Si bien hay varias formas de recuperar su base de datos PostgreSQL, uno de los enfoques más convenientes para restaurar sus datos desde una copia de seguridad lógica. Las copias de seguridad lógicas desempeñan un papel importante para la planificación de recuperación y desastres (DRP). Las copias de seguridad lógicas son copias de seguridad realizadas, por ejemplo, mediante pg_dump o pg_dumpall, que generan instrucciones SQL para obtener todos los datos de la tabla que se escriben en un archivo binario.
También se recomienda ejecutar copias de seguridad lógicas periódicas en caso de que sus copias de seguridad físicas fallen o no estén disponibles. Para PostgreSQL, la restauración puede ser problemática si no está seguro de qué herramientas usar. La herramienta de copia de seguridad pg_dump suele combinarse con la herramienta de restauración pg_restore.
pg_dump y pg_restore actúan en conjunto si ocurre un desastre y necesita recuperar sus datos. Si bien cumplen el propósito principal de volcar y restaurar, requiere que realice algunas tareas adicionales cuando necesita recuperar su clúster y realizar una conmutación por error (si su principal activo o maestro muere debido a una falla de hardware o corrupción del sistema VM). Terminará encontrando y utilizando herramientas de terceros que pueden manejar la conmutación por error o la recuperación automática de clústeres.
En este blog, veremos cómo funciona pg_restore y lo compararemos con cómo ClusterControl maneja la copia de seguridad y la restauración de sus datos en caso de que ocurra un desastre.
Mecanismos de pg_restore
pg_restore es útil al obtener las siguientes tareas:
- junto con pg_dump para generar archivos generados por SQL que contienen datos, roles de acceso, bases de datos y definiciones de tablas
- restaurar una base de datos PostgreSQL desde un archivo creado por pg_dump en uno de los formatos que no son de texto sin formato.
- Emitirá los comandos necesarios para reconstruir la base de datos al estado en que se encontraba en el momento en que se guardó.
- tiene la capacidad de ser selectivo o incluso de reordenar los elementos antes de restaurarlos según el archivo
- Los archivos de almacenamiento están diseñados para ser portátiles entre arquitecturas.
- pg_restore puede operar en dos modos.
- Si se especifica un nombre de base de datos, pg_restore se conecta a esa base de datos y restaura el contenido del archivo directamente en la base de datos.
- o bien, se crea un script que contiene los comandos SQL necesarios para reconstruir la base de datos y se escribe en un archivo o salida estándar. Su salida de script tiene equivalencia con el formato generado por pg_dump
- Algunas de las opciones que controlan la salida son, por lo tanto, análogas a las opciones de pg_dump.
Una vez que haya restaurado los datos, es mejor y recomendable ejecutar ANALYZE en cada tabla restaurada para que el optimizador tenga estadísticas útiles. Aunque adquiere READ LOCK, es posible que deba ejecutarlo durante un tráfico bajo o durante su período de mantenimiento.
Ventajas de pg_restore
pg_dump y pg_restore en tándem tienen capacidades que son convenientes para que las utilice un DBA.
- pg_dump y pg_restore tienen la capacidad de ejecutarse en paralelo especificando la opción -j. El uso de -j/--jobs
le permite especificar cuántos trabajos en ejecución en paralelo pueden ejecutarse especialmente para cargar datos, crear índices o crear restricciones usando múltiples trabajos simultáneos. - Es muy práctico de usar, puede volcar o cargar selectivamente una base de datos o tablas específicas
- Permite y brinda flexibilidad al usuario sobre qué base de datos en particular, esquema o reordenar los procedimientos que se ejecutarán en función de la lista. Incluso puede generar y cargar la secuencia de SQL libremente, como evitar acls o privilegios de acuerdo con sus necesidades. Hay muchas opciones para satisfacer sus necesidades.
- Le brinda la capacidad de generar archivos SQL como pg_dump desde un archivo. Esto es muy conveniente si desea cargar en otra base de datos o host para aprovisionar un entorno separado.
- Es fácil de entender según la secuencia generada de procedimientos SQL.
- Es una forma conveniente de cargar datos en un entorno de replicación. No necesita que su réplica se vuelva a configurar, ya que las declaraciones son SQL que se replicaron en los nodos de espera y recuperación.
Limitaciones de pg_restore
Para las copias de seguridad lógicas, las limitaciones obvias de pg_restore junto con pg_dump son el rendimiento y la velocidad cuando se utilizan las herramientas. Puede ser útil cuando desea aprovisionar un entorno de base de datos de prueba o desarrollo y cargar sus datos, pero no es aplicable cuando su conjunto de datos es enorme. PostgreSQL tiene que volcar sus datos uno por uno o ejecutar y aplicar sus datos secuencialmente por el motor de la base de datos. Aunque puede hacer que esto sea ligeramente flexible para acelerar, como especificar -j o usar --single-transaction para evitar el impacto en su base de datos, el motor todavía tiene que analizar la carga usando SQL.
Además, la documentación de PostgreSQL establece las siguientes limitaciones, con nuestras adiciones a medida que observamos estas herramientas (pg_dump y pg_restore):
- Al restaurar datos en una tabla preexistente y se usa la opción --disable-triggers, pg_restore emite comandos para deshabilitar activadores en las tablas de usuario antes de insertar los datos, luego emite comandos para volver a habilitarlos después de que se hayan insertado los datos. Si la restauración se detiene a la mitad, los catálogos del sistema pueden quedar en un estado incorrecto.
- pg_restore no puede restaurar objetos grandes de forma selectiva; por ejemplo, solo los de una tabla específica. Si un archivo contiene objetos grandes, se restaurarán todos los objetos grandes, o ninguno de ellos si se excluyen mediante -L, -t u otras opciones.
- Se espera que ambas herramientas generen una gran cantidad de tamaño (archivos, directorios o archivo tar), especialmente para una base de datos enorme.
- Para pg_dump, al volcar una sola tabla o como texto sin formato, pg_dump no maneja objetos grandes. Los objetos grandes deben volcarse con toda la base de datos utilizando uno de los formatos de archivo que no son de texto.
- Si tiene archivos tar generados por estas herramientas, tenga en cuenta que los archivos tar están limitados a un tamaño inferior a 8 GB. Esta es una limitación inherente del formato de archivo tar. Por lo tanto, este formato no se puede utilizar si la representación textual de una tabla supera ese tamaño. El tamaño total de un archivo tar y cualquiera de los otros formatos de salida no está limitado, excepto posiblemente por el sistema operativo.
Uso de pg_restore
Usar pg_restore es bastante útil y fácil de usar. Dado que se combina con pg_dump, ambas herramientas funcionan lo suficientemente bien siempre que la salida de destino se adapte a la otra. Por ejemplo, el siguiente pg_dump no será útil para pg_restore,
[[email protected] ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Este resultado será compatible con psql y se verá así:
[[email protected] ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;Pero esto fallará para pg_restore ya que no hay un formato simple a seguir:
[[email protected] ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[[email protected] ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerAhora, vayamos a términos más útiles para pg_restore.
pg_restore:colocar y restaurar
Considere un uso simple de pg_restore que haya eliminado una base de datos, por ejemplo,
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Restaurarlo con pg_restore it muy simple,
[[email protected] ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump La -C/--create aquí establece que se crea la base de datos una vez que se encuentra en el encabezado. El -d postgres apunta a la base de datos de postgres pero no significa que creará las tablas para la base de datos de postgres. Requiere que la base de datos exista. Si no se especifica -C, la(s) tabla(s) y los registros se almacenarán en esa base de datos a la que se hace referencia con el argumento -d.
Restauración selectiva por tabla
Restaurar una tabla con pg_restore es fácil y simple. Por ejemplo, tiene dos tablas, a saber, las tablas "b" y "d". Digamos que ejecuta el siguiente comando pg_dump a continuación,
[[email protected] ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Donde el contenido de este directorio se verá como sigue,
[[email protected] ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Si desea restaurar una tabla (es decir, "d" en este ejemplo),
[[email protected] ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Deberá tener,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:Copiar tablas de base de datos a una base de datos diferente
Puede incluso copiar el contenido de su base de datos existente y tenerlo en su base de datos de destino. Por ejemplo, tengo las siguientes bases de datos,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)La base de datos paultest es una base de datos vacía mientras vamos a copiar lo que hay dentro de la base de datos maxtest,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Para copiarlo, necesitamos volcar los datos de la base de datos maxtest de la siguiente manera,
[[email protected] ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Luego cárguelo o restáurelo de la siguiente manera,
Ahora, tenemos datos en la base de datos paultest y las tablas se han almacenado en consecuencia.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Generar un archivo SQL con reordenación
He visto mucho uso de pg_restore, pero parece que esta función no suele mostrarse. Encontré este enfoque muy interesante ya que le permite ordenar en función de lo que no desea incluir y luego generar un archivo SQL a partir del pedido que desea continuar.
Por ejemplo, usaremos el ejemplo pgdump_data.tar que hemos generado anteriormente y crearemos una lista. Para hacer esto, ejecute el siguiente comando:
[[email protected] ~]# pg_restore -l pgdump_data.tar > my.listEsto generará un archivo como se muestra a continuación:
[[email protected] ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresAhora, volvamos a ordenarlo o digamos que he eliminado la creación de SEQUENCE y también la creación de la restricción. Esto se vería así,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresPara generar el archivo en formato SQL, simplemente haga lo siguiente:
[[email protected] ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Ahora, el archivo /tmp/selective_data.out será un archivo generado por SQL y se podrá leer si usa psql, pero no pg_restore. Lo bueno de esto es que puede generar un archivo SQL de acuerdo con su plantilla en el que los datos solo se pueden restaurar desde un archivo existente o una copia de seguridad realizada usando pg_dump con la ayuda de pg_restore.
Restauración de PostgreSQL con ClusterControl
ClusterControl no utiliza pg_restore o pg_dump como parte de su conjunto de funciones. Usamos pg_dumpall para generar copias de seguridad lógicas y, lamentablemente, la salida no es compatible con pg_restore.
Hay varias otras formas de generar una copia de seguridad en PostgreSQL como se ve a continuación.
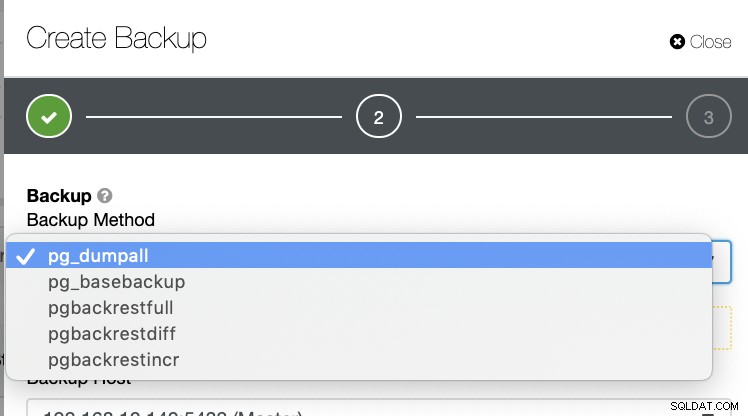
No existe tal mecanismo en el que pueda almacenar de forma selectiva una tabla, una base de datos, o copiar de una base de datos a otra base de datos.
ClusterControl admite la recuperación a un momento dado (PITR), pero esto no le permite administrar la restauración de datos de manera tan flexible como con pg_restore. Para toda la lista de métodos de respaldo, solo pg_basebackup y pgbackrest son compatibles con PITR.
La forma en que ClusterControl maneja la restauración es que tiene la capacidad de recuperar un clúster fallido siempre que la Recuperación automática esté habilitada como se muestra a continuación.

Una vez que el maestro falla, el esclavo puede recuperar automáticamente el clúster mientras ClusterControl realiza la conmutación por error (que se realiza automáticamente). Para la parte de recuperación de datos, su única opción es tener una recuperación de todo el clúster, lo que significa que proviene de una copia de seguridad completa. No hay capacidad para restaurar selectivamente en la base de datos o tabla de destino que solo desea restaurar. Si desea hacer eso, restaure la copia de seguridad completa, es fácil hacerlo con ClusterControl. Puede ir a las pestañas de Copia de seguridad como se muestra a continuación,
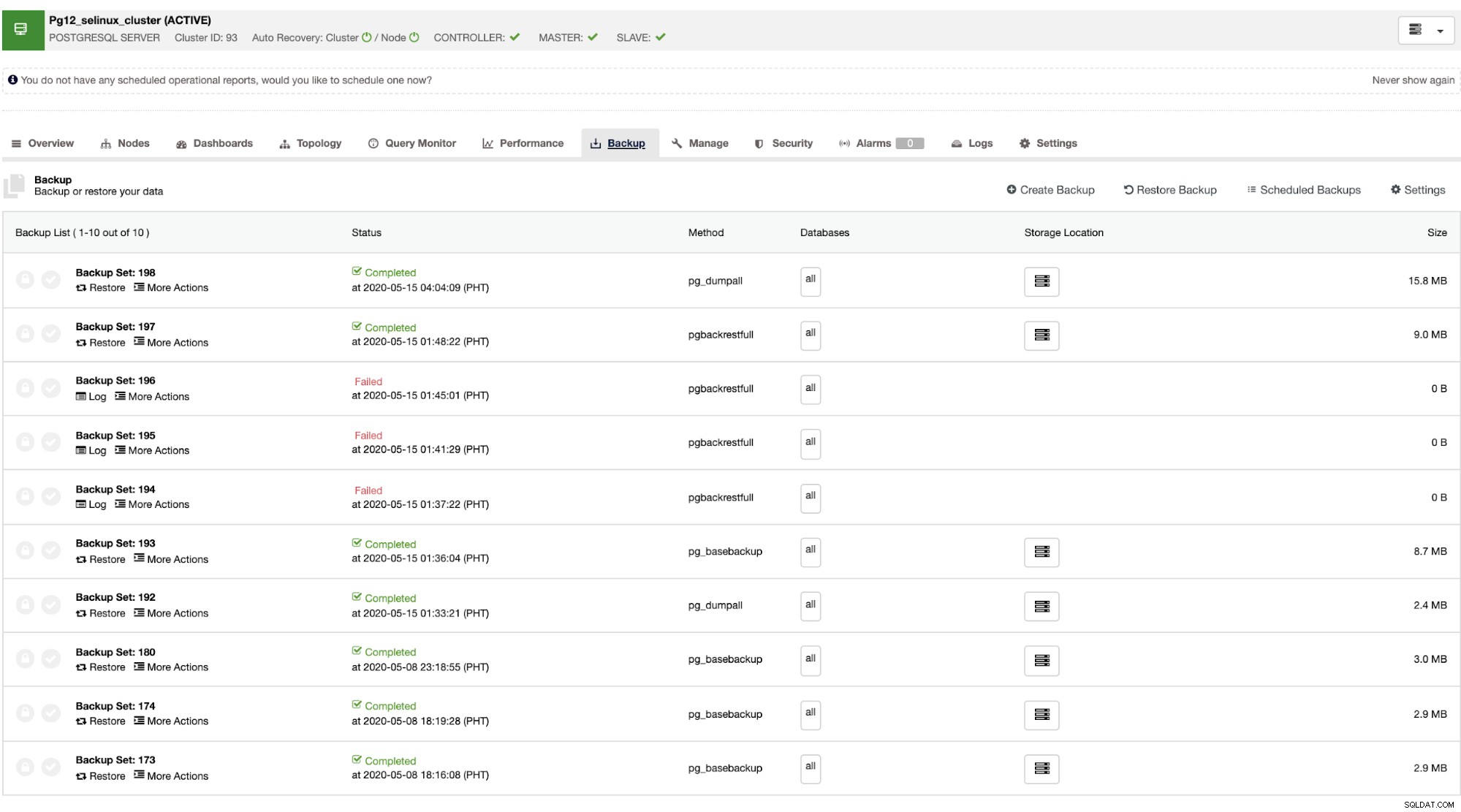
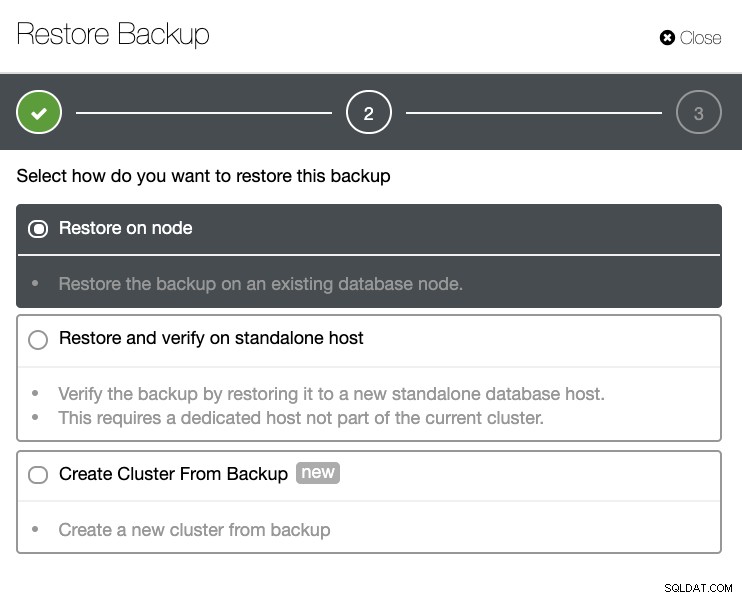
Tendrá una lista completa de copias de seguridad exitosas y fallidas. Luego, puede restaurarlo eligiendo la copia de seguridad de destino y haciendo clic en el botón "Restaurar". Esto le permitirá restaurar en un nodo existente registrado en ClusterControl, verificar en un nodo independiente o crear un clúster a partir de la copia de seguridad.
Conclusión
El uso de pg_dump y pg_restore simplifica el enfoque de copia de seguridad/volcado y restauración. Sin embargo, para un entorno de base de datos a gran escala, este podría no ser un componente ideal para la recuperación ante desastres. Para un procedimiento mínimo de selección y restauración, el uso de la combinación de pg_dump y pg_restore le brinda el poder de volcar y cargar sus datos de acuerdo con sus necesidades.
Para entornos de producción (especialmente para arquitecturas empresariales), puede usar el enfoque ClusterControl para crear una copia de seguridad y restauración con recuperación automática.
Una combinación de enfoques también es un buen enfoque. Esto lo ayuda a reducir su RTO y RPO y, al mismo tiempo, aprovechar la forma más flexible de restaurar sus datos cuando sea necesario.