trabajo, la mayoría de las escrituras de página completa ocurren justo después de un punto de control y luego desaparecen hasta el siguiente punto de control. Por lo tanto, es importante ajustar los puntos de control para que no sucedan con demasiada frecuencia.
Algunas decisiones a nivel de aplicación pueden aumentar la aleatoriedad de las escrituras en tablas e índices; por ejemplo, los valores de UUID son inherentemente aleatorios, lo que convierte incluso la carga de trabajo INSERT simple en actualizaciones de índice aleatorias. El esquema utilizado en los ejemplos fue bastante trivial; en la práctica, habrá índices secundarios, claves externas, etc. Pero el uso interno de claves primarias BIGSERIAL (y mantener el UUID como claves sustitutas) al menos reduciría la amplificación de escritura.
Estoy realmente interesado en la discusión sobre la necesidad de escrituras de página completa en los kernels/sistemas de archivos actuales. Lamentablemente, no he encontrado muchos recursos, así que si tienes información relevante, házmelo saber.