La mayoría de las cargas de trabajo de OLTP implican el uso de E/S de disco aleatorio. Sabiendo que los discos (incluido el SSD) tienen un rendimiento más lento que el uso de RAM, los sistemas de bases de datos utilizan el almacenamiento en caché para aumentar el rendimiento. El almacenamiento en caché se trata de almacenar datos en la memoria (RAM) para un acceso más rápido en un momento posterior.
PostgreSQL también utiliza el almacenamiento en caché de sus datos en un espacio llamado shared_buffers. En este blog, exploraremos esta funcionalidad para ayudarlo a aumentar el rendimiento.
Conceptos básicos de almacenamiento en caché de PostgreSQL
Antes de profundizar en el concepto de almacenamiento en caché, repasemos los conceptos básicos.
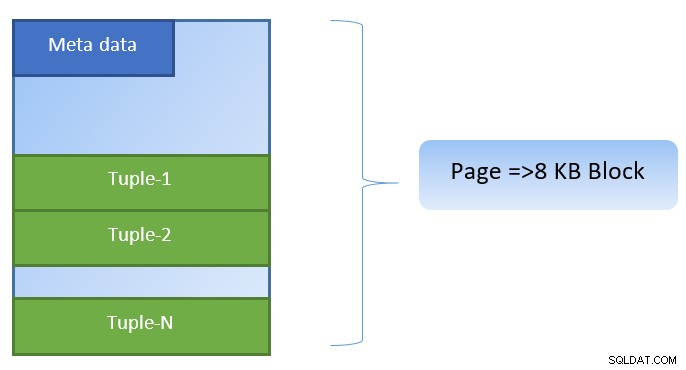
En PostgreSQL, los datos se organizan en forma de páginas de un tamaño de 8 KB, y cada una de esas páginas puede contener varias tuplas (dependiendo del tamaño de la tupla). Una representación simplista podría ser la siguiente:
PostgreSQL almacena en caché lo siguiente para acelerar el acceso a los datos:
- Datos en tablas
- Índices
- Planes de ejecución de consultas
Si bien el enfoque de almacenamiento en caché del plan de ejecución de consultas es ahorrar ciclos de CPU; el almacenamiento en caché de los datos de la tabla y los datos del índice se centra en ahorrar costosas operaciones de E/S de disco.
PostgreSQL permite a los usuarios definir cuánta memoria les gustaría reservar para mantener dicha caché para datos. La configuración relevante es shared_buffers en el archivo de configuración postgresql.conf. El valor finito de shared_buffers define cuántas páginas se pueden almacenar en caché en cualquier momento.
Cuando se ejecuta una consulta, PostgreSQL busca la página en el disco que contiene la tupla relevante y la inserta en la memoria caché shared_buffers para acceso lateral. La próxima vez que se necesite acceder a la misma tupla (o cualquier tupla en la misma página), PostgreSQL puede guardar la E/S del disco leyéndola en la memoria.
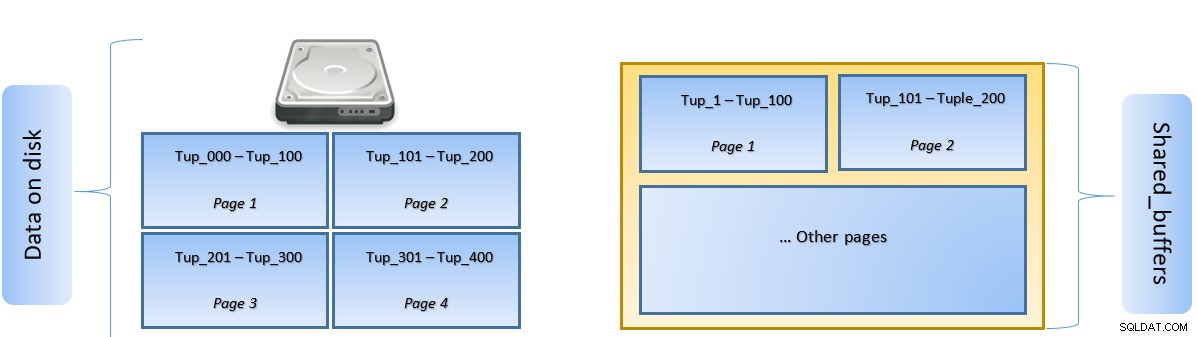
En la figura anterior, la página 1 y la página 2 de un determinado la tabla se ha almacenado en caché. En caso de que una consulta de usuario necesite acceder a tuplas entre Tuple-1 a Tuple-200, PostgreSQL puede obtenerlo de la RAM.
Sin embargo, si la consulta necesita acceder a las tuplas 250 a 350, deberá realizar operaciones de E/S de disco para la página 3 y la página 4. Cualquier acceso adicional a las tuplas 201 a 400 se obtendrá de la memoria caché y No se necesitará E/S de disco, lo que hará que la consulta sea más rápida.
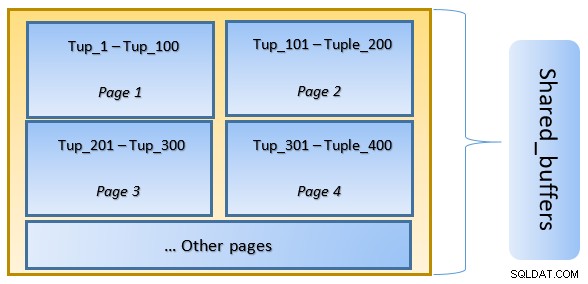
En un nivel alto, PostgreSQL sigue el algoritmo LRU (usado menos recientemente) para identifique las páginas que deben ser desalojadas del caché. En otras palabras, una página a la que se accede solo una vez tiene mayores posibilidades de desalojo (en comparación con una página a la que se accede varias veces), en caso de que PostgreSQL necesite recuperar una nueva página en caché.
Almacenamiento en caché de PostgreSQL en acción
Ejecutemos un ejemplo y veamos el impacto del caché en el rendimiento.
Inicie PostgreSQL manteniendo shared_buffer configurado en 128 MB por defecto
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startConéctese al servidor y cree una tabla ficticia tblDummy y un índice en c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Rellene datos ficticios con 200 000 tuplas, de modo que haya 10 000 p_id únicos y por cada p_id haya 200 c_id
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Reinicie el servidor para borrar el caché. Ahora ejecute una consulta y compruebe el tiempo necesario para ejecutarla
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msLuego verifique los bloques leídos del disco
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0En el ejemplo anterior, se leyeron 1000 bloques del disco para encontrar tuplas de recuento donde c_id =1. Tomó 160 ms desde que hubo E/S de disco involucradas para obtener esos registros del disco.
La ejecución es más rápida si se vuelve a ejecutar la misma consulta, ya que todos los bloques aún están en la memoria caché del servidor PostgreSQL en esta etapa
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msy los bloques se leen desde el disco frente a la caché
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000Es evidente desde arriba que dado que todos los bloques se leyeron del caché y no se requirió E/S de disco. Por lo tanto, esto también dio resultados más rápidos.
Configuración del tamaño de la caché de PostgreSQL
El tamaño de la memoria caché debe ajustarse en un entorno de producción de acuerdo con la cantidad de RAM disponible y las consultas necesarias para ejecutarse.
Como ejemplo, un búfer compartido de 128 MB puede no ser suficiente para almacenar en caché todos los datos, si la consulta fuera para obtener más tuplas:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Cambie el shared_buffer a 1024 MB para aumentar heap_blks_hit.
De hecho, teniendo en cuenta las consultas (basadas en c_id), en caso de que los datos se reorganicen, también se puede lograr una mejor proporción de aciertos de caché con un shared_buffer más pequeño.
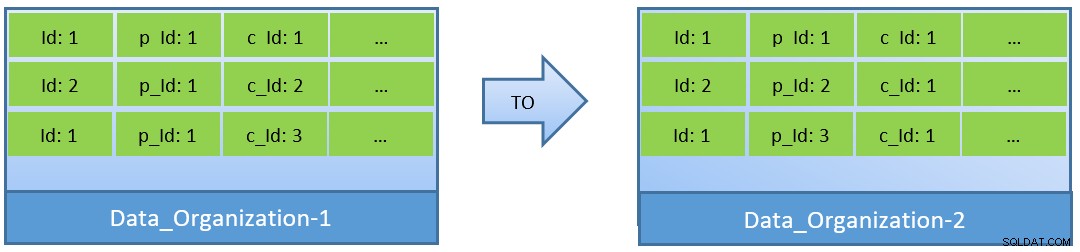
En Data_Organization-1, PostgreSQL necesitará 1000 lecturas de bloque (y consumo de caché ) para encontrar c_id=1. Por otro lado, para Data_Organisation-2, para la misma consulta, PostgreSQL necesitará solo 104 bloques.
Menos bloques requeridos para la misma consulta finalmente consumen menos caché y también optimizan el tiempo de ejecución de la consulta.
Conclusión
Mientras que shared_buffer se mantiene en el nivel de proceso de PostgreSQL, el caché de nivel de kernel también se tiene en cuenta para identificar planes de ejecución de consultas optimizados. Retomaré este tema en una serie posterior de blogs.