Como habrá notado en mi blog anterior, los últimos meses estuvieron ocupados en actualizar Postgres-XL con la última versión 9.5 de PostgreSQL. Una vez que tuvimos una versión razonablemente estable de Postgres-XL 9.5, cambiamos nuestra atención para medir el rendimiento de esta nueva versión de Postgres-XL. Nuestra elección del punto de referencia está influenciada en gran medida por el trabajo en curso en el proyecto AXLE, financiado por la Unión Europea bajo el acuerdo de subvención 318633. Dado que estamos utilizando TPC BENCHMARK™ H para medir el rendimiento de todos los demás trabajos realizados en este proyecto, decidimos use el mismo punto de referencia para evaluar Postgres-XL. También se adapta a Postgres-XL porque TPC-H intenta medir las cargas de trabajo OLAP, algo que Postgres-XL debería hacer bien.
1. Configuración del clúster de Postgres-XL
Una vez que se decidió el punto de referencia, otro gran desafío fue encontrar los recursos adecuados para las pruebas. No teníamos acceso a un gran grupo de máquinas físicas. Así que hicimos lo que la mayoría haría. Decidimos utilizar Amazon AWS para configurar el clúster de Postgres-XL. AWS ofrece una amplia gama de instancias, y cada tipo de instancia ofrece una capacidad de procesamiento o de E/S diferente.
Esta página en AWS muestra varios tipos de instancias disponibles, recursos disponibles y sus precios para diferentes regiones. Debe tenerse en cuenta que los precios y la disponibilidad pueden variar de una región a otra, por lo que es importante que compruebe todas las regiones. Dado que Postgres-XL requiere baja latencia y alto rendimiento entre sus componentes, también es importante crear instancias de todas las instancias en la misma región. Para nuestro TPC-H de 3 TB, decidimos optar por un clúster de 16 datos de instancias i2.xlarge de AWS. Estas instancias tienen 4 vCPU, 30 GB de RAM y 800 GB de SSD cada una, almacenamiento suficiente para mantener todas las tablas distribuidas, las tablas replicadas (que ocupan más espacio a medida que aumenta el tamaño del clúster), los índices en ellas y todavía dejan suficiente espacio libre. en tablespace temporal para CREATE INDEX y otras consultas.
2. Configuración de puntos de referencia
2.1 TPC Benchmark™ H
El benchmark contiene 22 consultas con el propósito de examinar grandes volúmenes de datos, ejecutar consultas con un alto grado de complejidad y dar respuestas a preguntas comerciales críticas. Nos gustaría señalar que la especificación completa de TPC Benchmark™ H se ocupa de una variedad de pruebas, como carga, potencia y rendimiento pruebas Para nuestras pruebas, solo hemos ejecutado consultas individuales y no el conjunto de pruebas completo. TPC Benchmark™ H se compone de un conjunto de consultas comerciales diseñadas para ejercitar las funcionalidades del sistema de una manera representativa de aplicaciones complejas de análisis comercial. A estas consultas se les ha dado un contexto realista, representando la actividad de un proveedor mayorista para ayudar al lector a relacionarse intuitivamente con los componentes del benchmark.
2.2 Entidades, relaciones y características de la base de datos
Los componentes de la base de datos TPC-H están definidos para constar de ocho tablas separadas e individuales (las tablas base). Las relaciones entre las columnas de estas tablas se ilustran en el siguiente diagrama. 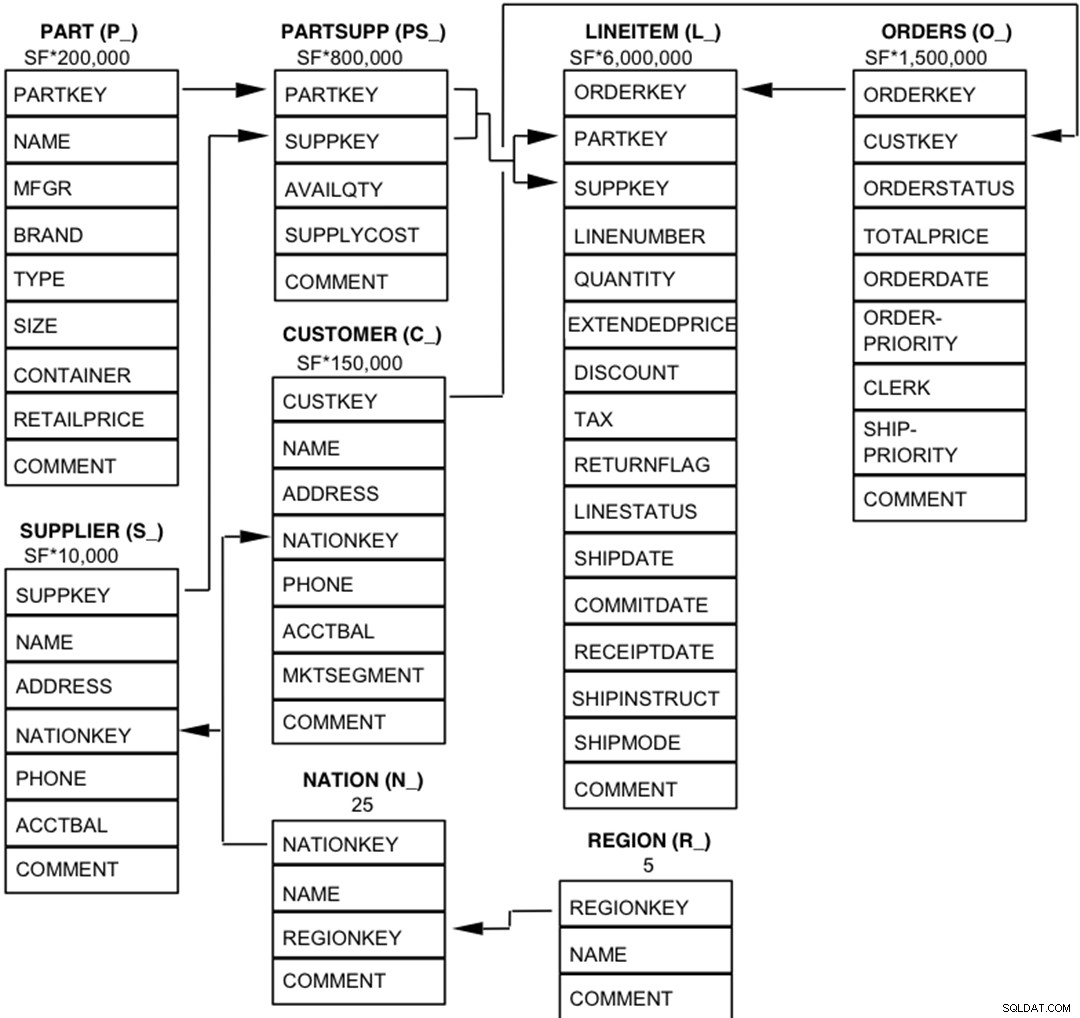 Leyenda :
Leyenda :
- Los paréntesis que siguen a cada nombre de tabla contienen el prefijo de los nombres de las columnas de esa tabla;
- Las flechas apuntan en la dirección de las relaciones de uno a muchos entre tablas
- El número/fórmula debajo de cada nombre de tabla representa la cardinalidad (número de filas) de la tabla. Algunos son factorizados por SF, el factor de escala, para obtener el tamaño de base de datos elegido. La cardinalidad de la tabla LINEITEM es aproximada
2.3 Distribución de datos para Postgres-XL
Analizamos las 22 consultas en el punto de referencia y se nos ocurrió la siguiente estrategia de distribución de datos para varias tablas en el punto de referencia.
| Nombre de la tabla | Estrategia de distribución |
| ARTÍCULO DE LÍNEA | HASH (l_orderkey) |
| PEDIDOS | HASH (o_orderkey) |
| PARTE | HASH (p_partkey) |
| PARTS SUPP | HASH (ps_partkey) |
| CLIENTE | REPLICADO |
| PROVEEDOR | REPLICADO |
| NACIÓN | REPLICADO |
| REGIÓN | REPLICADO |
Tenga en cuenta que LINEITEM y ORDERS, que son las tablas más grandes en el punto de referencia, a menudo se unen en ORDERKEY. Por lo tanto, tiene mucho sentido colocar estas tablas en ORDERKEY. De manera similar, PART y PARTSUPP se unen con frecuencia en PARTKEY y, por lo tanto, se colocan en la columna PARTKEY. El resto de las tablas se replican para garantizar que se puedan unir localmente, cuando sea necesario.
3. Resultados de referencia
3.1 Prueba de carga
Comparamos los resultados obtenidos al ejecutar una prueba de carga TPC-H de 3 TB en PostgreSQL 9.6 con el clúster Postgres-XL de 16 nodos. Los siguientes gráficos demuestran las características de rendimiento de Postgres-XL.
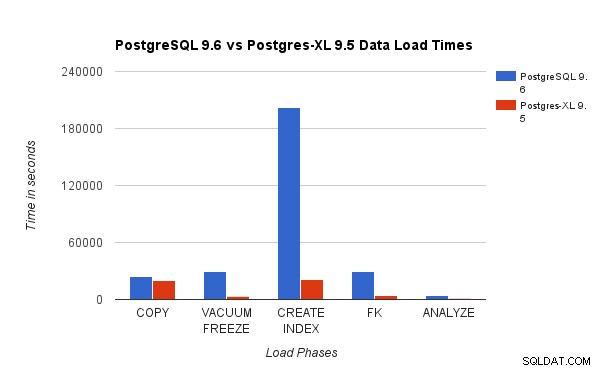 El gráfico anterior muestra el tiempo necesario para completar varias fases de una prueba de carga con PostgreSQL y Postgres-XL. Como se ve, Postgres-XL funciona un poco mejor para COPY y mucho mejor para todos los demás casos. Nota :Observamos que el coordinador requiere mucha potencia de cómputo durante la fase COPY, especialmente cuando se ejecutan más de un flujo COPY al mismo tiempo. Para abordar eso, el coordinador se ejecutó en una instancia de AWS optimizada para computación con 16 vCPU. Alternativamente, también podríamos haber ejecutado múltiples coordinadores y distribuir la carga de cómputo entre ellos.
El gráfico anterior muestra el tiempo necesario para completar varias fases de una prueba de carga con PostgreSQL y Postgres-XL. Como se ve, Postgres-XL funciona un poco mejor para COPY y mucho mejor para todos los demás casos. Nota :Observamos que el coordinador requiere mucha potencia de cómputo durante la fase COPY, especialmente cuando se ejecutan más de un flujo COPY al mismo tiempo. Para abordar eso, el coordinador se ejecutó en una instancia de AWS optimizada para computación con 16 vCPU. Alternativamente, también podríamos haber ejecutado múltiples coordinadores y distribuir la carga de cómputo entre ellos.
3.2 Prueba de potencia
También comparamos los tiempos de ejecución de consultas para el punto de referencia de 3 TB en PostgreSQL 9.6 y Postgres-XL 9.5. El siguiente gráfico muestra las características de rendimiento de la ejecución de consultas en las dos configuraciones.
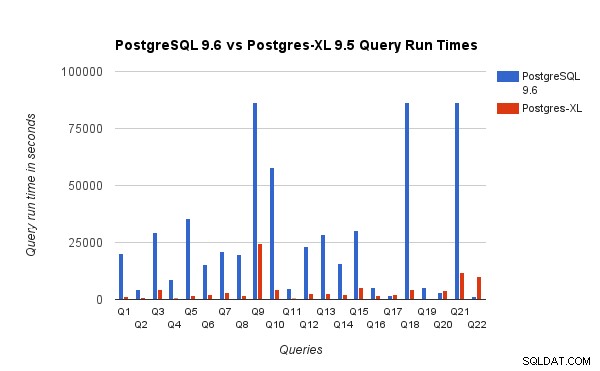 Observamos que, en promedio, las consultas se ejecutaron aproximadamente 6,4 veces más rápido en Postgres-XL y al menos el 25 % de las consultas mostraron una mejora casi lineal en el rendimiento, en otras palabras, se desempeñaron casi 16 veces más rápido en este clúster Postgres-XL de 16 nodos. Además, al menos el 50% de las consultas mostraron una mejora de 10 veces en el rendimiento. Analizamos más a fondo el rendimiento de las consultas y llegamos a la conclusión de que las consultas que están bien divididas en todos los nodos de datos disponibles, de modo que hay un intercambio mínimo de datos entre nodos y sin llamadas de ejecución remota repetidas, escalan muy bien en Postgres-XL. Estas consultas suelen tener un nodo Exploración de subconsultas remotas en la parte superior y el subárbol debajo del nodo se ejecuta en uno o más nodos en paralelo. También es común tener algunos otros nodos, como un nodo Límite o un nodo Agregado encima del nodo Exploración de subconsultas remotas. Incluso tales consultas funcionan muy bien en Postgres-XL. La consulta Q1 es un ejemplo de una consulta que debería escalar muy bien con Postgres-XL. Por otro lado, las consultas que requieren mucho intercambio de tuplas entre datanode-datanode y/o coordinador-datanode pueden no funcionar bien en Postgres-XL. Del mismo modo, las consultas que requieren muchas conexiones entre nodos también pueden mostrar un rendimiento deficiente. Por ejemplo, notará que el rendimiento de Q22 es malo en comparación con un servidor PostgreSQL de un solo nodo. Cuando analizamos el plan de consulta para Q22, observamos que hay tres niveles de nodos de exploración de subconsultas remotas anidados en el plan de consulta, donde cada nodo abre la misma cantidad de conexiones a los nodos de datos. Además, Nest Loop Anti Join tiene una relación interna con un nodo de escaneo de subconsulta remota de nivel superior y, por lo tanto, para cada tupla de la relación externa tiene que ejecutar una subconsulta remota. Esto da como resultado un rendimiento deficiente de la ejecución de consultas.
Observamos que, en promedio, las consultas se ejecutaron aproximadamente 6,4 veces más rápido en Postgres-XL y al menos el 25 % de las consultas mostraron una mejora casi lineal en el rendimiento, en otras palabras, se desempeñaron casi 16 veces más rápido en este clúster Postgres-XL de 16 nodos. Además, al menos el 50% de las consultas mostraron una mejora de 10 veces en el rendimiento. Analizamos más a fondo el rendimiento de las consultas y llegamos a la conclusión de que las consultas que están bien divididas en todos los nodos de datos disponibles, de modo que hay un intercambio mínimo de datos entre nodos y sin llamadas de ejecución remota repetidas, escalan muy bien en Postgres-XL. Estas consultas suelen tener un nodo Exploración de subconsultas remotas en la parte superior y el subárbol debajo del nodo se ejecuta en uno o más nodos en paralelo. También es común tener algunos otros nodos, como un nodo Límite o un nodo Agregado encima del nodo Exploración de subconsultas remotas. Incluso tales consultas funcionan muy bien en Postgres-XL. La consulta Q1 es un ejemplo de una consulta que debería escalar muy bien con Postgres-XL. Por otro lado, las consultas que requieren mucho intercambio de tuplas entre datanode-datanode y/o coordinador-datanode pueden no funcionar bien en Postgres-XL. Del mismo modo, las consultas que requieren muchas conexiones entre nodos también pueden mostrar un rendimiento deficiente. Por ejemplo, notará que el rendimiento de Q22 es malo en comparación con un servidor PostgreSQL de un solo nodo. Cuando analizamos el plan de consulta para Q22, observamos que hay tres niveles de nodos de exploración de subconsultas remotas anidados en el plan de consulta, donde cada nodo abre la misma cantidad de conexiones a los nodos de datos. Además, Nest Loop Anti Join tiene una relación interna con un nodo de escaneo de subconsulta remota de nivel superior y, por lo tanto, para cada tupla de la relación externa tiene que ejecutar una subconsulta remota. Esto da como resultado un rendimiento deficiente de la ejecución de consultas.
4. Algunas lecciones de AWS
Durante la evaluación comparativa de Postgres-XL, aprendimos algunas lecciones sobre el uso de AWS. Pensamos que serán útiles para cualquier persona que quiera usar/probar Postgres-XL en AWS.
- AWS ofrece varios tipos diferentes de instancias. Debe evaluar cuidadosamente su carga de trabajo y la cantidad de almacenamiento requerida antes de elegir un tipo de instancia específico.
- La mayoría de las instancias con almacenamiento optimizado tienen discos efímeros adjuntos. No necesita pagar nada adicional por esos discos, están conectados a la instancia y, a menudo, funcionan mejor que EBS. Pero debe montarlos explícitamente para poder usarlos. Sin embargo, tenga en cuenta que los datos almacenados en estos discos no son permanentes y se eliminarán si se detiene la instancia. Así que asegúrese de estar preparado para manejar esa situación. Dado que usábamos AWS principalmente para la evaluación comparativa, decidimos usar estos discos efímeros.
- Si utiliza EBS, asegúrese de elegir las IOPS provisionadas adecuadas. Un valor demasiado bajo provocará una E/S muy lenta, pero un valor muy alto puede aumentar sustancialmente su factura de AWS, especialmente cuando se trata de una gran cantidad de nodos.
- Asegúrese de iniciar las instancias en la misma zona para reducir la latencia y mejorar el rendimiento de las conexiones entre ellas.
- Asegúrese de configurar las instancias para que utilicen una red privada para comunicarse entre sí.
- Observe las instancias puntuales. Son relativamente más baratos. Dado que AWS puede terminar instancias puntuales a voluntad, por ejemplo, si el precio puntual supera el precio de oferta máximo, prepárese para ello. Postgres-XL puede volverse parcial o completamente inutilizable según los nodos que se terminen. AWS admite un concepto de launch_group. Si se agrupan varias instancias en el mismo launch_group, si AWS decide cancelar una instancia, se cancelarán todas las instancias.
5. Conclusión
Podemos demostrar, a través de varios puntos de referencia, que Postgres-XL puede escalar muy bien para un gran conjunto de consultas complejas del mundo real. Estos puntos de referencia nos ayudan a demostrar la capacidad de Postgres-XL como una solución eficaz para cargas de trabajo OLAP. Nuestros experimentos también muestran que hay algunos problemas de rendimiento con Postgres-XL, especialmente para clústeres muy grandes y cuando el planificador elige mal un plan. También observamos que cuando hay una gran cantidad de conexiones simultáneas a un nodo de datos, el rendimiento empeora. Seguiremos trabajando en estos problemas de rendimiento. También nos gustaría probar la capacidad de Postgres-XL como solución OLTP mediante el uso de cargas de trabajo adecuadas.