Usar un entorno de múltiples nubes o múltiples centros de datos es útil para topologías distribuidas geográficamente o incluso para un plan de recuperación ante desastres y, de hecho, se está volviendo más popular hoy en día, por lo tanto, el concepto de cerebro dividido también está cobrando mayor importancia a medida que aumenta el riesgo de que se produzca en este tipo de escenarios. Debe evitar un cerebro dividido para evitar posibles pérdidas de datos o incoherencias en los datos, lo que podría ser un gran problema para la empresa.
En este blog, veremos qué es un cerebro dividido y cómo ClusterControl puede ayudarlo a evitar este importante problema.
¿Qué es el cerebro dividido?
En el mundo de PostgreSQL, el cerebro dividido ocurre cuando hay más de un nodo principal disponible al mismo tiempo (sin ninguna herramienta de terceros para tener un entorno multimaestro) que permite que la aplicación escriba en ambos nodos. En este caso, tendrá información diferente en cada nodo, lo que genera inconsistencia de datos en el clúster. Solucionar este problema puede ser difícil ya que debe fusionar datos, algo que a veces no es posible.
Cerebro dividido de PostgreSQL en una topología de múltiples nubes
Supongamos que tiene la siguiente topología de múltiples nubes para PostgreSQL (que es una topología bastante común hoy en día):
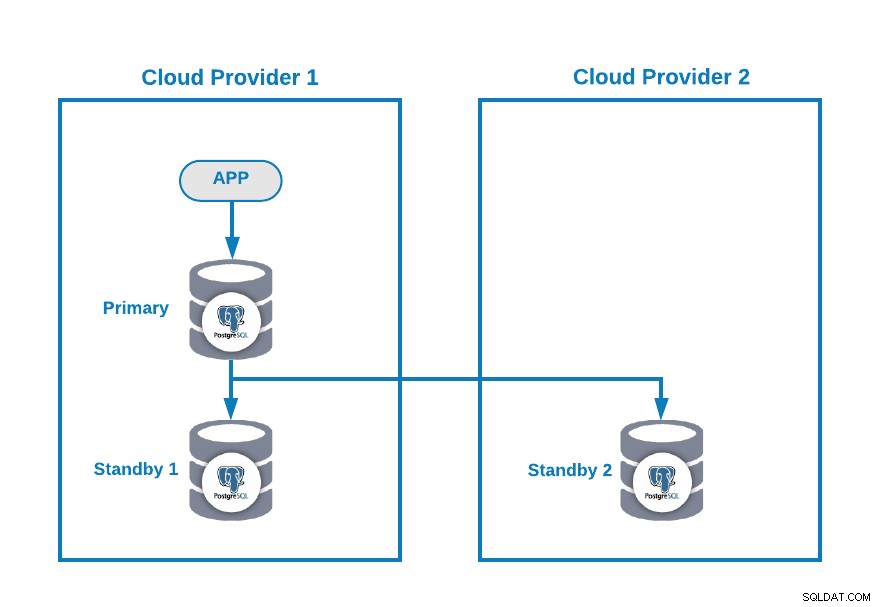
Por supuesto, puede mejorar este entorno, por ejemplo, agregando un Application Server en Cloud Provider 2, pero en este caso, usemos esta configuración básica.
Si su nodo principal está inactivo, uno de los nodos en espera debe promocionarse como nuevo principal y debe cambiar la dirección IP en su aplicación para usar este nuevo nodo principal.
Hay diferentes formas de hacer esto de forma automática. Por ejemplo, puede usar una dirección IP virtual asignada a su nodo principal y monitorearla. Si falla, promueva uno de los nodos en espera y migre la dirección IP virtual a este nuevo nodo principal, de modo que no necesite cambiar nada en su aplicación, y esto puede hacerse usando su propia secuencia de comandos o herramienta.
Por el momento, no tiene ningún problema, pero... si su antiguo nodo principal vuelve, debe asegurarse de que no tendrá dos nodos principales en el mismo clúster al mismo tiempo. .
Los métodos más comunes para evitar esta situación son:
- STONITH:Dispara al otro nódulo en la cabeza.
- SMITH:Dispárame en la cabeza.
PostgreSQL no proporciona ninguna forma de automatizar este proceso. Debes hacerlo por tu cuenta.
Cómo evitar el cerebro dividido en PostgreSQL con ClusterControl
Ahora, veamos cómo ClusterControl puede ayudarlo con esta tarea.
Primero, puede usarlo para implementar o importar su entorno PostgreSQL Multi-Cloud de una manera fácil, como puede ver en esta publicación de blog.
Luego, puede mejorar su topología agregando un Load Balancer (HAProxy), que también puede hacer usando ClusterControl siguiendo este blog. Entonces, tendrás algo como esto:
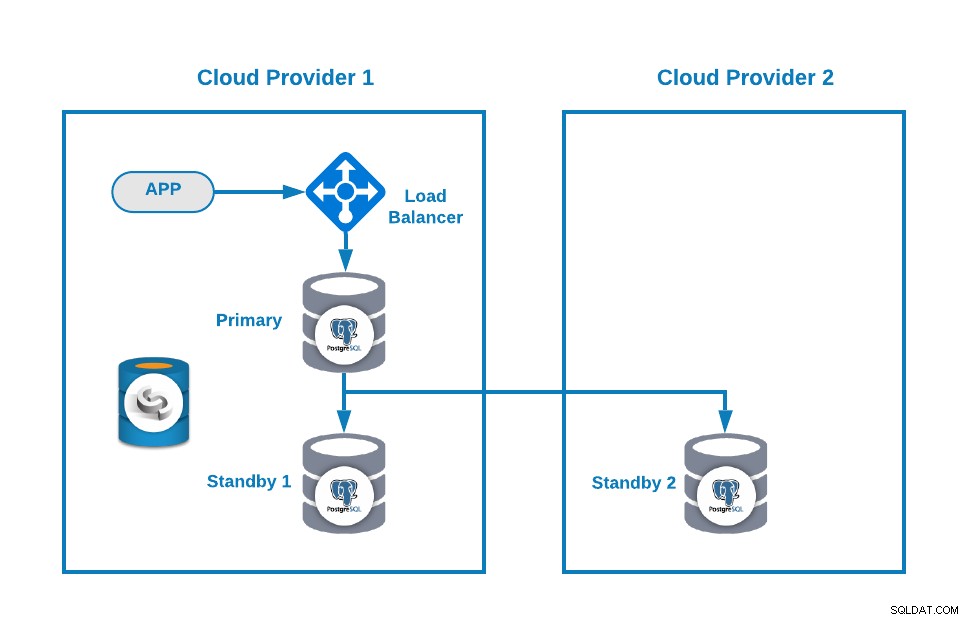
ClusterControl tiene una función de conmutación por error automática que detecta fallas maestras y promueve un modo de espera nodo con los datos más actuales como un nuevo primario. También falla el resto de los nodos en espera para replicar desde el nuevo nodo principal.
HAProxy está configurado por ClusterControl con dos puertos diferentes de forma predeterminada, uno de lectura y escritura y otro de solo lectura. En el puerto de lectura y escritura, tiene su nodo principal en línea y el resto de sus nodos fuera de línea, y en el puerto de solo lectura, tiene en línea tanto el nodo principal como el de reserva. De esta forma, puedes equilibrar el tráfico de lectura entre tus nodos pero te aseguras que al momento de escribir se usará el puerto de lectura-escritura, escribiendo en el nodo primario que es el servidor que está en línea.
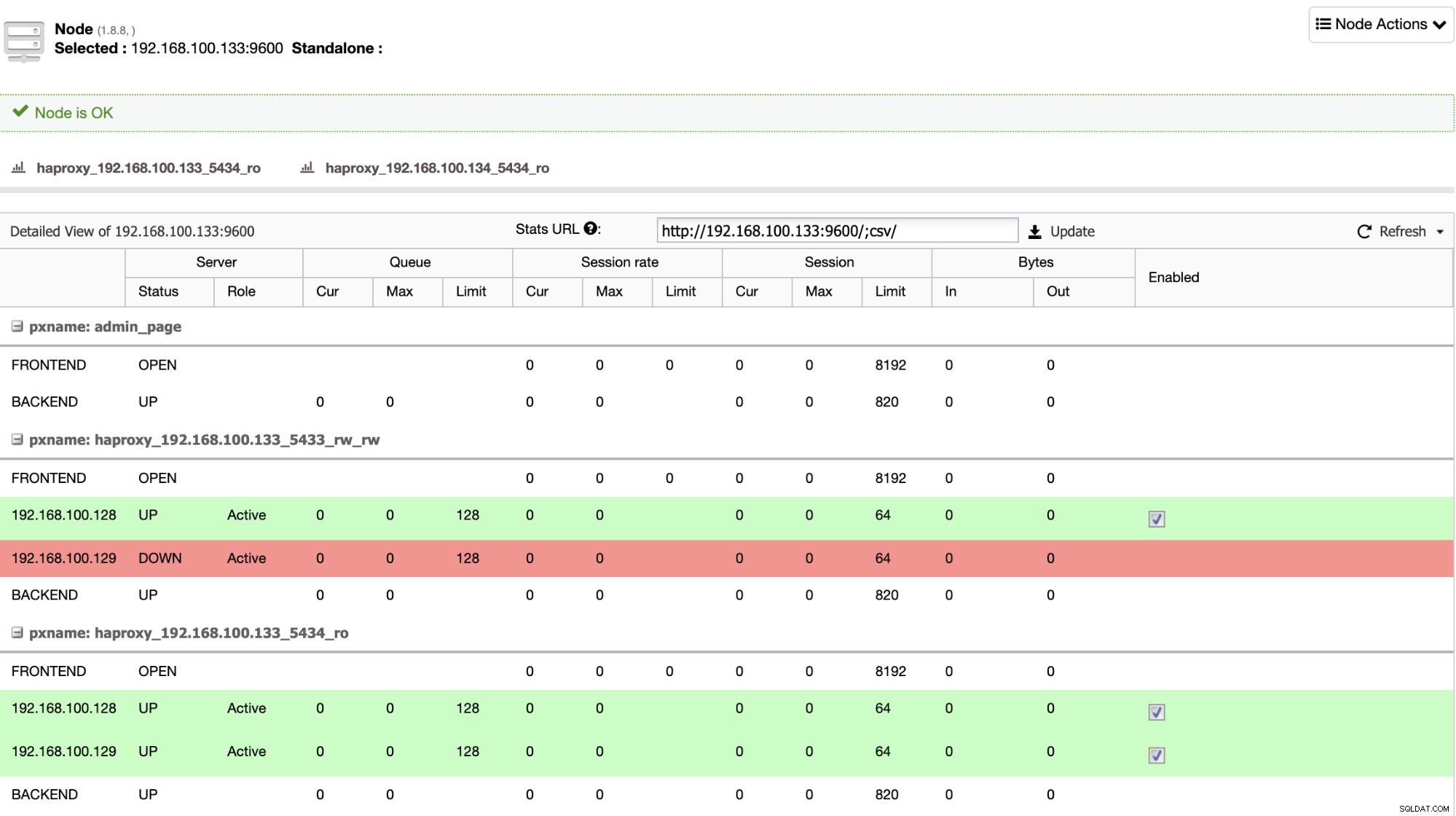
Cuando HAProxy detecta que uno de sus nodos, ya sea principal o en espera, está no accesible, lo marca automáticamente como fuera de línea y no lo tiene en cuenta para enviarle tráfico. Esta verificación se realiza mediante scripts de verificación de estado configurados por ClusterControl en el momento de la implementación. Éstos comprueban si las instancias están activas, si se están recuperando o si son de solo lectura.
Si su antiguo nodo principal vuelve, ClusterControl también evitará iniciarlo, para evitar una posible división del cerebro en caso de que tenga una conexión directa que no esté usando el Load Balancer, pero puede agregarlo al clúster como un nodo en espera de forma automática o manual mediante la interfaz de usuario o la CLI de ClusterControl, luego puede promoverlo para que tenga la misma topología que tenía en ejecución antes del problema.
Conclusión
Con la opción "Recuperación automática" activada, ClusterControl realizará esta conmutación por error automática y le notificará el problema. De esta manera, sus sistemas pueden recuperarse en segundos sin su intervención y evitará un cerebro dividido en un entorno PostgreSQL Multi-Cloud.
También puede mejorar su entorno de alta disponibilidad agregando más nodos de ClusterControl mediante la función CMON HA descrita en este blog.