Bienvenido a la tercera y última parte de esta serie de blogs, que explora cómo evolucionó el rendimiento de PostgreSQL a lo largo de los años. La primera parte analizó las cargas de trabajo de OLTP, representadas por pruebas de pgbench. La segunda parte analizó las consultas analíticas/BI, usando un subconjunto del benchmark TPC-H tradicional (esencialmente una parte de la prueba de potencia).
Y esta parte final analiza la búsqueda de texto completo, es decir, la capacidad de indexar y buscar en grandes cantidades de datos de texto. La misma infraestructura (especialmente los índices) puede ser útil para indexar datos semiestructurados como documentos JSONB, etc., pero no es en eso en lo que se centra este punto de referencia.
Pero primero, veamos el historial de búsqueda de texto completo en PostgreSQL, que puede parecer una característica extraña para agregar a un RDBMS, tradicionalmente destinado a almacenar datos estructurados en filas y columnas.
La historia de la búsqueda de texto completo
Cuando Postgres fue de código abierto en 1996, no tenía nada que pudiéramos llamar búsqueda de texto completo. Pero las personas que comenzaron a usar Postgres querían realizar búsquedas inteligentes en documentos de texto, y las consultas LIKE no eran lo suficientemente buenas. Querían poder lematizar los términos usando diccionarios, ignorar las palabras vacías, ordenar los documentos coincidentes por relevancia, usar índices para ejecutar esas consultas y muchas otras cosas. Cosas que no puede hacer razonablemente con los operadores SQL tradicionales.
Afortunadamente, algunas de esas personas también eran desarrolladores, por lo que comenzaron a trabajar en esto, y pudieron, gracias a que PostgreSQL está disponible como código abierto en todo el mundo. Ha habido muchos contribuyentes a la búsqueda de texto completo a lo largo de los años, pero inicialmente este esfuerzo fue liderado por Oleg Bartunov y Teodor Sigaev, que se muestran en la siguiente foto. Ambos siguen siendo los principales contribuyentes de PostgreSQL y trabajan en la búsqueda de texto completo, la indexación, la compatibilidad con JSON y muchas otras funciones.

Teodor Sigaev y Oleg Bartunov
Inicialmente, la funcionalidad se desarrolló como un módulo "contrib" externo (hoy en día diríamos que es una extensión) llamado "tsearch", lanzado en 2002. Más tarde, tsearch2 lo dejó obsoleto, mejorando significativamente la función de muchas maneras, y en PostgreSQL. 8.3 (lanzado en 2008) esto se integró completamente en el núcleo de PostgreSQL (es decir, sin necesidad de instalar ninguna extensión, aunque las extensiones aún se proporcionaron para compatibilidad con versiones anteriores).
Hubo muchas mejoras desde entonces (y el trabajo continúa, por ejemplo, para admitir tipos de datos como JSONB, consultas usando jsonpath, etc.). pero estos complementos introdujeron la mayor parte de la funcionalidad de texto completo que tenemos ahora en PostgreSQL:diccionarios, indexación de texto completo y capacidades de consulta, etc.
El punto de referencia
A diferencia de los puntos de referencia de OLTP/TPC-H, no conozco ningún punto de referencia de texto completo que pueda considerarse "estándar de la industria" o diseñado para múltiples sistemas de bases de datos. La mayoría de los puntos de referencia que conozco están destinados a usarse con una sola base de datos/producto, y es difícil migrarlos de manera significativa, así que tuve que tomar una ruta diferente y escribir mi propio punto de referencia de texto completo.
Hace años escribí archie:un par de scripts de python que permiten descargar archivos de listas de correo de PostgreSQL y cargar los mensajes analizados en una base de datos de PostgreSQL que luego se puede indexar y buscar. La instantánea actual de todos los archivos tiene ~1 millón de filas y, después de cargarla en una base de datos, la tabla tiene aproximadamente 9,5 GB (sin contar los índices).
En cuanto a las consultas, probablemente podría generar algunas al azar, pero no estoy seguro de cuán realista sería. Afortunadamente, hace un par de años obtuve una muestra de 33k búsquedas reales del sitio web de PostgreSQL (es decir, cosas que la gente realmente buscaba en los archivos de la comunidad). Es poco probable que pueda obtener algo más realista/representativo.
La combinación de esas dos partes (conjunto de datos + consultas) parece un buen punto de referencia. Simplemente podemos cargar los datos y ejecutar las búsquedas con diferentes tipos de consultas de texto completo con diferentes tipos de índices.
Consultas
Hay varias formas de consultas de texto completo:la consulta puede simplemente seleccionar todas las filas coincidentes, puede clasificar los resultados (ordenarlos por relevancia), devolver solo un número pequeño o los resultados más relevantes, etc. Ejecuté el punto de referencia con varios tipos de consultas, pero en esta publicación presentaré los resultados de dos consultas simples que creo que representan bastante bien el comportamiento general.
- SELECCIONE id, asunto DESDE mensajes DONDE body_tsvector @@ $1
- SELECCIONE id, asunto DESDE mensajes DONDE body_tsvector @@ $1
ORDENAR POR ts_rank(body_tsvector, $1) DESC LIMIT 100
La primera consulta simplemente devuelve todas las filas coincidentes, mientras que la segunda devuelve los 100 resultados más relevantes (esto es algo que probablemente usaría para las búsquedas de los usuarios).
Experimenté con varios otros tipos de consultas, pero finalmente todas se comportaron de manera similar a uno de estos dos tipos de consultas.
Índices
Cada mensaje tiene dos partes principales en las que podemos buscar:asunto y cuerpo. Cada uno de ellos tiene una columna tsvector separada y se indexa por separado. Los asuntos de los mensajes son mucho más cortos que los cuerpos, por lo que los índices son naturalmente más pequeños.
PostgreSQL tiene dos tipos de índices útiles para la búsqueda de texto completo:GIN y GiST. Las principales diferencias se explican en los documentos, pero en resumen:
- Los índices GIN son más rápidos para las búsquedas
- Los índices de GiST tienen pérdidas, es decir, requieren una nueva verificación durante las búsquedas (y, por lo tanto, son más lentos)
Solíamos afirmar que los índices de GiST son más baratos de actualizar (especialmente con muchas sesiones simultáneas), pero esto se eliminó de la documentación hace algún tiempo debido a las mejoras en el código de indexación.
Este punto de referencia no prueba el comportamiento con las actualizaciones:simplemente carga la tabla sin los índices de texto completo, los crea de una sola vez y luego ejecuta las consultas de 33k en los datos. Eso significa que no puedo hacer ninguna declaración sobre cómo esos tipos de índices manejan las actualizaciones simultáneas basadas en este punto de referencia, pero creo que los cambios en la documentación reflejan varias mejoras recientes de GIN.
Esto también debería coincidir bastante bien con el caso de uso del archivo de la lista de correo, donde solo agregaríamos nuevos correos electrónicos de vez en cuando (pocas actualizaciones, casi sin simultaneidad de escritura). Pero si su aplicación realiza muchas actualizaciones simultáneas, deberá realizar una evaluación comparativa por su cuenta.
El hardware
Hice el benchmark en las mismas dos máquinas que antes, pero los resultados/conclusiones son casi idénticos, así que solo presentaré los números de la más pequeña, es decir,
- CPU i5-2500K (4 núcleos/hilos)
- 8 GB de RAM
- 6 SSD RAID0 de 100 GB
- núcleo 5.6.15, sistema de archivos ext4
Anteriormente mencioné que el conjunto de datos tiene casi 10 GB cuando se carga, por lo que es más grande que la RAM. Pero los índices siguen siendo más pequeños que la RAM, que es lo que importa para el punto de referencia.
Resultados
Bien, es hora de algunos números y gráficos. Presentaré resultados tanto para cargas de datos como para consultas, primero con índices GIN y luego con índices GiST.
GIN / carga de datos
La carga no es particularmente interesante, creo. En primer lugar, la mayor parte (la parte azul) no tiene nada que ver con el texto completo, porque ocurre antes de que se creen los dos índices. La mayor parte de este tiempo se dedica a analizar los mensajes, reconstruir los hilos de correo, mantener la lista de respuestas, etc. Parte de este código se implementa en disparadores PL/pgSQL, parte se implementa fuera de la base de datos. La única parte potencialmente relevante para el texto completo es la construcción de tsvectors, pero es imposible aislar el tiempo dedicado a eso.
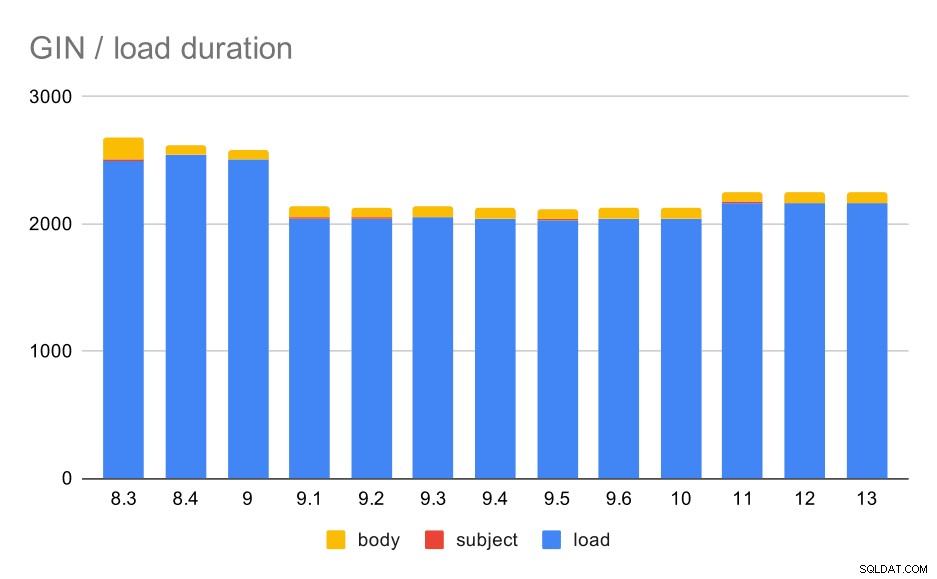
Operaciones de carga de datos con una tabla e índices GIN.
La siguiente tabla muestra los datos de origen de este gráfico:los valores son la duración en segundos. LOAD incluye el análisis de los archivos mbox (desde un script de Python), la inserción en una tabla y varias tareas adicionales (reconstrucción de hilos de correo electrónico, etc.). El ÍNDICE DE ASUNTO/CUERPO hace referencia a la creación de un índice GIN de texto completo en las columnas de asunto/cuerpo después de cargar los datos.
| LOAD | ÍNDICE DE MATERIA | ÍNDICE DEL CUERPO | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9.6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Claramente, el rendimiento es bastante estable:ha habido una mejora bastante significativa (aproximadamente un 20 %) entre 9.0 y 9.1. No estoy muy seguro de qué cambio podría ser responsable de esta mejora:nada en las notas de la versión 9.1 parece claramente relevante. También hay una clara mejora en la construcción de los índices GIN en 8.4, lo que reduce el tiempo a la mitad. Lo cual es bueno, por supuesto. Curiosamente, tampoco veo ningún elemento de notas de la versión obviamente relacionado con esto.
Sin embargo, ¿qué pasa con los tamaños de los índices GIN? Hay mucha más variabilidad, al menos hasta la versión 9.4, momento en el que el tamaño de los índices se reduce de ~1 GB a solo unos 670 MB (aproximadamente el 30 %).
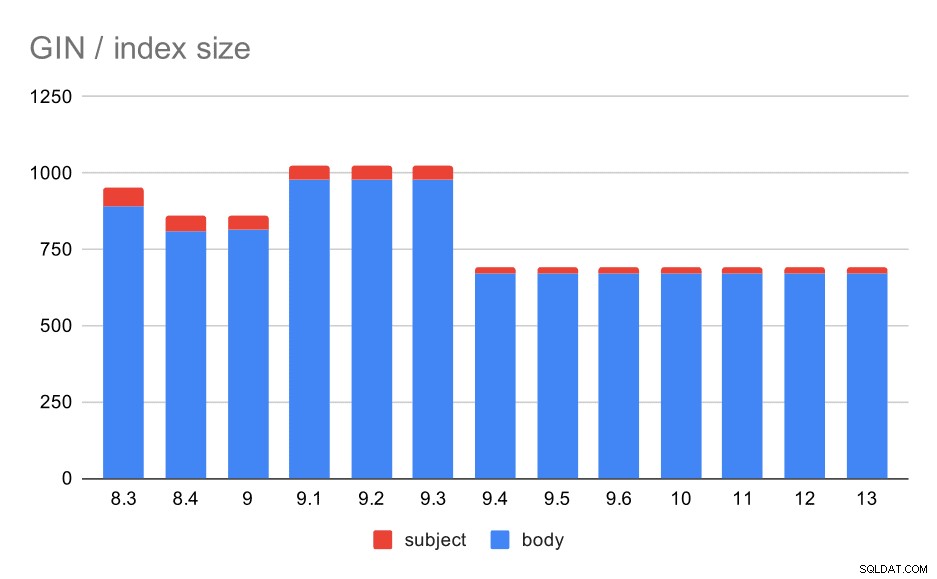
Tamaño de los índices GIN en el asunto/cuerpo del mensaje. Los valores son megabytes.
La siguiente tabla muestra los tamaños de los índices GIN en el cuerpo y asunto del mensaje. Los valores están en megabytes.
| CUERPO | ASUNTO | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9.6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
En este caso, creo que podemos asumir con seguridad que esta aceleración está relacionada con este elemento en las notas de la versión 9.4:
- Reducir el tamaño del índice GIN (Alexander Korotkov, Heikki Linnakangas)
La variabilidad de tamaño entre 8,3 y 9,1 parece deberse a cambios en la lematización (cómo se transforman las palabras a la forma "básica"). Además de las diferencias de tamaño, las consultas en esas versiones arrojan números de resultados ligeramente diferentes, por ejemplo.
GIN/consultas
Ahora, la parte principal de este punto de referencia:el rendimiento de las consultas. Todos los números presentados aquí son para un solo cliente:ya hemos discutido la escalabilidad del cliente en la parte relacionada con el rendimiento de OLTP, los hallazgos también se aplican a estas consultas. (Además, esta máquina en particular solo tiene 4 núcleos, por lo que de todos modos no llegaríamos muy lejos en términos de pruebas de escalabilidad).
SELECCIONE id, asunto DESDE mensajes DONDE tsvector @@ $1
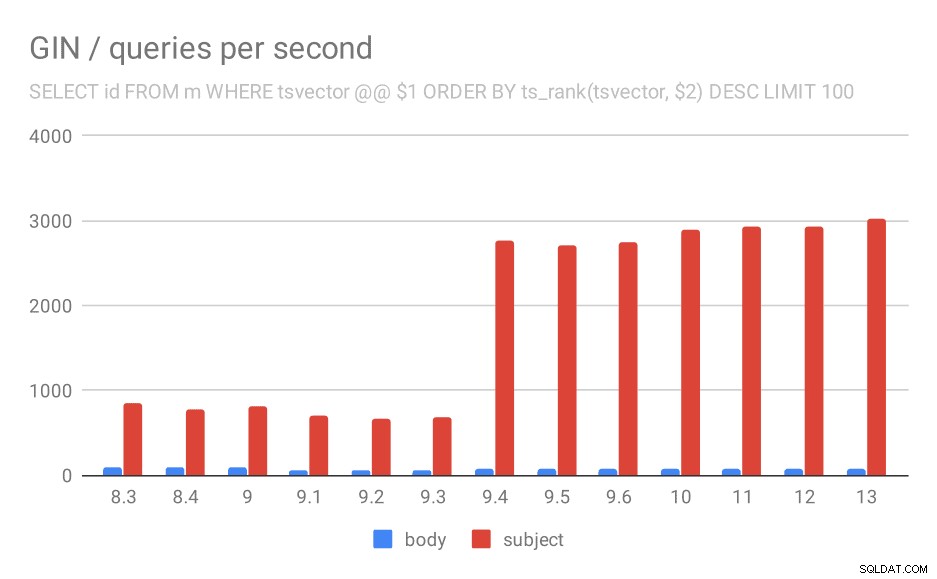
Primero, la consulta que busca todos los documentos coincidentes. Para las búsquedas en la columna "asunto" podemos hacer alrededor de 800 consultas por segundo (y en realidad cae un poco en 9.1), pero en 9.4 de repente se dispara hasta 3000 consultas por segundo. Para la columna "cuerpo" es básicamente la misma historia:160 consultas inicialmente, una caída a ~90 consultas en 9.1 y luego un aumento a 300 en 9.4.
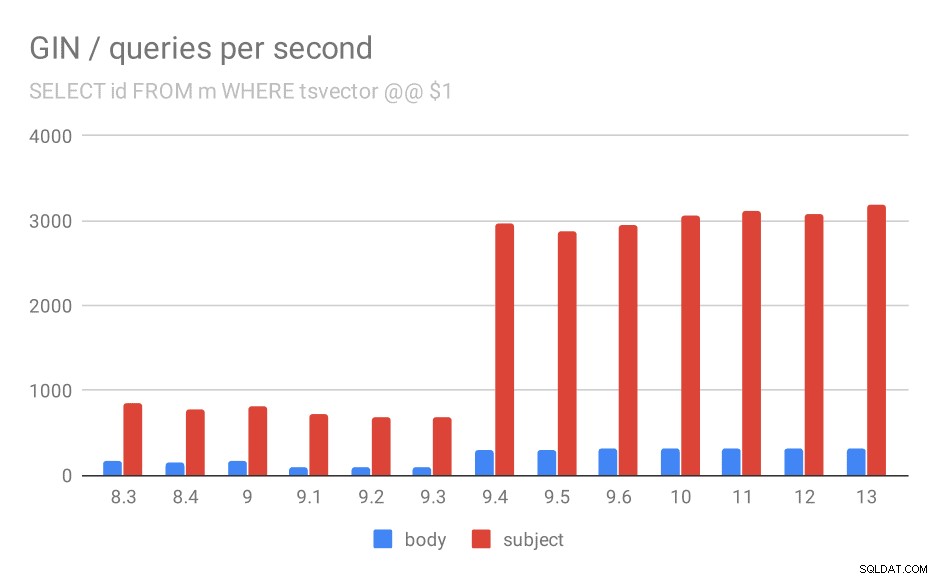
Número de consultas por segundo para la primera consulta (obteniendo todas las filas coincidentes).
Y de nuevo, los datos de origen:los números son el rendimiento (consultas por segundo).
| CUERPO | ASUNTO | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9.6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Creo que podemos asumir con seguridad que la mejora en 9.4 está relacionada con este elemento en las notas de la versión:
- Mejorar la velocidad de las búsquedas GIN de claves múltiples (Alexander Korotkov, Heikki Linnakangas)
Entonces, otra mejora 9.4 en GIN de los mismos dos desarrolladores:claramente, Alexander y Heikki hicieron un gran trabajo en los índices GIN en la versión 9.4 😉
SELECCIONE id, asunto DESDE mensajes DONDE tsvector @@ $1
ORDENAR POR ts_rank(tsvector, $2) DESC LIMIT 100
Para la consulta que clasifica los resultados por relevancia usando ts_rank y LIMIT, el comportamiento general es casi exactamente el mismo, creo que no es necesario describir el gráfico en detalle.
Número de consultas por segundo para la segunda consulta (obteniendo las filas más relevantes).
| CUERPO | ASUNTO | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9.6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Sin embargo, hay una pregunta:¿por qué el rendimiento cayó entre 9.0 y 9.1? Parece haber una caída bastante significativa en el rendimiento:alrededor del 50 % para las búsquedas corporales y del 20 % para las búsquedas en asuntos de mensajes. No tengo una explicación clara de lo que pasó, pero tengo dos observaciones...
En primer lugar, el tamaño del índice cambió:si observa el primer gráfico "GIN / tamaño del índice" y la tabla, verá que el índice en los cuerpos de los mensajes aumentó de 813 MB a aproximadamente 977 MB. Ese es un aumento significativo, y podría explicar parte de la desaceleración. Sin embargo, el problema es que el índice de temas no creció en absoluto, pero las consultas también se ralentizaron.
En segundo lugar, podemos ver cuántos resultados arrojaron las consultas. El conjunto de datos indexados es exactamente el mismo, por lo que parece razonable esperar la misma cantidad de resultados en todas las versiones de PostgreSQL, ¿verdad? Bueno, en la práctica se ve así:
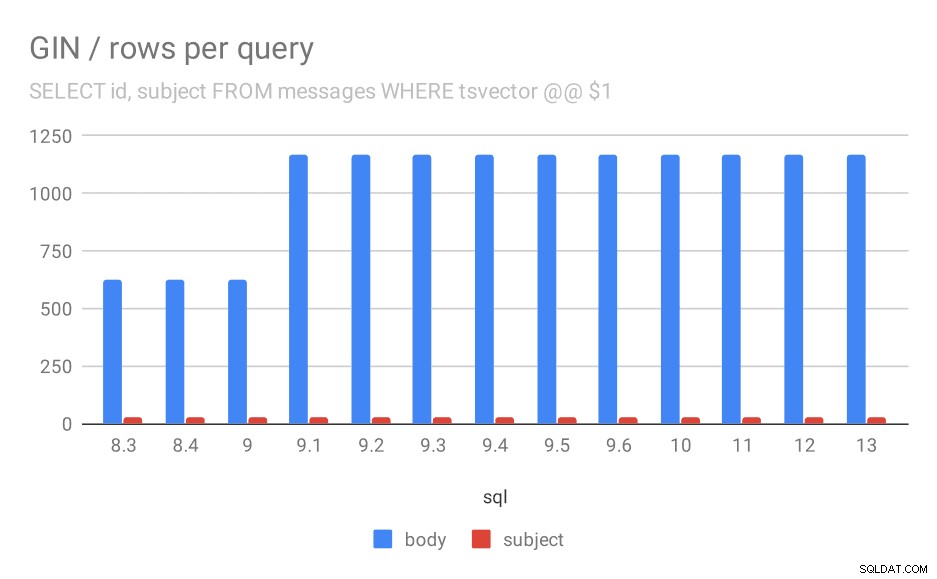
Número de filas devueltas para una consulta en promedio.
| CUERPO | ASUNTO | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9.6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Claramente, en 9.1, el número promedio de resultados de búsquedas en los cuerpos de los mensajes se duplica repentinamente, lo que es casi perfectamente proporcional a la ralentización. Sin embargo, el número de resultados para las búsquedas por tema sigue siendo el mismo. No tengo una muy buena explicación para esto, excepto que la indexación cambió de una manera que permite hacer coincidir más mensajes, pero lo hace un poco más lento. Si tienes mejores explicaciones, ¡me gustaría escucharlas!
GiST / carga de datos
Ahora, el otro tipo de índices de texto completo:GiST. Estos índices tienen pérdidas, es decir, requieren una nueva verificación de los resultados utilizando los valores de la tabla. Por lo tanto, podemos esperar un rendimiento más bajo en comparación con los índices GIN, pero por lo demás, es razonable esperar aproximadamente el mismo patrón.
De hecho, los tiempos de carga coinciden casi perfectamente con el GIN:los tiempos de creación del índice son diferentes, pero el patrón general es el mismo. Aceleración en 9.1, pequeña desaceleración en 11.
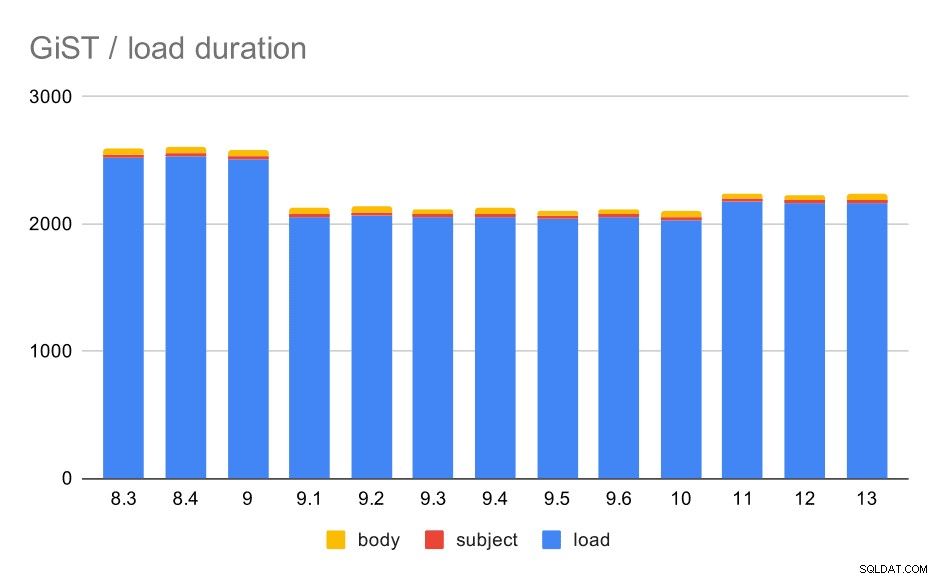
Operaciones de carga de datos con una tabla e índices GiST.
| LOAD | ASUNTO | CUERPO | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9.6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
Sin embargo, el tamaño del índice se mantuvo casi constante:no hubo mejoras en GiST similares a GIN en 9.4, lo que redujo el tamaño en ~30 %. Hay un aumento en 9.1, que es otra señal de que la indexación de texto completo cambió en esa versión para indexar más palabras.
Esto se ve respaldado por el número medio de resultados con GiST que es exactamente el mismo que para GIN (con un aumento de 9,1).
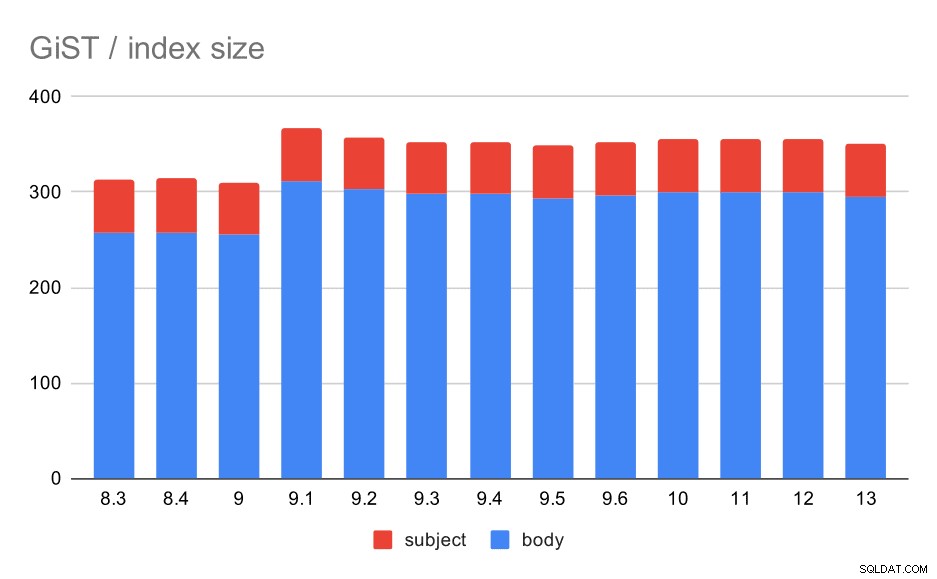
Tamaño de los índices GiST en el asunto/cuerpo del mensaje. Los valores son megabytes.
| CUERPO | ASUNTO | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
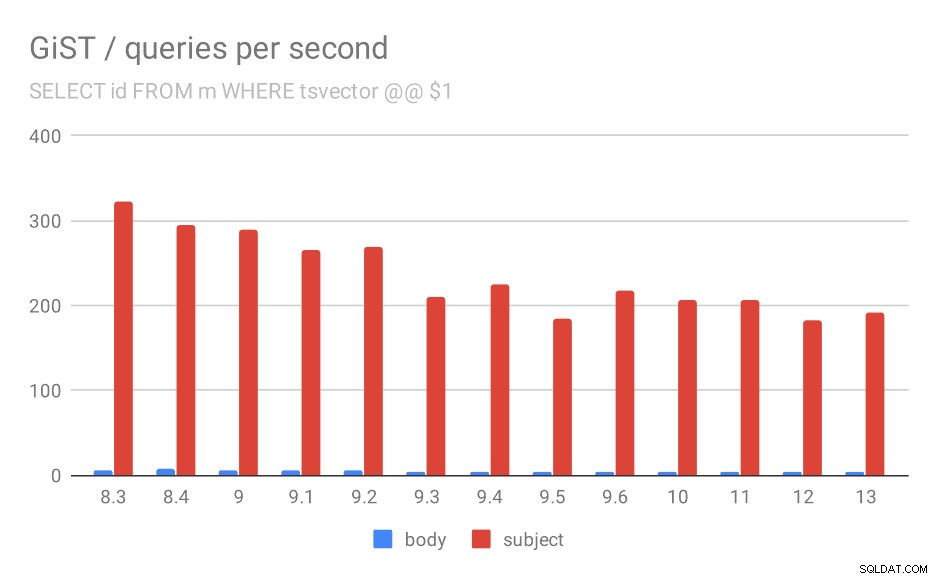
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
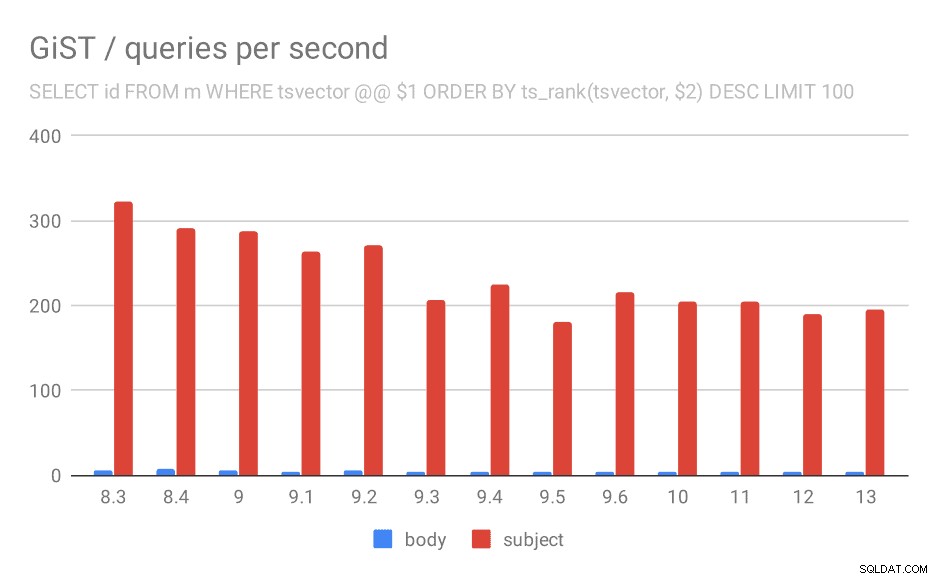
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).