Leer desde la memoria siempre será más eficaz que ir al disco, por lo que para todas las tecnologías de bases de datos querrá utilizar la mayor cantidad de memoria posible. Si no está seguro acerca de la configuración o tiene un error, esto podría generar una alta utilización de la memoria o incluso un problema de falta de memoria.
En este blog, veremos cómo verificar la utilización de la memoria de PostgreSQL y qué parámetro debe tener en cuenta para ajustarla. Para esto, comencemos por ver una descripción general de la arquitectura de PostgreSQL.
Arquitectura PostgreSQL
La arquitectura de PostgreSQL se basa en tres partes fundamentales:Procesos, Memoria y Disco.
La memoria se puede clasificar en dos categorías:
- Memoria local :Lo carga cada proceso de back-end para su propio uso en el procesamiento de consultas. Se divide en sub-áreas:
- Memoria de trabajo:La memoria de trabajo se usa para clasificar tuplas por operaciones ORDER BY y DISTINCT, y para unir tablas.
- Memoria de trabajo de mantenimiento:algunos tipos de operaciones de mantenimiento utilizan esta área. Por ejemplo, VACÍO, si no está especificando autovacuum_work_mem.
- Búferes temporales:se utiliza para almacenar tablas temporales.
- Memoria compartida :Lo asigna el servidor PostgreSQL cuando se inicia y lo utilizan todos los procesos. Se divide en sub-áreas:
- Grupo de búfer compartido:Donde PostgreSQL carga páginas con tablas e índices desde el disco, para trabajar directamente desde la memoria, reduciendo el acceso al disco.
- Búfer WAL:Los datos WAL son el registro de transacciones en PostgreSQL y contienen los cambios en la base de datos. El búfer WAL es el área donde los datos WAL se almacenan temporalmente antes de escribirlos en el disco en los archivos WAL. Esto se hace cada cierto tiempo predefinido llamado punto de control. Esto es muy importante para evitar la pérdida de información en caso de falla del servidor.
- Registro de confirmación:guarda el estado de todas las transacciones para el control de concurrencia.
Cómo saber lo que está pasando
Si tiene una alta utilización de la memoria, primero debe confirmar qué proceso está generando el consumo.
Uso del comando de Linux "Superior"
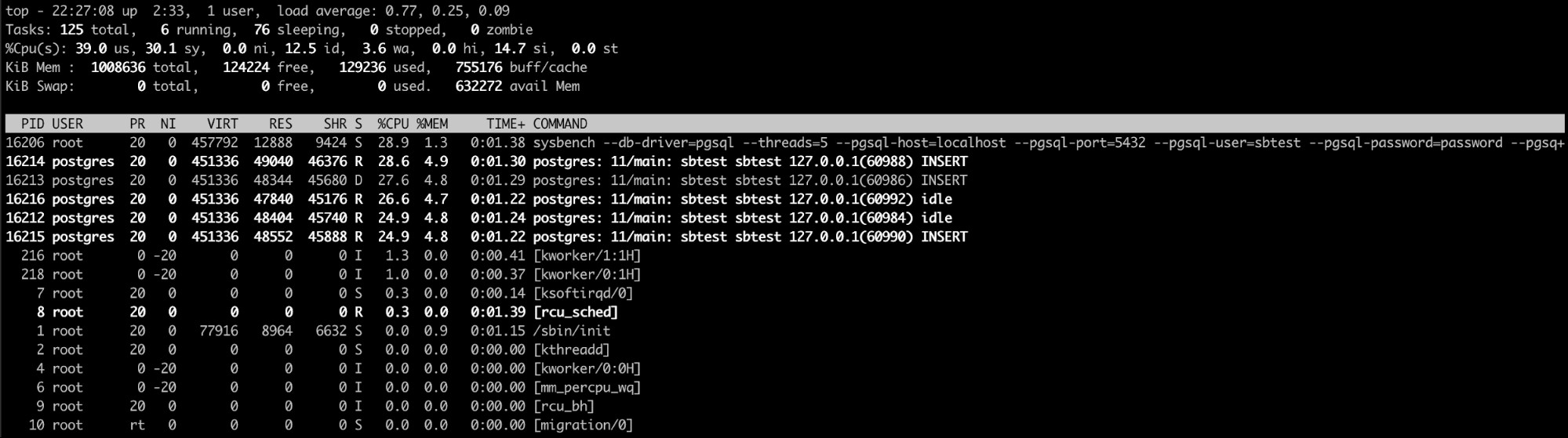
El comando superior de Linux es probablemente la mejor opción aquí (o incluso un comando similar). uno como htop). Con este comando, puede ver el proceso o los procesos que consumen demasiada memoria.
Cuando confirme que PostgreSQL es responsable de este problema, el siguiente paso es comprobar por qué.
Uso del registro de PostgreSQL
Verificar los registros de PostgreSQL y de los sistemas es definitivamente una buena manera de tener más información sobre lo que está sucediendo en su base de datos/sistema. Podrías ver mensajes como:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childSi no tiene suficiente memoria libre.
O incluso múltiples errores de mensajes de la base de datos como:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedCuando tiene algún comportamiento inesperado en el lado de la base de datos. Por lo tanto, los registros son útiles para detectar este tipo de problemas e incluso más. Puede automatizar esta supervisión analizando los archivos de registro en busca de trabajos como "FATAL", "ERROR" o "Kill", por lo que recibirá una alerta cuando suceda.
Uso de Pg_top
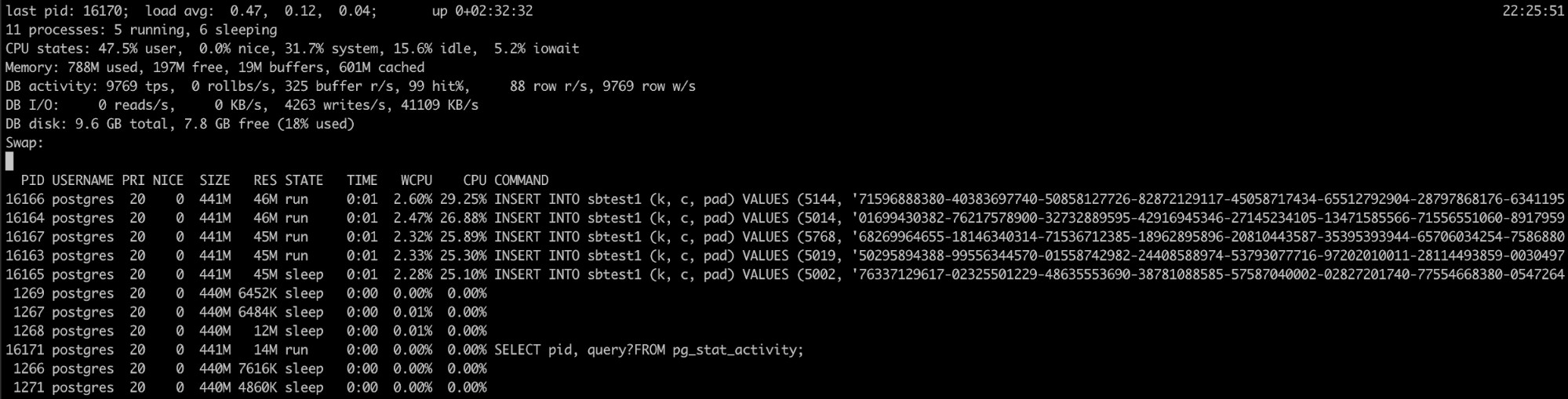
Si sabe que el proceso de PostgreSQL tiene una alta utilización de memoria, pero los registros no ayudaron, tienes otra herramienta que puede ser útil aquí, pg_top.
Esta herramienta es similar a la principal herramienta de Linux, pero es específica para PostgreSQL. Entonces, usándolo, tendrá información más detallada sobre lo que está ejecutando su base de datos, e incluso puede eliminar consultas o ejecutar un trabajo de explicación si detecta algo incorrecto. Puede encontrar más información sobre esta herramienta aquí.
Pero, ¿qué sucede si no puede detectar ningún error y la base de datos todavía usa mucha RAM? Por lo tanto, probablemente deba verificar la configuración de la base de datos.
Qué parámetros de configuración tener en cuenta
Si todo se ve bien pero aún tiene el problema de alta utilización, debe verificar la configuración para confirmar si es correcta. Entonces, los siguientes son parámetros que debes tener en cuenta en este caso.
búferes_compartidos
Esta es la cantidad de memoria que el servidor de la base de datos usa para los búferes de memoria compartida. Si este valor es demasiado bajo, la base de datos usaría más disco, lo que causaría más lentitud, pero si es demasiado alto, podría generar una alta utilización de la memoria. Según la documentación, si tiene un servidor de base de datos dedicado con 1 GB o más de RAM, un valor inicial razonable para shared_buffers es el 25 % de la memoria de su sistema.
trabajo_mem
Especifica la cantidad de memoria que utilizará ORDER BY, DISTINCT y JOIN antes de escribir en los archivos temporales en el disco. Al igual que con shared_buffers, si configuramos este parámetro demasiado bajo, podemos tener más operaciones en el disco, pero demasiado alto es peligroso para el uso de la memoria. El valor predeterminado es 4 MB.
máx_conexiones
Work_mem también va de la mano con el valor max_connections, ya que cada conexión ejecutará estas operaciones al mismo tiempo, y cada operación podrá usar tanta memoria como especifica este valor antes comienza a escribir datos en archivos temporales. Este parámetro determina el número máximo de conexiones simultáneas a nuestra base de datos, si configuramos un número elevado de conexiones y no lo tenemos en cuenta, puede empezar a tener problemas de recursos. El valor predeterminado es 100.
temp_buffers
Los búfer temporales se utilizan para almacenar las tablas temporales utilizadas en cada sesión. Este parámetro establece la cantidad máxima de memoria para esta tarea. El valor predeterminado es 8 MB.
mantenimiento_trabajo_mem
Esta es la memoria máxima que puede consumir una operación como Vacío, agregar índices o claves foráneas. Lo bueno es que solo se puede ejecutar una operación de este tipo en una sesión, y no es lo más común estar ejecutando varias de estas al mismo tiempo en el sistema. El valor predeterminado es 64 MB.
autovacuum_work_mem
La aspiradora usa la mem_trabajo_de_mantenimiento por defecto, pero podemos separarla usando este parámetro. Aquí podemos especificar la cantidad máxima de memoria que utilizará cada trabajador de vacío automático.
buffers_wal
La cantidad de memoria compartida utilizada para los datos WAL que aún no se han escrito en el disco. La configuración predeterminada es 3 % de shared_buffers, pero no menos de 64 kB ni más del tamaño de un segmento WAL, normalmente 16 MB.
Conclusión
Hay diferentes razones para tener una alta utilización de la memoria, y detectar el problema raíz puede ser una tarea que requiere mucho tiempo. En este blog, mencionamos diferentes formas de verificar la utilización de la memoria de PostgreSQL y qué parámetro debe tener en cuenta para ajustarlo y evitar el uso excesivo de la memoria.



