Aunque en el futuro la mayoría de los servidores de bases de datos (particularmente aquellos que manejan cargas de trabajo similares a OLTP) usarán un almacenamiento basado en flash, todavía no hemos llegado allí:el almacenamiento flash sigue siendo considerablemente más costoso que los discos duros tradicionales, y muchos sistemas usan una combinación de unidades SSD y HDD. Sin embargo, eso significa que debemos decidir cómo dividir la base de datos:qué debe ir al disco duro giratorio y qué es un buen candidato para el almacenamiento flash que es más costoso pero mucho mejor en el manejo de E/S aleatorias.
Hay soluciones que intentan manejar esto automáticamente a nivel de almacenamiento utilizando automáticamente SSD como caché, manteniendo automáticamente la parte activa de los datos en SSD. Los dispositivos de almacenamiento / SAN a menudo hacen esto internamente, hay unidades híbridas SATA / SAS con HDD grande y SSD pequeño en un solo paquete y, por supuesto, hay soluciones para hacer esto directamente en el host; por ejemplo, hay dm-cache en Linux, LVM también obtuvo esa capacidad (construida sobre dm-cache) en 2014 y, por supuesto, ZFS tiene L2ARC.
Pero ignoremos todas esas opciones automáticas y digamos que tenemos dos dispositivos conectados directamente al sistema, uno basado en HDD y el otro basado en flash. ¿Cómo debería dividir la base de datos para obtener el mayor beneficio del costoso flash? Un patrón que se usa comúnmente es hacer esto por tipo de objeto, particularmente tablas versus índices. Lo cual tiene sentido en general, pero a menudo vemos personas que colocan índices en el almacenamiento SSD, ya que los índices están asociados con E/S aleatorias. Si bien esto puede parecer razonable, resulta que es exactamente lo contrario de lo que debería estar haciendo.
Déjame mostrarte un punto de referencia...
Permítanme demostrar esto en un sistema con almacenamiento HDD (RAID10 construido a partir de 4 unidades SAS de 10k) y un solo dispositivo SSD (Intel S3700). El sistema tiene 16 GB de RAM, así que usemos pgbench con escalas 300 (=4,5 GB) y 3000 (=45 GB), es decir, uno que se ajuste fácilmente a la RAM y un múltiplo de RAM. Luego, coloquemos tablas e índices en diferentes sistemas de almacenamiento (usando tablespaces) y midamos el rendimiento. El clúster de la base de datos estaba razonablemente configurado (búferes compartidos, límites WAL, etc.) con respecto a los recursos de hardware. El WAL se colocó en un dispositivo SSD separado, conectado a un controlador RAID compartido con las unidades SAS.
En el conjunto de datos pequeño (4,5 GB), los resultados se ven así (observe que el eje Y comienza en 3000 tps):
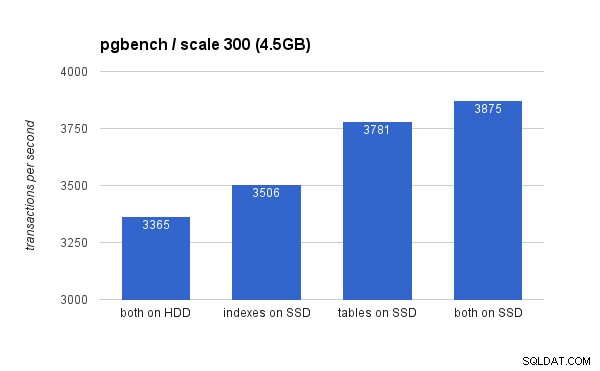
Claramente, colocar los índices en SSD brinda un beneficio menor en comparación con el uso de SSD para tablas. Si bien el conjunto de datos cabe fácilmente en la RAM, los cambios deben escribirse eventualmente en el disco, y aunque el controlador RAID tiene un caché de escritura, en realidad no puede competir con el almacenamiento flash. Los nuevos controladores RAID probablemente funcionarían un poco mejor, pero también lo harían las nuevas unidades SSD.
En el conjunto de datos grande, las diferencias son mucho más significativas (esta vez el eje Y comienza en 0):
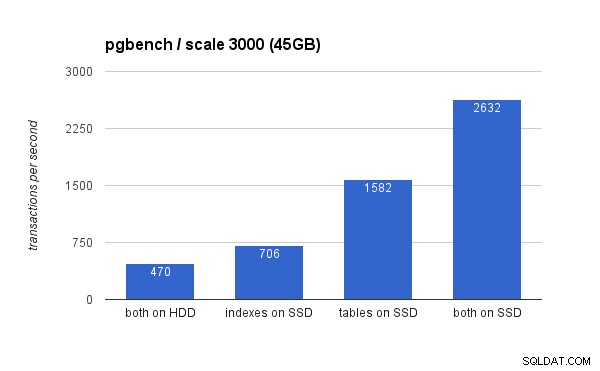
Colocar los índices en SSD da como resultado una ganancia de rendimiento significativa (casi un 50 %, tomando el almacenamiento HDD como base), pero mover las tablas a la SSD fácilmente supera eso al ganar más del 200 %. Por supuesto, si coloca tablas e índices en SSD, mejorará aún más el rendimiento, pero si pudiera hacerlo, no necesita preocuparse por los otros casos.
¿Pero por qué?
Obtener un mejor rendimiento al colocar tablas en SSD puede parecer un poco contrario a la intuición, entonces, ¿por qué se comporta así? Bueno, probablemente sea una combinación de varios factores:
- los índices suelen ser mucho más pequeños que las tablas y, por lo tanto, caben en la memoria más fácilmente
- las páginas en niveles de índices (en el árbol) suelen estar bastante calientes y, por lo tanto, permanecen en la memoria
- al escanear e indexar, gran parte de la E/S real es de naturaleza secuencial (particularmente para páginas hoja)
La consecuencia de esto es que una sorprendente cantidad de E/S contra índices no ocurre en absoluto (gracias al almacenamiento en caché) o es secuencial. Por otro lado, los índices son una gran fuente de E/S aleatorias contra las tablas.
Sin embargo, es más complicado...
Por supuesto, este fue solo un ejemplo simple, y las conclusiones pueden ser diferentes para cargas de trabajo sustancialmente diferentes, por ejemplo. Del mismo modo, dado que los SSD son más caros, los sistemas tienden a tener más espacio en disco en las unidades HDD que en las unidades SSD, por lo que es posible que las tablas no quepan en el SSD mientras que los índices sí. En esos casos, es necesaria una ubicación más elaborada, por ejemplo, teniendo en cuenta no solo el tipo de objeto, sino también la frecuencia con la que se usa (y solo moviendo las tablas más utilizadas a SSD), o incluso subconjuntos de tablas (por ejemplo, moviendo gradualmente las tablas antiguas). datos de SSD a HDD).



