Debe haber muchas herramientas poderosas disponibles como opción de respaldo y restauración para PostgreSQL en general; Barman, PgBackRest, BART son, por nombrar algunos, en este contexto. Lo que nos llamó la atención fue que Barman es una herramienta que se está poniendo al día rápidamente con el despliegue de producción y las tendencias del mercado.
Ya sea una implementación basada en Docker, la necesidad de almacenar copias de seguridad en un almacenamiento en la nube diferente o las necesidades de una arquitectura de recuperación ante desastres altamente personalizable, Barman es un competidor muy fuerte en todos estos casos.
Este blog explora Barman con pocas suposiciones sobre la implementación, sin embargo, en ningún caso, esto debe considerarse como un conjunto posible de características. Barman está mucho más allá de lo que podemos capturar en este blog y debe explorarse más a fondo si se considera la "copia de seguridad y restauración de la instancia de PostgreSQL".
Suposición de implementación DR Ready
RPO=0 generalmente tiene un costo:la implementación del servidor en espera síncrono a menudo cumpliría con eso, pero luego afecta el TPS del servidor principal con bastante frecuencia.
Al igual que PostgreSQL, Barman ofrece numerosas opciones de implementación para satisfacer sus necesidades cuando se trata de RPO frente a rendimiento. Piense en la simplicidad de implementación, RPO=0 o un impacto de rendimiento casi nulo; Barman cabe en todos.
Consideramos la siguiente implementación para establecer una solución de recuperación ante desastres para nuestra arquitectura de respaldo y restauración.
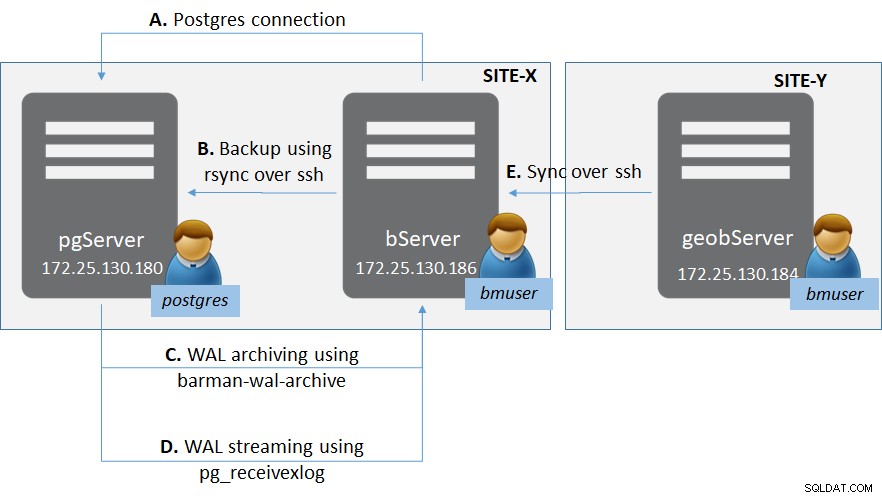 Figura 1:Implementación de PostgreSQL con Barman
Figura 1:Implementación de PostgreSQL con BarmanHay dos sitios (como en general para sitios de recuperación de desastres) - Sitio-X y Sitio-Y.
En Site-X hay:
- Un servidor 'pgServer' que aloja una instancia de servidor PostgreSQL pgServer y un usuario de sistema operativo 'postgres'
- Instancia de PostgreSQL también para albergar un rol de superusuario 'bmuser'
- Un servidor 'bServer' que aloja los archivos binarios de Barman y un usuario de sistema operativo 'bmuser'
En el Sitio-Y hay:
- Un servidor 'geobServer' que aloja los archivos binarios de Barman y un usuario de sistema operativo 'bmuser'
Hay varios tipos de conexión involucrados en esta configuración.
- Entre 'bServer' y 'pgServer':
- Conectividad del plano de administración de Barman a la instancia de PostgreSQL
- conectividad rsync para hacer una copia de seguridad base real desde Barman a la instancia de PostgreSQL
- Archivado WAL mediante barman-wal-archive desde la instancia de PostgreSQL a Barman
- Transmisión WAL usando pg_receivexlog en Barman
- Entre 'bServer' y 'geobserver':
- Sincronización entre servidores Barman para proporcionar replicación geográfica
Conectividad primero
La principal necesidad de conectividad entre los servidores es a través de ssh. Para hacerlo sin contraseña, se utilizan claves ssh. Establezcamos las claves ssh e intercambiémoslas.
En pgServer:
[email protected]$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
[email protected]$ ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[email protected]$ ssh [email protected] "chmod 600 ~/.ssh/authorized_keys"En bServer:
[email protected]$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
[email protected]$ ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[email protected]$ ssh [email protected] "chmod 600 ~/.ssh/authorized_keys"En geobServer:
[email protected]$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
[email protected]$ ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[email protected]$ ssh [email protected] "chmod 600 ~/.ssh/authorized_keys"Configuración de la instancia de PostgreSQL
Hay dos cosas principales que necesitamos para reconstituir una instancia de postgres:el directorio base y los registros WAL / Transactions generados a partir de entonces. El servidor Barman realiza un seguimiento inteligente de ellos. Lo que necesitamos es asegurarnos de que se generen los feeds adecuados para que Barman recolecte estos artefactos.
Agregue las siguientes líneas a postgresql.conf:
listen_addresses = '172.25.130.180' #as per above deployment assumption
wal_level = replica #or higher
archive_mode = on
archive_command = 'barman-wal-archive -U bmuser bserver pgserver %p'El comando Archivar garantiza que cuando la instancia de postgres va a archivar WAL, la utilidad barman-wal-archive lo envía al servidor Barman. Cabe señalar que el paquete barman-cli, por lo tanto, debe estar disponible en 'pgServer'. Hay otra opción de usar rsync si no queremos usar la utilidad barman-wal-archive.
Agregue lo siguiente a pg_hba.conf:
host all all 172.25.130.186/32 md5
host replication all 172.25.130.186/32 md5Básicamente permite una replicación y una conexión normal desde 'bmserver' a esta instancia de postgres.
Ahora simplemente reinicie la instancia y cree un rol de superusuario llamado bmuser:
[email protected]$ pg_ctl restart
[email protected]$ createuser -s -P bmuser Si es necesario, también podemos evitar usar bmuser como superusuario; eso necesitaría privilegios asignados a este usuario. Para el ejemplo anterior, también usamos bmuser como contraseña. Pero eso es prácticamente todo, en lo que respecta a la configuración de una instancia de PostgreSQL.
Configuración del barman
Barman tiene tres componentes básicos en su configuración:
- Configuración global
- Configuración de nivel de servidor
- Usuario que ejecutará el barman
En nuestro caso, dado que Barman se instaló mediante rpm, nuestros archivos de configuración global se almacenaron en:
/etc/barman.confQueríamos almacenar la configuración de nivel de servidor en el directorio de inicio de bmuser, por lo tanto, nuestro archivo de configuración global tenía el siguiente contenido:
[barman]
barman_user = bmuser
configuration_files_directory = /home/bmuser/barman.d
barman_home = /home/bmuser
barman_lock_directory = /home/bmuser/run
log_file = /home/bmuser/barman.log
log_level = INFOConfiguración del servidor primario de Barman
En la implementación anterior, decidimos mantener el servidor Barman principal en el mismo centro de datos/sitio donde se guarda la instancia de PostgreSQL. El beneficio del mismo es que hay menos retraso y una recuperación más rápida en caso de ser necesario. No hace falta decir que también se requieren menos necesidades informáticas y/o de ancho de banda de red en el servidor PostgreSQL.
Para permitir que Barman administre la instancia de PostgreSQL en pgServer, debemos agregar un archivo de configuración (llamamos pgserver.conf) con el siguiente contenido:
[pgserver]
description = "Example pgserver configuration"
ssh_command = ssh [email protected]
conninfo = host=pgserver user=bmuser dbname=postgres
backup_method = rsync
reuse_backup = link
backup_options = concurrent_backup
parallel_jobs = 2
archiver = on
archiver_batch_size = 50
path_prefix = "/usr/pgsql-12/bin"
streaming_conninfo = host=pgserver user=bmuser dbname=postgres
streaming_archiver=on
create_slot = autoY un archivo .pgpass que contiene las credenciales para bmuser en la instancia de PostgreSQL:
echo 'pgserver:5432:*:bmuser:bmuser' > ~/.pgpass Para comprender un poco más los elementos de configuración importantes:
- comando_ssh :se utiliza para establecer una conexión a través de la cual se realizará rsync
- conninfo :Cadena de conexión para permitir que Barman establezca una conexión con el servidor postgres
- reutilización_copia de seguridad :para permitir copias de seguridad incrementales con menos almacenamiento
- método_de_respaldo :método para realizar una copia de seguridad del directorio base
- ruta_prefijo :ubicación donde se almacenan los binarios pg_receivexlog
- streaming_conninfo :cadena de conexión utilizada para transmitir WAL
- create_slot :para asegurarse de que las ranuras hayan sido creadas por la instancia de postgres
Configuración del servidor Barman pasivo
La configuración de un sitio de replicación geográfica es bastante simple. Todo lo que necesita es una información de conexión ssh sobre la cual este sitio de nodo pasivo realizará la replicación.
Lo interesante es que un nodo tan pasivo puede funcionar en modo mixto; en otras palabras, pueden actuar como servidores Barman activos para realizar copias de seguridad de los sitios PostgreSQL y, en paralelo, actuar como un sitio de replicación/en cascada para otros servidores Barman.
Dado que, en nuestro caso, esta instancia de Barman (en el Sitio-Y) debe ser solo un nodo pasivo, todo lo que necesitamos es crear el archivo /home/bmuser/barman.d/pgserver.conf con la siguiente configuración:
[pgserver]
description = "Geo-replication or sync for pgserver"
primary_ssh_command = ssh [email protected]Suponiendo que las claves se intercambiaron y la configuración global en este nodo se realizó como se mencionó anteriormente, casi hemos terminado con la configuración.
Y aquí está nuestra primera copia de seguridad y restauración
En el servidor b, asegúrese de que se haya activado el proceso en segundo plano para recibir WAL; y luego verifique la configuración del servidor:
[email protected]$ barman cron
[email protected]$ barman check pgserverLa verificación debería estar bien para todos los subpasos. De lo contrario, consulte /home/bmuser/barman.log.
Emita el comando de copia de seguridad en Barman para asegurarse de que haya DATOS base en los que se pueda aplicar WAL:
[email protected]$ barman backup pgserverEn el 'geobmserver', asegúrese de que la replicación se realice ejecutando los siguientes comandos:
[email protected]$ barman cron
[email protected]$ barman list-backup pgserverEl cron debe insertarse en el archivo crontab (si no está presente). En aras de la simplicidad, no lo he mostrado aquí. El último comando mostrará que la carpeta de copia de seguridad también se ha creado en el geobmserver.
Ahora, en la instancia de Postgres, creemos algunos datos ficticios:
[email protected]$ psql -U postgres -c "CREATE TABLE dummy_data( i INTEGER);"
[email protected]$ psql -U postgres -c "insert into dummy_data values ( generate_series (1, 1000000 ));"La replicación de WAL desde la instancia de PostgreSQL se puede ver usando el siguiente comando:
[email protected]$ psql -U postgres -c "SELECT * from pg_stat_replication ;”Para volver a crear una instancia en el Sitio-Y, primero asegúrese de que los registros WAL se cambien. o este ejemplo, para crear una recuperación limpia:
[email protected]$ barman switch-xlog --force --archive pgserverEn Site-X, abramos una instancia de PostgreSQL independiente para verificar si la copia de seguridad es correcta:
[email protected]$ barman cron
barman recover --get-wal pgserver latest /tmp/dataAhora, edite los archivos postgresql.conf y postgresql.auto.conf según sus necesidades. A continuación, explique los cambios realizados para este ejemplo:
- postgresql.conf :listen_addresses comentado de forma predeterminada en localhost
- postgresql.auto.conf :eliminado sudo bmuser de restore_command
Revise estos DATOS en /tmp/data y verifique la existencia de sus registros.
Conclusión
Esto fue solo la punta de un iceberg. Barman es mucho más profundo que esto debido a la funcionalidad que proporciona, p. actuando como espera sincronizada, secuencias de comandos de enlace, etc. No hace falta decir que se debe explorar la documentación en su totalidad para configurarla según las necesidades de su entorno de producción.



