Hace un par de años (en pgconf.eu 2014 en Madrid) presenté una charla llamada “Performance Archaeology” que mostraba cómo cambió el rendimiento en las últimas versiones de PostgreSQL. Hice esa charla porque creo que la visión a largo plazo es interesante y puede darnos ideas que pueden ser muy valiosas. Para las personas que realmente trabajan con código PostgreSQL como yo, es una guía útil para el desarrollo futuro, y para los usuarios de PostgreSQL puede ayudar a evaluar las actualizaciones.
Así que decidí repetir este ejercicio y escribir un par de publicaciones de blog analizando el rendimiento de varias versiones de PostgreSQL. En la charla de 2014 comencé con PostgreSQL 7.4, que en ese momento tenía unos 10 años (lanzado en 2003). Esta vez comenzaré con PostgreSQL 8.3, que tiene aproximadamente 12 años.
¿Por qué no empezar de nuevo con PostgreSQL 7.4? Hay tres razones principales por las que decidí comenzar con PostgreSQL 8.3. En primer lugar, la pereza general. Cuanto más antigua sea la versión, más difícil puede ser construir usando las versiones actuales del compilador, etc. En segundo lugar, se necesita tiempo para ejecutar los puntos de referencia adecuados, especialmente con grandes cantidades de datos, por lo que agregar una sola versión principal puede agregar fácilmente un par de días de tiempo de máquina. Simplemente no parecía valer la pena. Y, por último, 8.3 introdujo una serie de cambios importantes:mejoras en el vacío automático (habilitado de forma predeterminada, procesos de trabajo simultáneos, …), búsqueda de texto completo integrada en el núcleo, puntos de control distribuidos, etc. Así que creo que tiene mucho sentido comenzar con PostgreSQL 8.3. Que se lanzó hace unos 12 años, por lo que esta comparación en realidad cubrirá un período de tiempo más largo.
Decidí comparar tres tipos básicos de carga de trabajo:OLTP, análisis y búsqueda de texto completo. Creo que OLTP y el análisis son opciones bastante obvias, ya que la mayoría de las aplicaciones son una combinación de esos dos tipos básicos. La búsqueda de texto completo me permite demostrar mejoras en tipos especiales de índices, que también se utilizan para indexar tipos de datos populares como JSONB, tipos utilizados por PostGIS, etc.
¿Por qué hacer esto?
¿Realmente vale la pena el esfuerzo? Después de todo, hacemos evaluaciones comparativas durante el desarrollo todo el tiempo para demostrar que un parche ayuda y/o que no causa regresiones, ¿verdad? El problema es que, por lo general, estos son solo puntos de referencia "parciales", que comparan dos compromisos particulares y, por lo general, con una selección bastante limitada de cargas de trabajo que creemos que pueden ser relevantes. Lo que tiene mucho sentido:simplemente no puede ejecutar una batería completa de cargas de trabajo para cada confirmación.
De vez en cuando (generalmente poco después del lanzamiento de una nueva versión principal de PostgreSQL), las personas realizan pruebas comparando la nueva versión con la anterior, lo cual es bueno y lo animo a ejecutar dichos puntos de referencia (ya sea algún tipo de punto de referencia estándar, o algo específico para su aplicación). Pero es difícil combinar estos resultados en una visión a más largo plazo, porque esas pruebas usan diferentes configuraciones y hardware (generalmente uno más reciente para la versión más nueva), y así sucesivamente. Por lo tanto, es difícil emitir juicios claros sobre los cambios en general.
Lo mismo se aplica al rendimiento de la aplicación, que es el "punto de referencia definitivo", por supuesto. Pero es posible que las personas no actualicen a todas las versiones principales (a veces pueden omitir un par de versiones, por ejemplo, de 9.5 a 12). Y cuando se actualizan, a menudo se combinan con actualizaciones de hardware, etc. Sin mencionar que las aplicaciones evolucionan con el tiempo (nuevas funciones, complejidad adicional), la cantidad de datos y el número de usuarios simultáneos crecen, etc.
Eso es lo que esta serie de blogs trata de mostrar:tendencias a largo plazo en el rendimiento de PostgreSQL para algunas cargas de trabajo básicas, para que nosotros, los desarrolladores, tengamos una sensación cálida y confusa sobre el buen trabajo realizado a lo largo de los años. Y para mostrarles a los usuarios que, aunque PostgreSQL es un producto maduro en este punto, todavía hay mejoras significativas en cada nueva versión principal.
No es mi objetivo utilizar estos puntos de referencia para compararlos con otros productos de bases de datos, ni producir resultados para cumplir con ninguna clasificación oficial (como la TPC-H). Mi objetivo es simplemente educarme como desarrollador de PostgreSQL, tal vez identificar e investigar algunos problemas y compartir los hallazgos con otros.
¿Comparación justa?
No creo que tales comparaciones de versiones lanzadas durante 12 años no puedan ser del todo justas, porque cualquier software se desarrolla en un contexto particular; el hardware es un buen ejemplo, para un sistema de base de datos. Si observa las máquinas que usaba hace 12 años, ¿cuántos núcleos tenían, cuánta RAM? ¿Qué tipo de almacenamiento usaron?
Un servidor típico de gama media en 2008 tenía entre 8 y 12 núcleos, 16 GB de RAM y un RAID con un par de unidades SAS. Un servidor de rango medio típico hoy en día puede tener un par de docenas de núcleos, cientos de GB de RAM y almacenamiento SSD.
El desarrollo de software está organizado por prioridad:siempre hay más tareas potenciales de las que tiene tiempo, por lo que debe elegir tareas con la mejor relación costo/beneficio para sus usuarios (especialmente aquellos que financian el proyecto, directa o indirectamente). Y en 2008, algunas optimizaciones probablemente aún no eran relevantes:la mayoría de las máquinas no tenían cantidades extremas de RAM, por lo que, por ejemplo, todavía no valía la pena optimizar para grandes búferes compartidos. Y muchos de los cuellos de botella de la CPU se vieron eclipsados por la E/S, porque la mayoría de las máquinas tenían un almacenamiento "oxidado".
Nota:Por supuesto, había clientes que usaban máquinas bastante grandes incluso en ese entonces. Algunos usaron Postgres comunitario con varios ajustes, otros decidieron ejecutar con una de las diversas bifurcaciones de Postgres con capacidades adicionales (por ejemplo, paralelismo masivo, consultas distribuidas, uso de FPGA, etc.). Y esto también influyó en el desarrollo de la comunidad, por supuesto.
A medida que las máquinas más grandes se hicieron más comunes a lo largo de los años, más personas podían permitirse máquinas con grandes cantidades de RAM y una gran cantidad de núcleos, cambiando la relación costo/beneficio. Los cuellos de botella se investigaron y solucionaron, lo que permitió que las versiones más nuevas funcionaran mejor.
Esto significa que un punto de referencia como este siempre es un poco injusto:favorecerá la versión más antigua o la más nueva, según la configuración (hardware, configuración). Sin embargo, he intentado seleccionar parámetros de hardware y configuración para que no sea tan malo para las versiones anteriores.
El punto que estoy tratando de hacer es que esto no significa que las versiones anteriores de PostgreSQL fueran una mierda:así es como funciona el desarrollo de software. Aborda los cuellos de botella que es probable que encuentren sus usuarios, no los cuellos de botella que podrían encontrar en 10 años.
Hardware
Prefiero hacer pruebas comparativas en hardware físico al que tengo acceso directo, porque eso me permite controlar todos los detalles, tengo acceso a todos los detalles, etc. Así que usé la máquina que tengo en nuestra oficina, nada lujoso, pero espero que sea lo suficientemente bueno para este propósito.
- 2x E5-2620 v4 (16 núcleos, 32 subprocesos)
- 64 GB de RAM
- SSD Intel Optane 900P de 280 GB NVMe (datos)
- 3 x 7.2k SATA RAID0 (tablespace temporal)
- núcleo 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
También he usado una segunda máquina, mucho más pequeña, con solo 4 núcleos y 8 GB de RAM, que generalmente muestra las mismas mejoras/regresiones, solo que menos pronunciadas.
pgbench
Como herramienta de evaluación comparativa, he utilizado el conocido pgbench, usando la versión más nueva (de PostgreSQL 13) para probar todas las versiones. Esto elimina el posible sesgo debido a las optimizaciones realizadas en pgbench a lo largo del tiempo, lo que hace que los resultados sean más comparables.
El punto de referencia prueba una serie de casos diferentes, variando una serie de parámetros, a saber:
escala
- pequeño:los datos caben en los búferes compartidos, lo que muestra problemas de bloqueo, etc.
- medio:datos más grandes que los búferes compartidos pero que caben en la RAM, generalmente vinculados a la CPU (o posiblemente E/S para cargas de trabajo de lectura y escritura)
- grande:datos más grandes que la RAM, principalmente con límite de E/S
modos
- solo lectura:pgbench -S
- lectura-escritura – pgbench -N
cuenta de clientes
- 1, 4, 8, 16, 32, 64, 128, 256
- el número de subprocesos de pgbench (-j) se modifica en consecuencia
Resultados
Bien, veamos los resultados. Primero presentaré los resultados del almacenamiento NVMe, luego mostraré algunos resultados interesantes usando el almacenamiento SATA RAID.
SSD NVMe / solo lectura
Para el pequeño conjunto de datos (que cabe completamente en los búferes compartidos), los resultados de solo lectura se ven así:
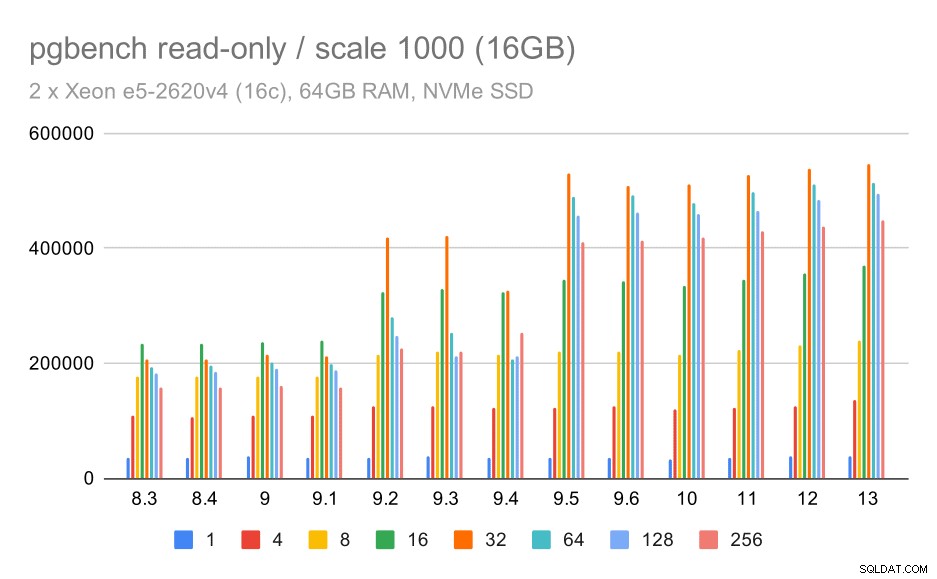
resultados de pgbench / solo lectura en un conjunto de datos pequeño (escala 100, es decir, 1,6 GB)
Claramente, hubo un aumento significativo del rendimiento en 9.2, que contenía una serie de mejoras de rendimiento, por ejemplo, la vía rápida para el bloqueo. El rendimiento de un solo cliente en realidad cae un poco:de 47 000 tps a solo unos 42 000 tps. Pero para un mayor número de clientes, la mejora en 9.2 es bastante clara.
resultados de pgbench / solo lectura en un conjunto de datos mediano (escala 1000, es decir, 16 GB)
Para el conjunto de datos mediano (que es más grande que los búferes compartidos pero aún cabe en la RAM) también parece haber alguna mejora en 9.2, aunque no tan clara como la anterior, seguida de una mejora mucho más clara en 9.5 probablemente gracias a las mejoras de escalabilidad de bloqueo .
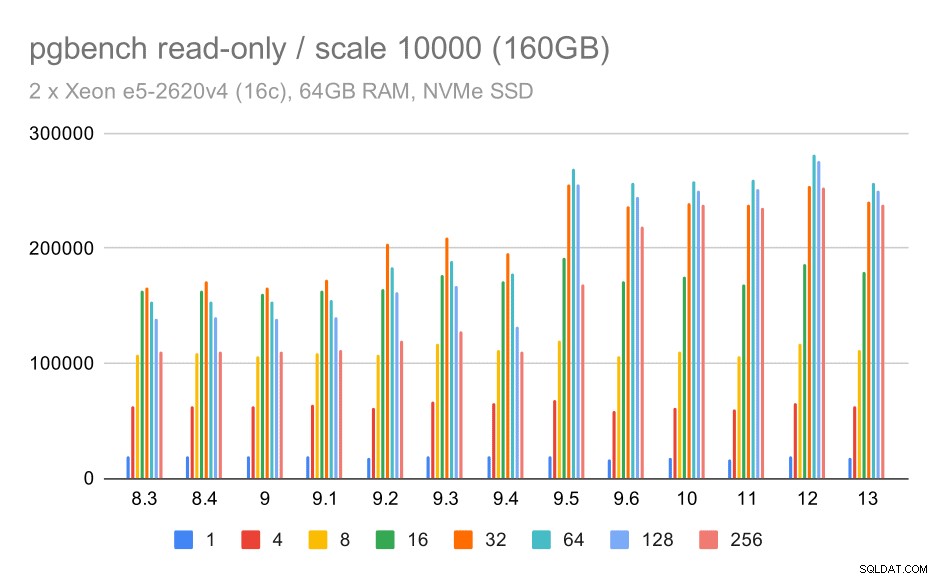
resultados de pgbench / solo lectura en un gran conjunto de datos (escala 10000, es decir, 160 GB)
En el conjunto de datos más grande, que se trata principalmente de la capacidad de utilizar el almacenamiento de manera eficiente, también hay algo de aceleración, muy probablemente gracias a las mejoras de 9.5 también.
SSD NVMe/lectura-escritura
Los resultados de lectura y escritura también muestran algunas mejoras, aunque no tan pronunciadas. En el pequeño conjunto de datos, los resultados se ven así:
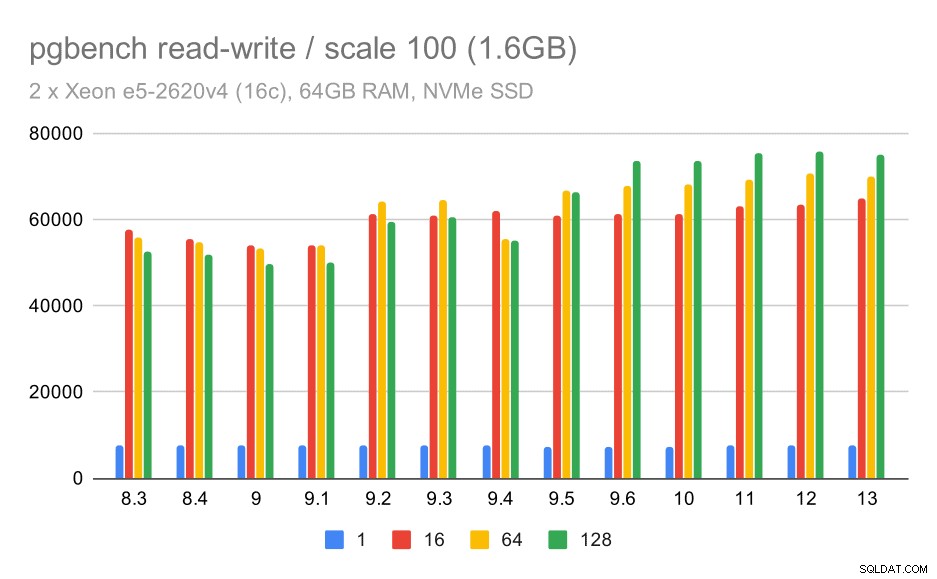
resultados de pgbench / lectura y escritura en un conjunto de datos pequeño (escala 100, es decir, 1,6 GB)
Entonces, una mejora modesta de alrededor de 52k a 75k tps con una cantidad suficiente de clientes.
Para el conjunto de datos mediano, la mejora es mucho más clara:de aproximadamente 27 000 a 63 000 tps, es decir, el rendimiento se duplica con creces.
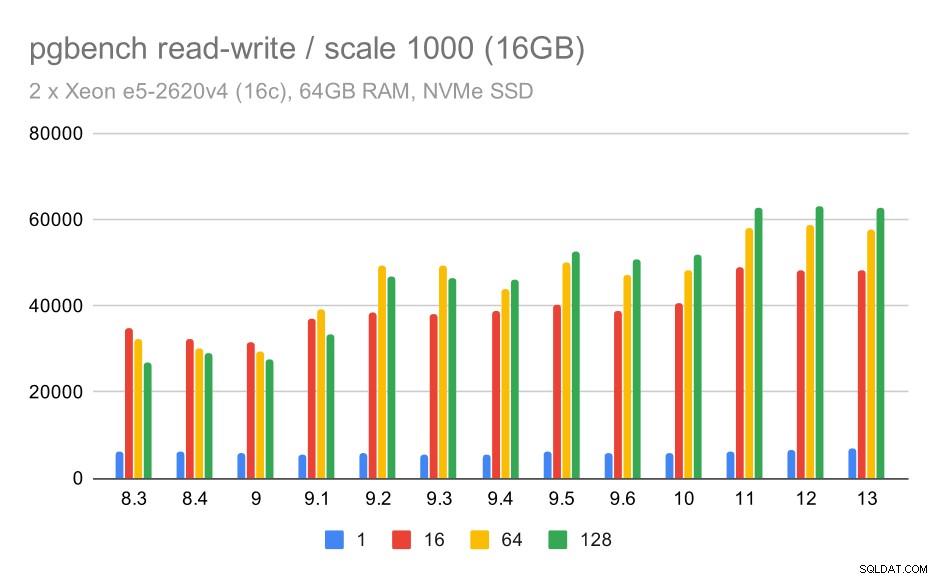
resultados de pgbench / lectura y escritura en un conjunto de datos mediano (escala 1000, es decir, 16 GB)
Para el conjunto de datos más grande, vemos una mejora general similar, pero parece haber cierta regresión entre 9,5 y 11.
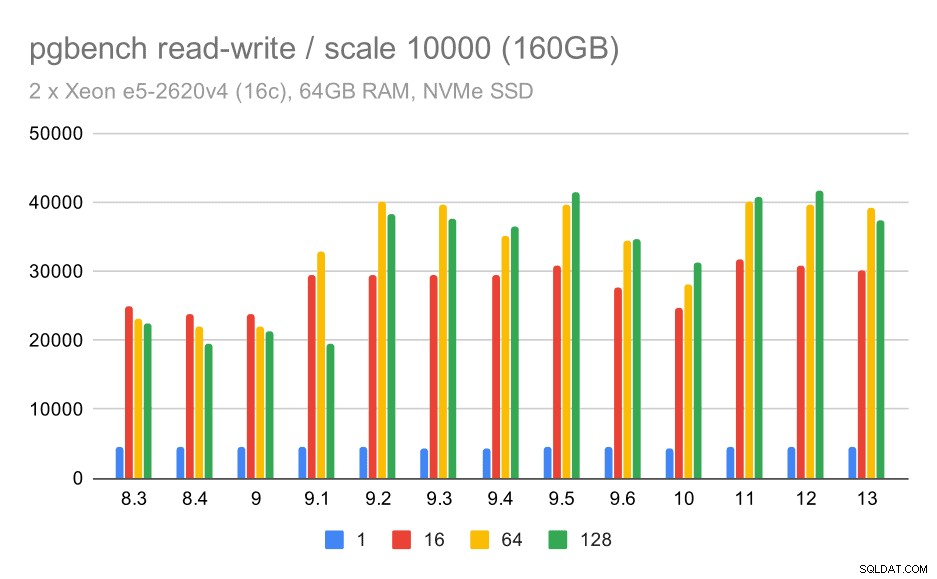
resultados de pgbench / lectura y escritura en un gran conjunto de datos (escala 10000, es decir, 160 GB)
SATA RAID / solo lectura
Para el almacenamiento SATA RAID, los resultados de solo lectura no son tan buenos. Podemos obviar los conjuntos de datos pequeños y medianos, para los cuales el sistema de almacenamiento es irrelevante. Para el gran conjunto de datos, el rendimiento es algo ruidoso, pero en realidad parece disminuir con el tiempo, especialmente desde PostgreSQL 9.6. No sé cuál es la razón de esto (nada en las notas de la versión 9.6 se destaca como un candidato claro), pero parece una especie de regresión.
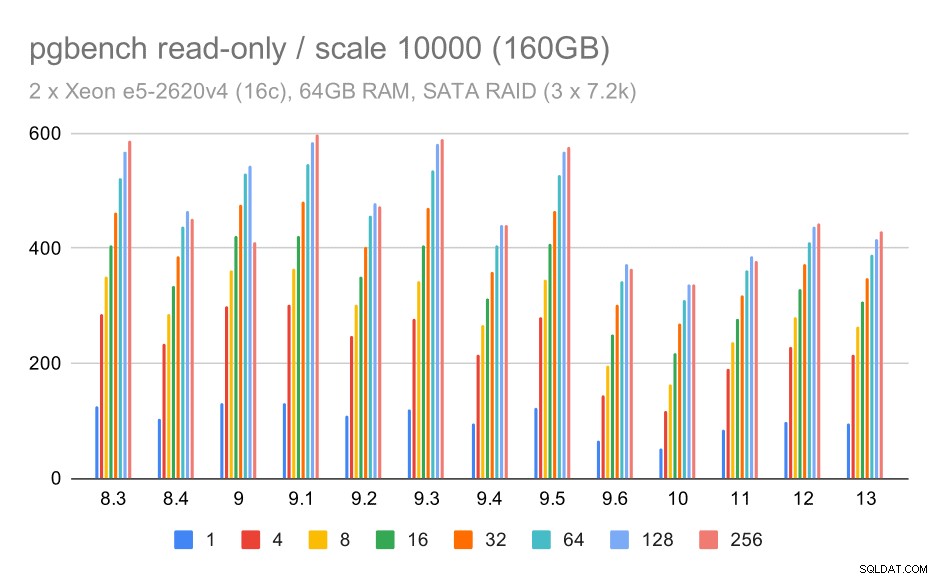
Resultados de pgbench en SATA RAID / solo lectura en un gran conjunto de datos (escala 10000, es decir, 160 GB)
SATA RAID / lectura-escritura
Sin embargo, el comportamiento de lectura y escritura parece mucho mejor. En el conjunto de datos pequeños, el rendimiento aumenta de aproximadamente 600 tps a más de 6000 tps. Apuesto a que esto se debe a las mejoras en la confirmación de grupo en 9.1 y 9.2.
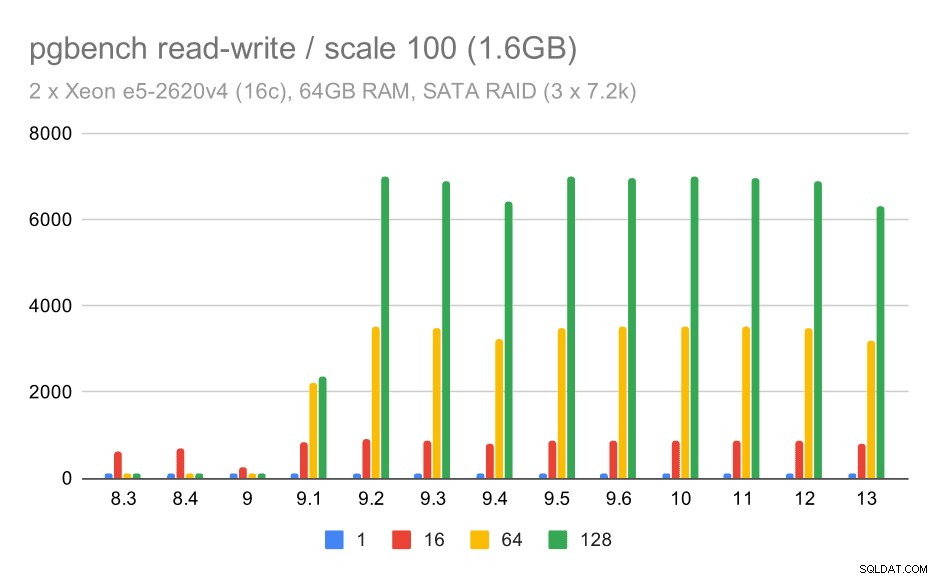
Resultados de pgbench en SATA RAID / lectura y escritura en un conjunto de datos pequeño (escala 100, es decir, 1,6 GB)
Para las escalas mediana y grande, podemos ver una mejora similar, pero más pequeña, porque el almacenamiento también necesita manejar las solicitudes de E/S para leer y escribir los bloques de datos. Para la escala media, solo necesitamos hacer las escrituras (ya que los datos caben en la RAM), para la escala grande también necesitamos hacer las lecturas, por lo que el rendimiento máximo es aún más bajo.
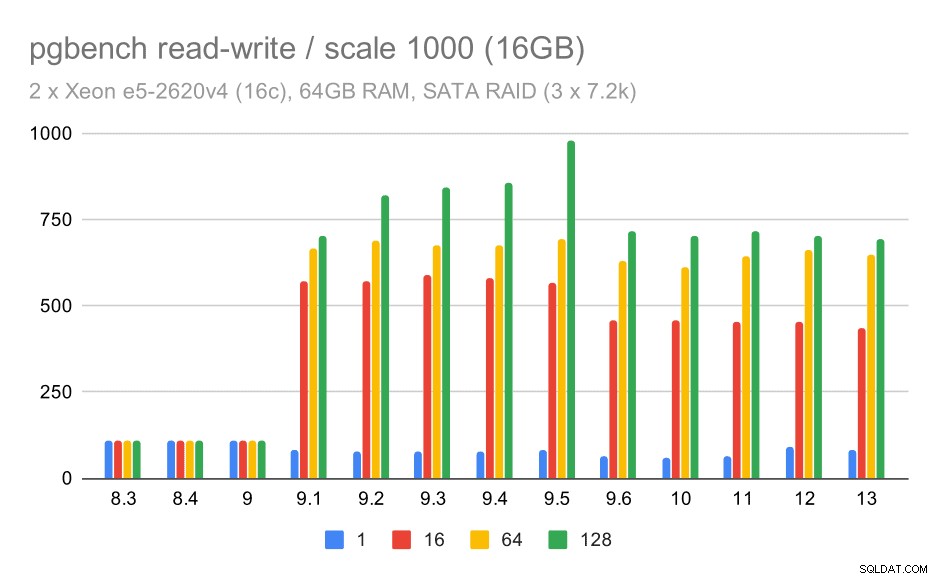
Resultados de pgbench en SATA RAID / lectura y escritura en un conjunto de datos mediano (escala 1000, es decir, 16 GB)
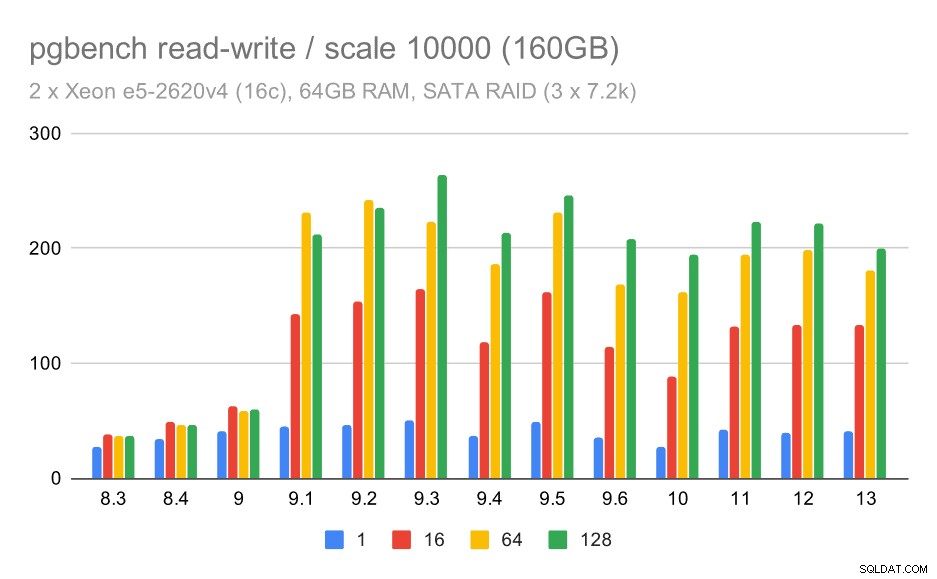
Resultados de pgbench en SATA RAID / lectura y escritura en un gran conjunto de datos (escala 10000, es decir, 160 GB)
Resumen y Futuro
Para resumir esto, para la configuración de NVMe, las conclusiones parecen ser bastante positivas. Para la carga de trabajo de solo lectura, hay una aceleración moderada en 9.2 y una aceleración significativa en 9.5, gracias a las optimizaciones de escalabilidad, mientras que para la carga de trabajo de lectura y escritura, el rendimiento mejoró aproximadamente 2 veces con el tiempo, en varias versiones/pasos.
Sin embargo, con la configuración SATA RAID, las conclusiones son un tanto mixtas. En el caso de la carga de trabajo de solo lectura, hay mucha variabilidad/ruido y una posible regresión en 9.6. Para la carga de trabajo de lectura y escritura, hay una aceleración masiva en 9.1 donde el rendimiento aumentó repentinamente de 100 tps a aproximadamente 600 tps.
¿Qué pasa con las mejoras en futuras versiones de PostgreSQL? No tengo una idea muy clara de cuál será la próxima gran mejora; sin embargo, estoy seguro de que a otros piratas informáticos de PostgreSQL se les ocurrirán ideas brillantes que harán las cosas más eficientes o permitirán aprovechar los recursos de hardware disponibles. El parche para mejorar la escalabilidad con muchas conexiones o el parche para agregar soporte para búferes WAL no volátiles son ejemplos de tales mejoras. Es posible que veamos algunas mejoras radicales en el almacenamiento de PostgreSQL (formato en disco más eficiente, uso de E/S directa, etc.), indexación, etc.