Este blog es la segunda parte de Implementación de una configuración de centro de datos múltiple para PostgreSQL. En este golpe, mostraremos cómo implementar PostgreSQL en este tipo de entorno y cómo realizar una conmutación por error en caso de falla del maestro utilizando la función de recuperación automática de ClusterControl.
En este punto, asumiremos que tiene conectividad entre los centros de datos (como vimos en la primera parte de este blog) y tiene los servidores necesarios para esta tarea (como también mencionamos en el parte anterior).
Implementar un clúster de PostgreSQL
Usaremos ClusterControl para esta tarea, por lo que asumiremos que lo tiene instalado (podría estar instalado en el mismo servidor Load Balancer, pero si puede usar uno diferente aún mejor).
Vaya a su servidor ClusterControl y seleccione la opción 'Implementar'. Si ya tiene una instancia de PostgreSQL ejecutándose, debe seleccionar 'Importar servidor/base de datos existente' en su lugar.
Al seleccionar PostgreSQL, debe especificar Usuario, Clave o Contraseña y puerto para conectarse por SSH a nuestros hosts PostgreSQL. También necesita el nombre de su nuevo clúster y si desea que ClusterControl instale el software y las configuraciones correspondientes por usted.
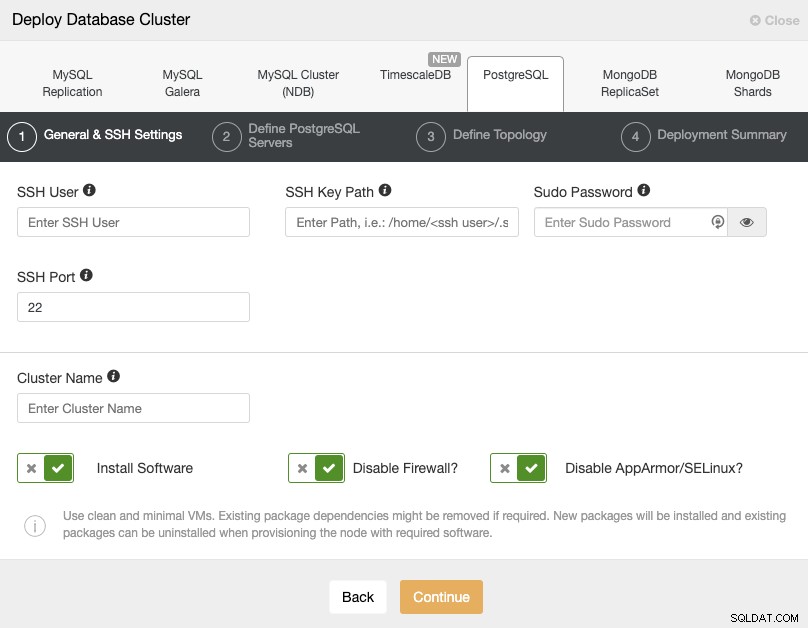
Consulte aquí los requisitos de usuario de ClusterControl para esta tarea, pero si siguió En el blog anterior, debe usar el usuario 'remoto' aquí y el puerto SSH correcto (como mencionamos, se recomienda usar uno diferente si está usando la dirección IP pública para acceder a él en lugar de una VPN).
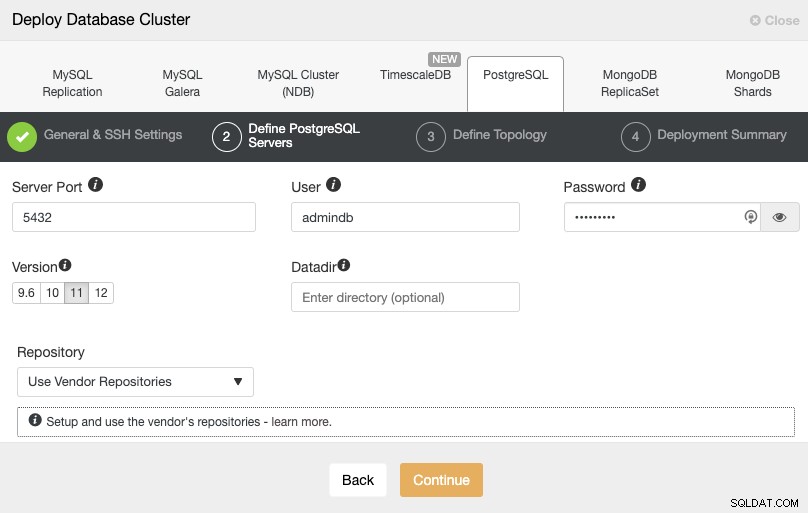
Después de configurar la información de acceso SSH, debe definir el usuario de la base de datos, versión y datadir (opcional). También puede especificar qué repositorio usar. En el siguiente paso, debe agregar sus servidores al clúster que va a crear.
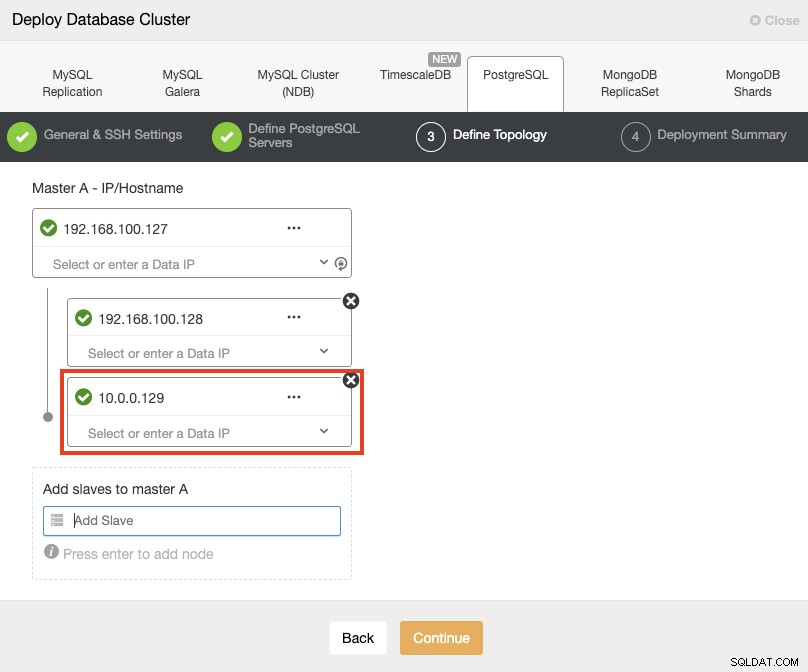
Al agregar sus servidores, puede ingresar la IP o el nombre de host. En esta parte, usará las direcciones IP públicas de sus servidores y, como puede ver en el cuadro rojo, estoy usando una red diferente para el segundo nodo en espera. ClusterControl no tiene ninguna limitación sobre la red a utilizar. El único requisito para esto es tener acceso SSH al nodo.
Entonces, siguiendo nuestro ejemplo anterior, estas direcciones IP deberían ser:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)En el último paso, puede elegir si su replicación será Sincrónica o Asincrónica.
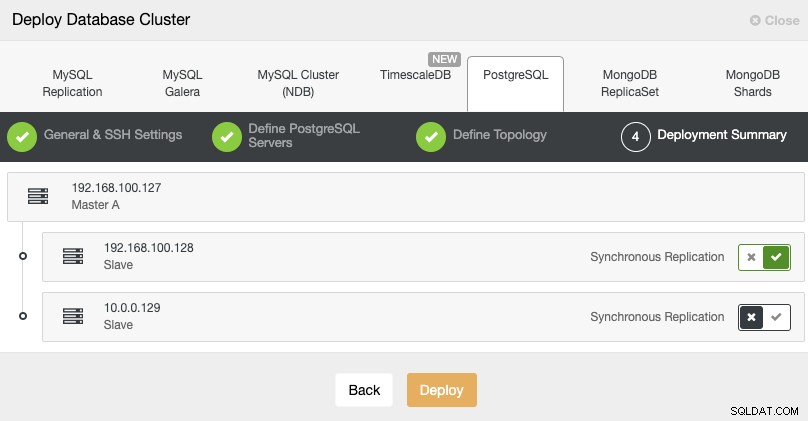
En este caso, es importante utilizar la replicación asíncrona para su nodo remoto De lo contrario, su clúster podría verse afectado por la latencia o por problemas de red.
Puede monitorear el estado de la creación de su nuevo clúster desde el monitor de actividad de ClusterControl.
Una vez finalizada la tarea, puede ver su nuevo clúster de PostgreSQL en la pantalla principal de ClusterControl.

Agregar un balanceador de carga de PostgreSQL (HAProxy)
Una vez que haya creado su clúster, puede realizar varias tareas en él, como agregar un balanceador de carga (HAProxy) o una nueva réplica.
Para seguir nuestro ejemplo anterior, agreguemos un balanceador de carga que, como mencionamos, lo ayudará a administrar su entorno HA. Para ello, vaya a ClusterControl -> Seleccione Clúster de PostgreSQL -> Acciones de clúster -> Agregar equilibrador de carga.
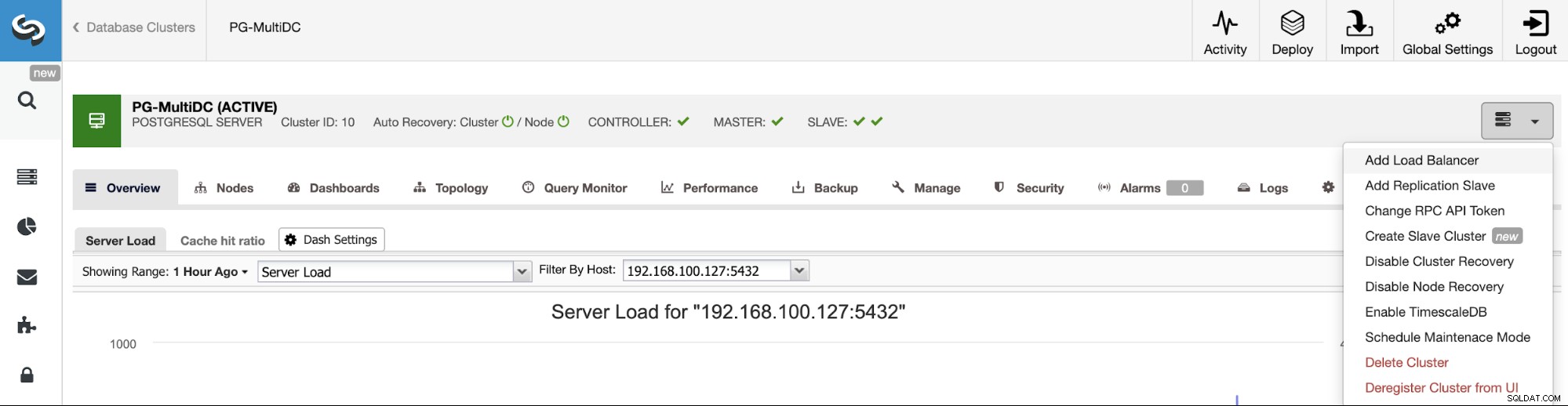
Aquí debe agregar la información que utilizará ClusterControl para instalar y configurar su Equilibrador de carga HAProxy. Este Load Balancer se puede instalar en el mismo servidor de ClusterControl, pero si puedes usar uno diferente, mejor.
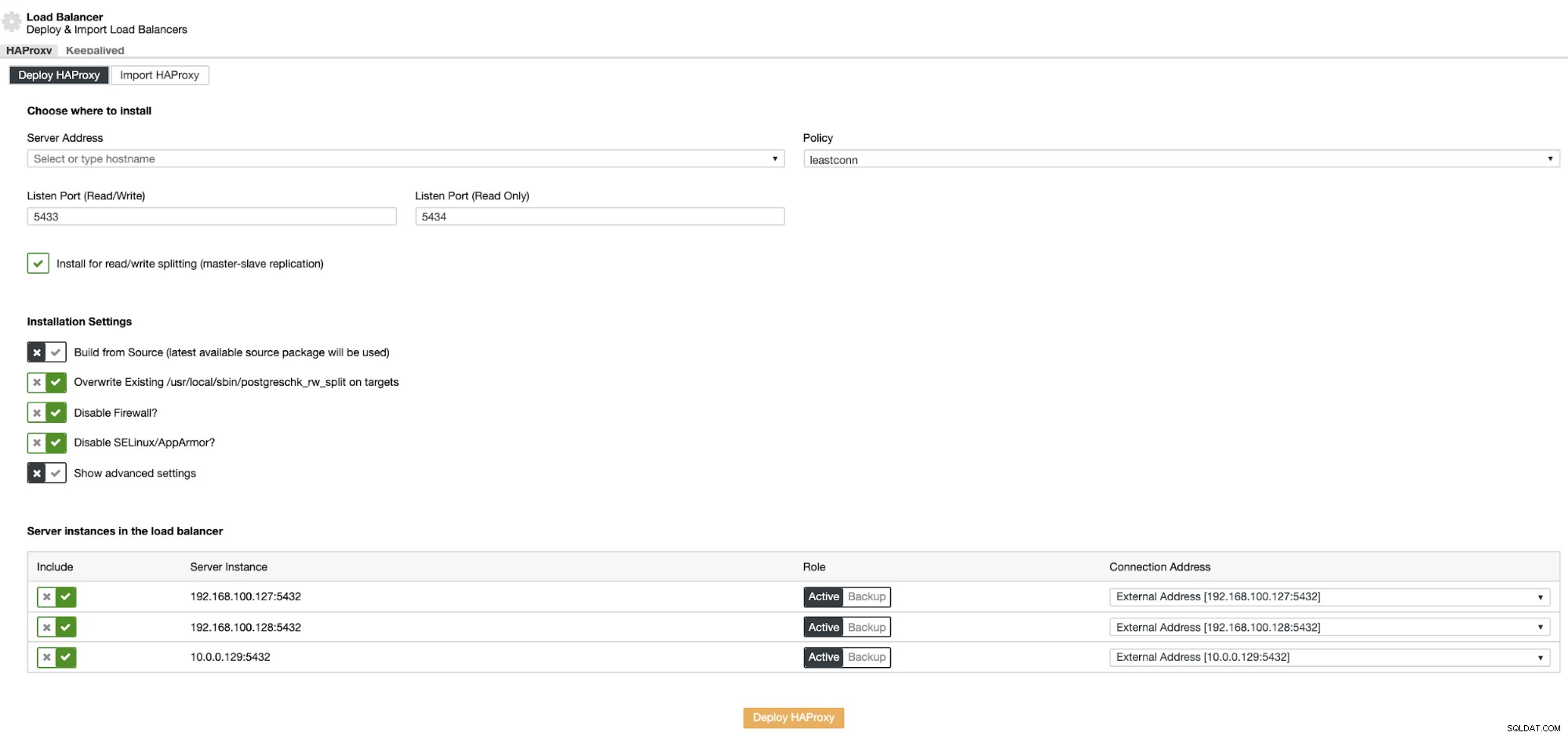
La información que debe introducir es:
Acción:Implementar o Importar.
Dirección del servidor:dirección IP para su servidor HAProxy (puede ser la misma dirección IP de ClusterControl).
Puerto de escucha (lectura/escritura):puerto para el modo de lectura/escritura.
Puerto de escucha (solo lectura):Puerto para el modo de solo lectura.
Política:Puede ser:
- leastconn:El servidor con el menor número de conexiones recibe la conexión.
- roundrobin:Cada servidor se utiliza por turnos, según su peso.
- fuente:la dirección IP de origen se codifica y se divide por el peso total de los servidores en ejecución para designar qué servidor recibirá la solicitud.
Instalar para división de lectura/escritura:para replicación maestro-esclavo.
Crear desde la fuente:puede elegir Instalar desde un administrador de paquetes o compilar desde la fuente.
Y debe seleccionar qué servidores desea agregar a la configuración de HAProxy.
Además, puede configurar Ajustes avanzados como Usuario administrador, Nombre de servidor, Tiempos de espera y más.
Cuando termine la configuración y confirme la implementación, puede seguir el progreso en la sección Actividad en la interfaz de usuario de ClusterControl.
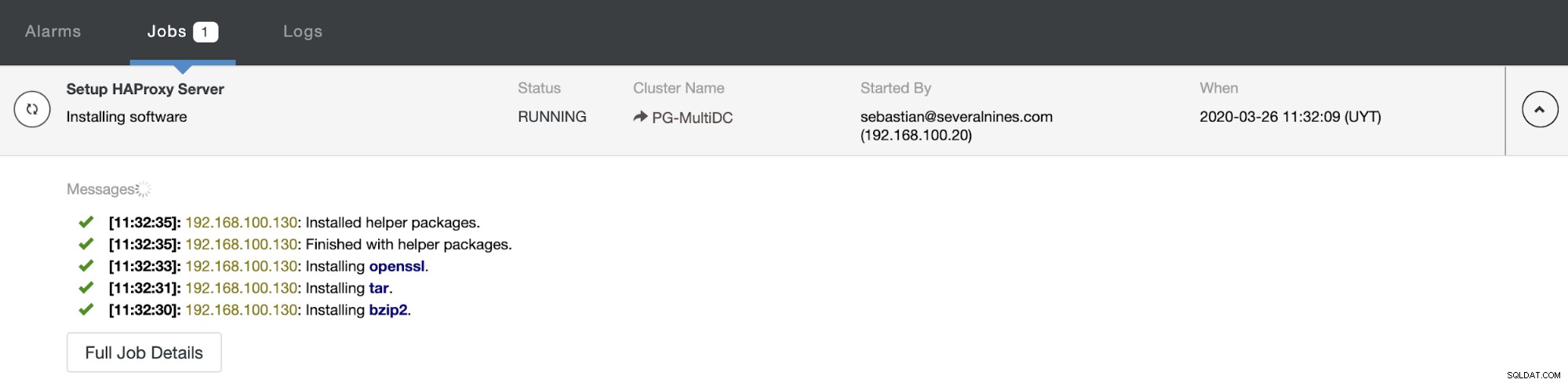
Y cuando esto termine, puede ir a ClusterControl -> Nodes -> nodo HAProxy y verifique el estado actual.
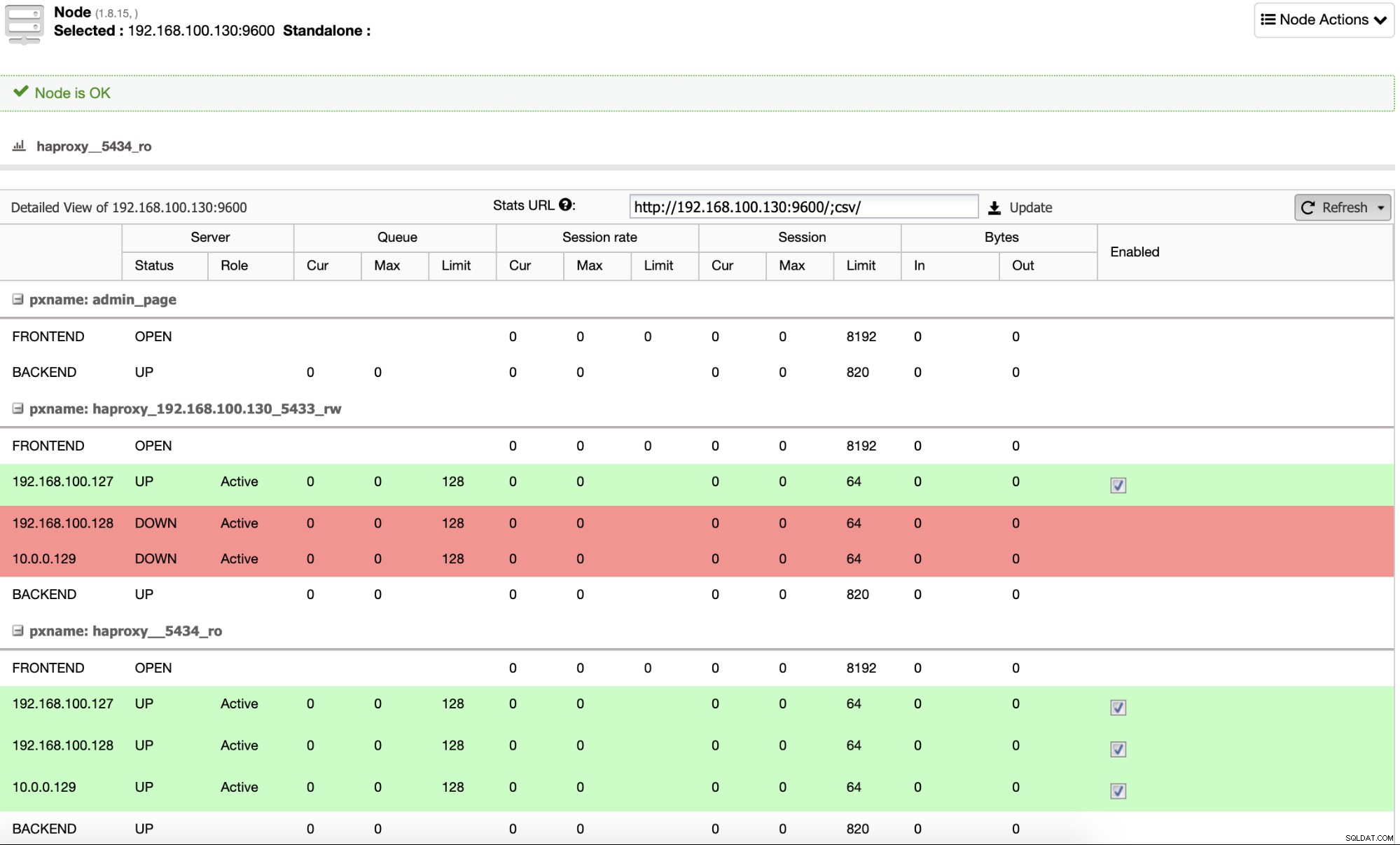
De forma predeterminada, ClusterControl configura HAProxy con dos puertos diferentes, uno para lectura Write, que servirá para que la aplicación o usuario escriba (y lea) datos, y otro de Read-Only, que servirá para equilibrar el tráfico de lectura entre todos los nodos. En el puerto de Lectura-Escritura, solo el nodo maestro está habilitado, y en caso de falla del maestro, ClusterControl promoverá el esclavo más avanzado a maestro y reconfigurará este puerto para deshabilitar el antiguo maestro y habilitar el nuevo. De esta manera, su aplicación aún puede funcionar en caso de una falla de la base de datos maestra, ya que Load Balancer redirige el tráfico al nodo correcto.
También puede monitorear sus servidores HAProxy revisando la sección Panel de control.
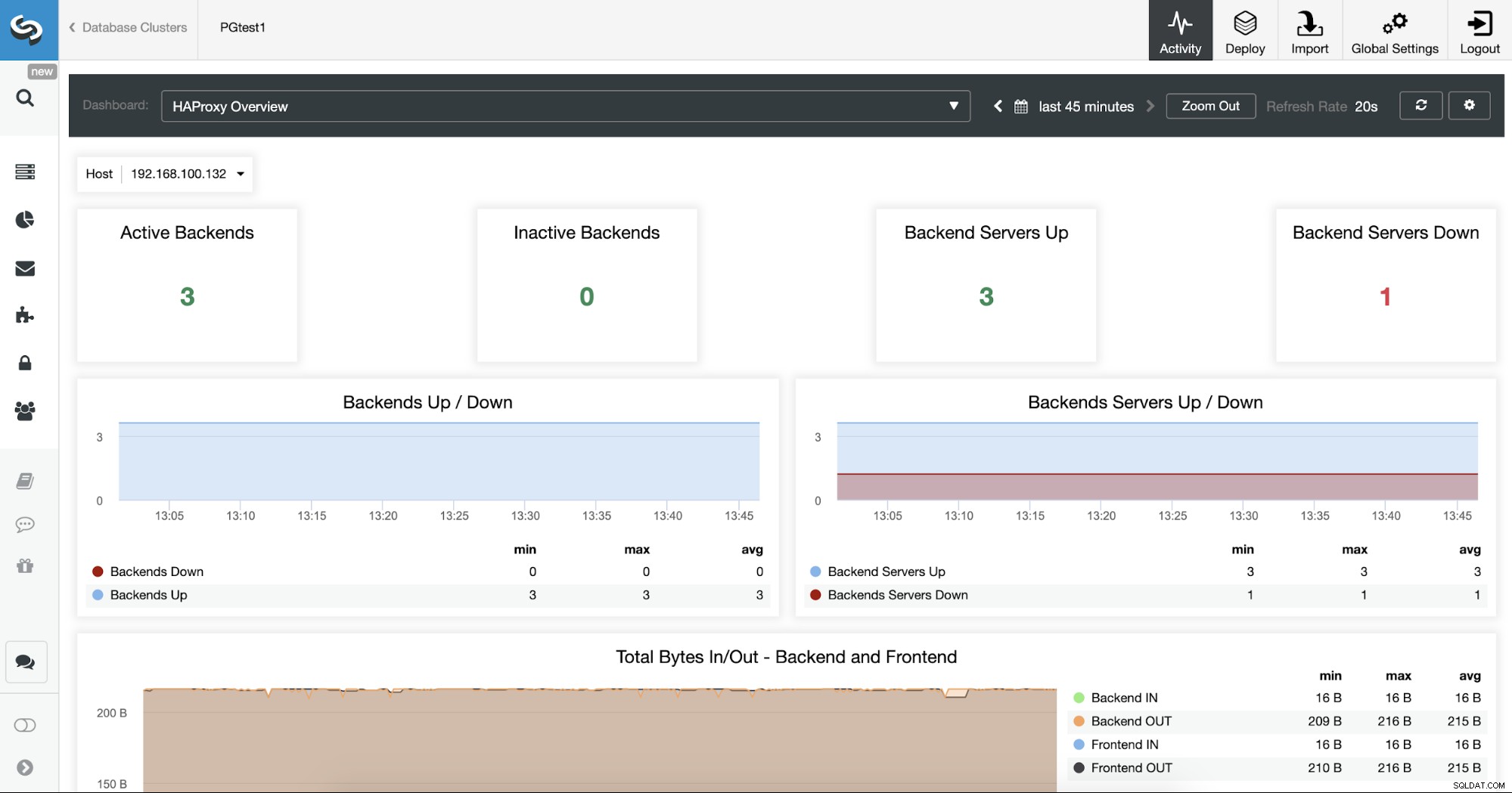
Ahora, puede mejorar su diseño HA agregando un nuevo nodo HAProxy en el centro de datos remoto y configurar el servicio Keepalived entre ellos. Keepalived le permitirá usar una dirección IP virtual que se asigna al nodo Load Balancer activo. Si este nodo falla, esta IP virtual se migrará al nodo HAProxy secundario, por lo que tener esta IP configurada en su aplicación le permitirá mantener todo funcionando en caso de un problema con Load Balancer.
Toda esta configuración se puede realizar mediante ClusterControl.
Conclusión
Si sigue este blog de dos partes, puede implementar una configuración de múltiples centros de datos para PostgreSQL con alta disponibilidad y conectividad SSH entre el centro de datos, para evitar la complejidad de una configuración de VPN.
Al usar la replicación asíncrona para el nodo remoto, evitará cualquier problema relacionado con la latencia y el rendimiento de la red, y al usar ClusterControl, tendrá una conmutación por error automática (o manual) en caso de falla (entre otras funciones). Esta podría ser la forma más sencilla de llegar a esta topología y esperamos que le resulte útil.