Como anunciamos recientemente, ClusterControl 1.7.4 tiene una nueva característica llamada replicación de clúster a clúster. Le permite tener una replicación ejecutándose entre dos clústeres autónomos. Para obtener información más detallada, consulte el anuncio mencionado anteriormente.
Echaremos un vistazo a cómo utilizar esta nueva función para un clúster de PostgreSQL existente. Para esta tarea, supondremos que tiene instalado ClusterControl y que Master Cluster se implementó usándolo.
Requisitos para el Master Cluster
Hay algunos requisitos para que Master Cluster funcione:
- PostgreSQL 9.6 o posterior.
- Debe haber un servidor PostgreSQL con el rol de ClusterControl 'Master'.
- Al configurar el clúster secundario, las credenciales de administrador deben ser idénticas a las del clúster maestro.
Preparación del grupo maestro
El Master Cluster debe cumplir con los requisitos mencionados anteriormente.
Sobre el primer requisito, asegúrese de estar usando la versión correcta de PostgreSQL en el clúster maestro y elija lo mismo para el clúster esclavo.
$ psql
postgres=# select version();
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitSi necesita asignar la función principal a un nodo específico, puede hacerlo desde la interfaz de usuario de ClusterControl. Vaya a ClusterControl -> Seleccione Master Cluster -> Nodos -> Seleccione el nodo -> Acciones de nodo -> Promover esclavo.
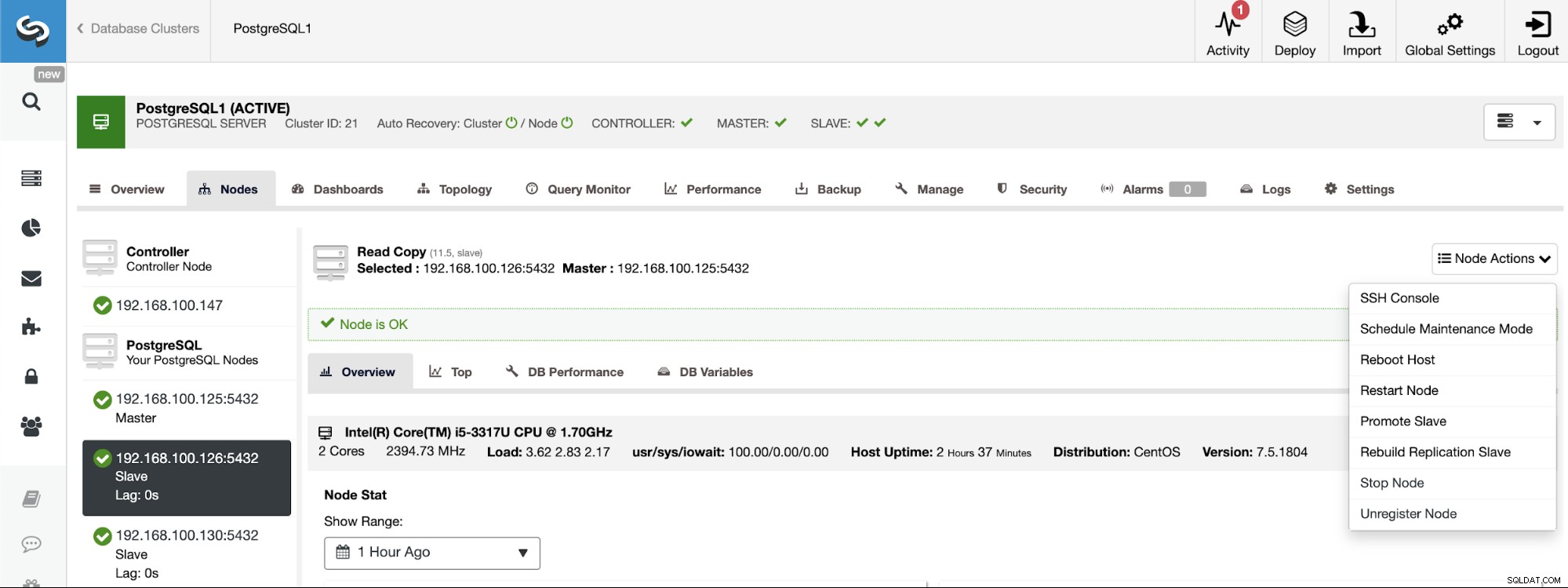
Y finalmente, durante la creación del clúster esclavo, debe usar el mismo administrador credenciales que está utilizando actualmente en el Master Cluster. Verás dónde agregarlo en la siguiente sección.
Creación del clúster esclavo desde la interfaz de usuario de ClusterControl
Para crear un nuevo clúster esclavo, vaya a ClusterControl -> Seleccionar clúster -> Acciones del clúster -> Crear clúster esclavo.
El clúster esclavo se creará mediante la transmisión de datos del clúster maestro actual.
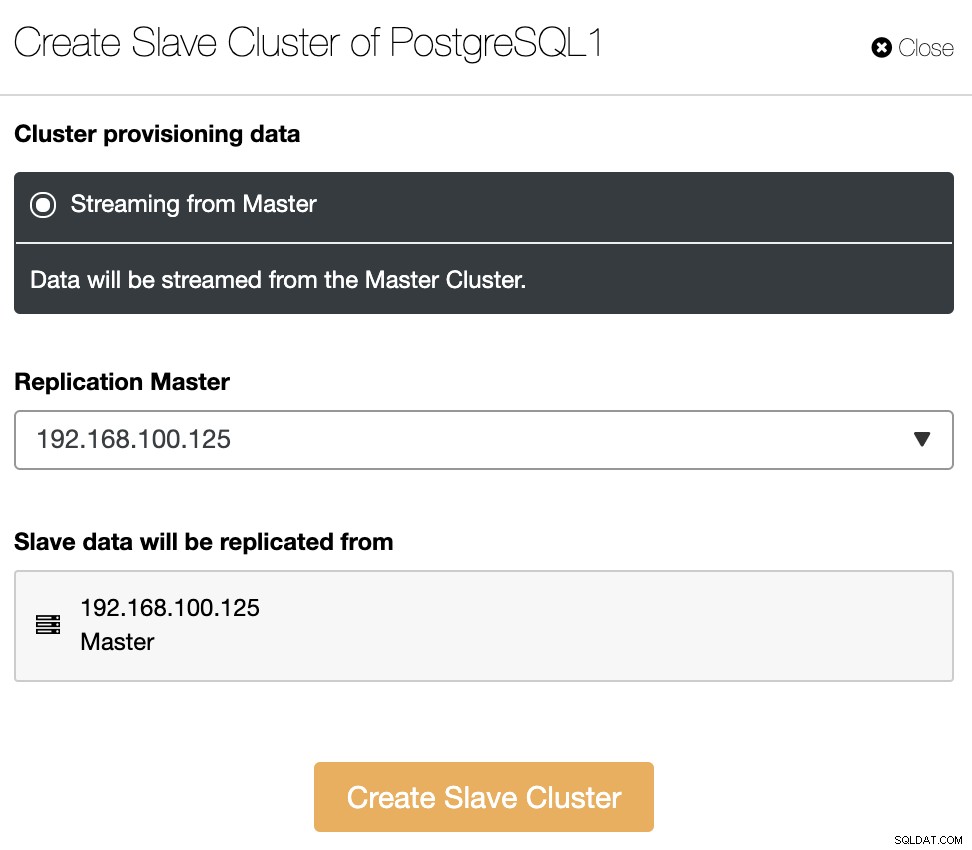
En esta sección, también debe elegir el nodo maestro del clúster actual a partir del cual se replicarán los datos.
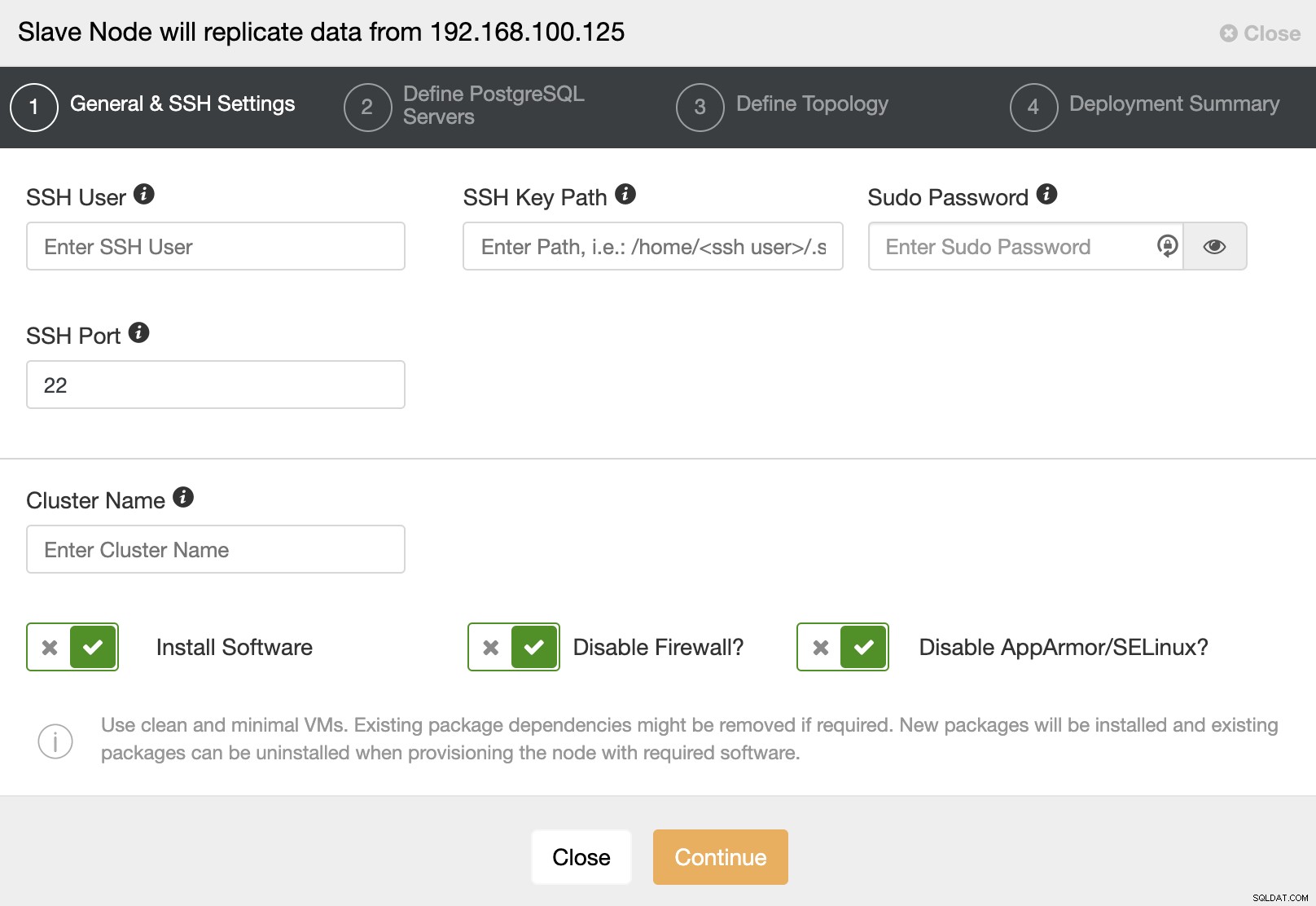
Cuando vaya al siguiente paso, debe especificar Usuario, Clave o Contraseña y puerto para conectarte por SSH a tus servidores. También necesita un nombre para su Slave Cluster y si desea que ClusterControl instale el software y las configuraciones correspondientes por usted.
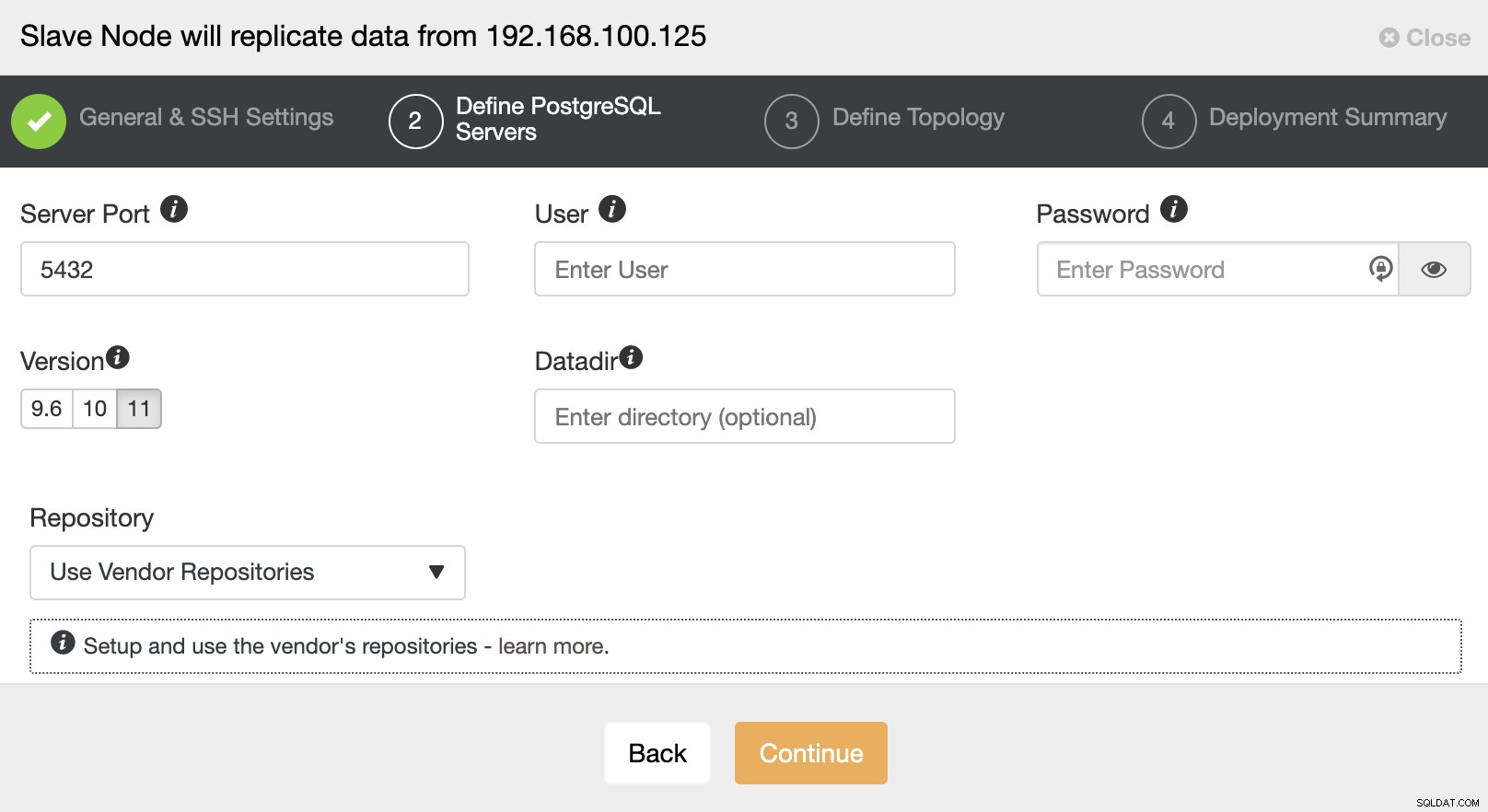
Después de configurar la información de acceso SSH, debe definir la versión de la base de datos, datadir, puerto y credenciales de administrador. Como usará la replicación de transmisión, asegúrese de usar la misma versión de la base de datos y, como mencionamos anteriormente, las credenciales deben ser las mismas que usa el Master Cluster. También puede especificar qué repositorio usar.
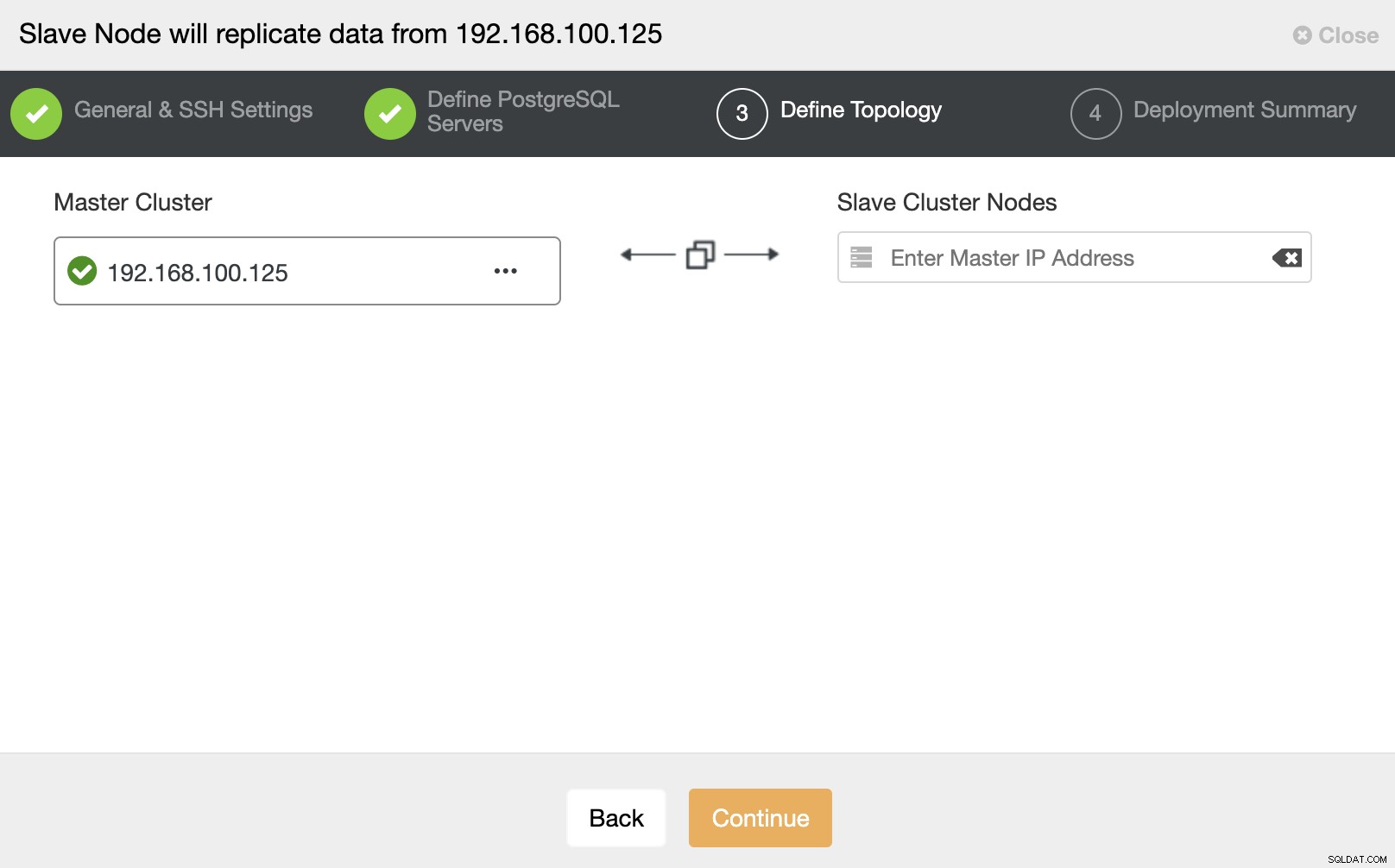
En este paso, debe agregar el servidor al nuevo clúster esclavo . Para esta tarea, puede ingresar tanto la dirección IP como el nombre de host del nodo de la base de datos.
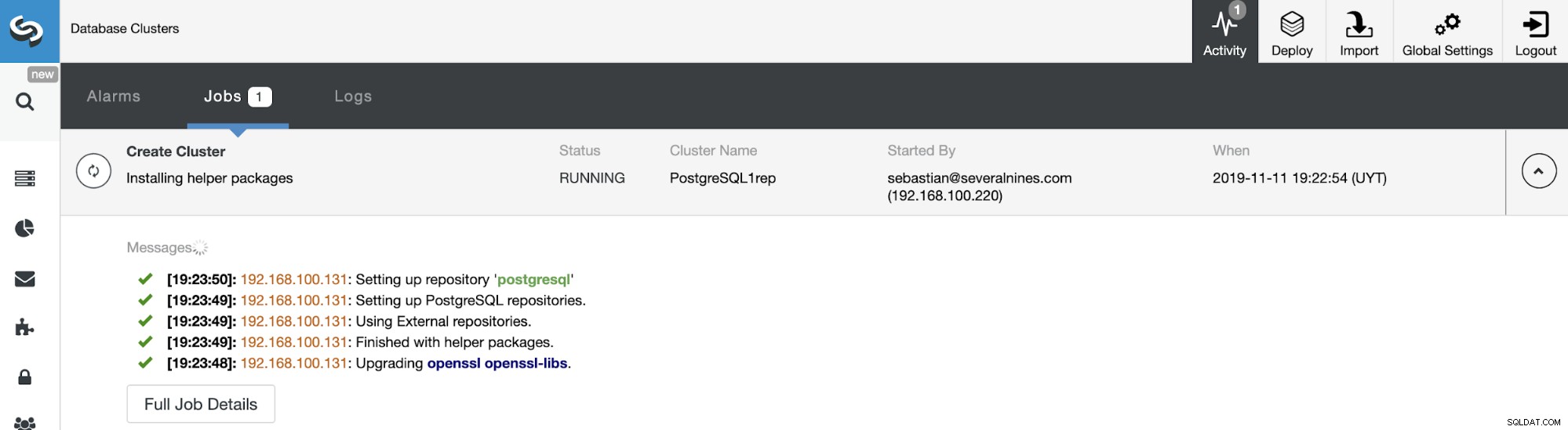
Puede monitorear el estado de la creación de su nuevo Slave Cluster desde el Monitor de actividad de ClusterControl. Una vez finalizada la tarea, puede ver el clúster en la pantalla principal de ClusterControl.
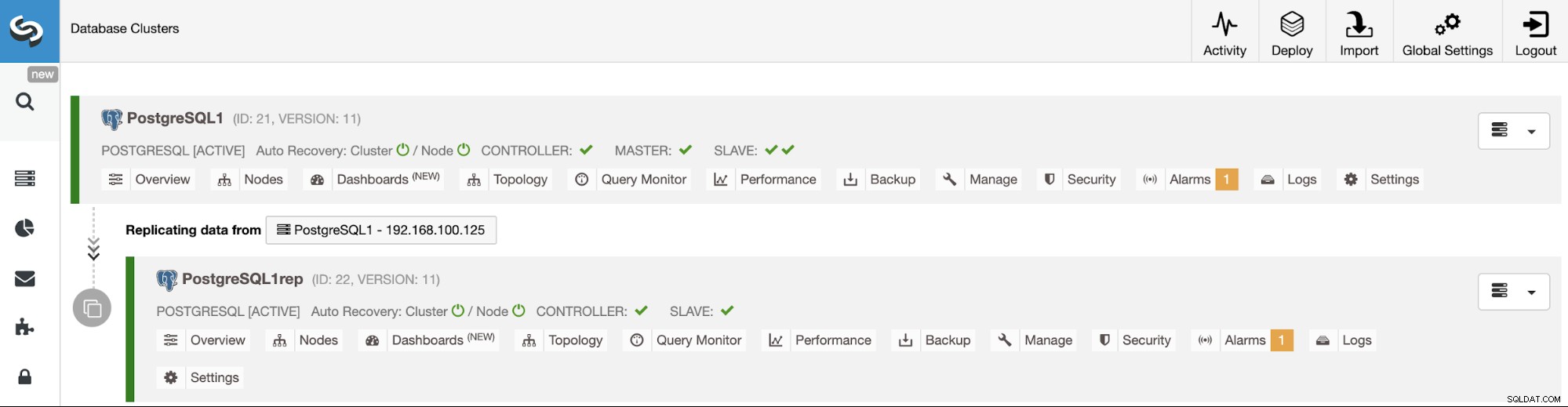
Gestión de la replicación de clúster a clúster mediante la interfaz de usuario de ClusterControl
Ahora que tiene su replicación de clúster a clúster en funcionamiento, hay diferentes acciones para realizar en esta topología usando ClusterControl.
Reconstrucción de un clúster esclavo
Para reconstruir un clúster esclavo, vaya a ClusterControl -> Seleccionar clúster esclavo -> Nodos -> Elija el nodo conectado al clúster maestro -> Acciones de nodo -> Reconstruir esclavo de replicación.
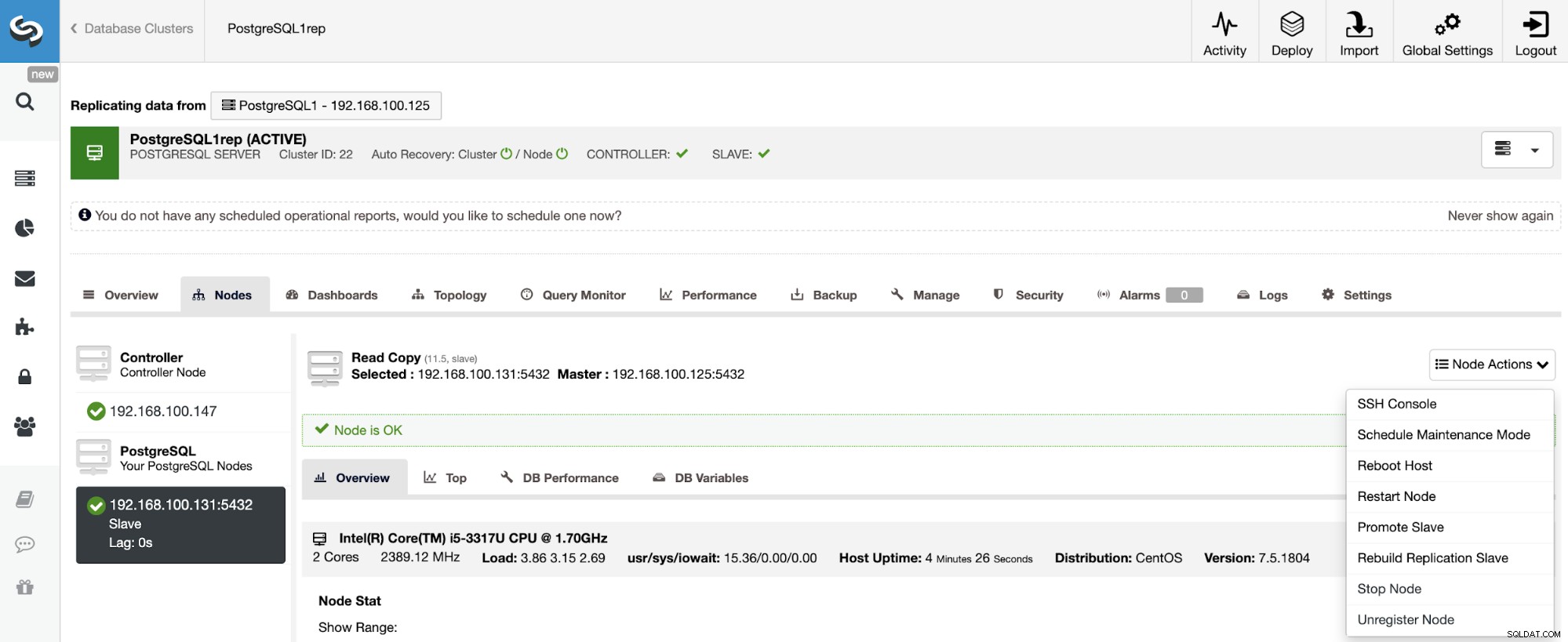
ClusterControl realizará los siguientes pasos:
- Detener servidor PostgreSQL
- Eliminar contenido de su directorio de datos
- Transmita una copia de seguridad del Maestro al Esclavo usando pg_basebackup
- Iniciar el esclavo
Detener/Iniciar esclavo de replicación
Detener e iniciar la replicación en PostgreSQL significa pausarla y reanudarla, pero usamos estos términos para ser coherentes con otras tecnologías de bases de datos que admitimos.
Esta función estará disponible para su uso desde la interfaz de usuario de ClusterControl pronto. Esta acción utilizará las funciones pg_wal_replay_pause y pg_wal_replay_resume de PostgreSQL para realizar esta tarea.
Mientras tanto, puede utilizar una solución alternativa para detener e iniciar el esclavo de replicación, deteniendo e iniciando el nodo de la base de datos de una manera sencilla mediante ClusterControl.
Vaya a ClusterControl -> Seleccione Clúster esclavo -> Nodos -> Elija el Nodo -> Acciones de nodo -> Detener nodo/Iniciar nodo. Esta acción detendrá/iniciará el servicio de la base de datos directamente.
Gestión de la replicación de clúster a clúster mediante la CLI de ClusterControl
En la sección anterior, pudo ver cómo administrar una replicación de clúster a clúster mediante la interfaz de usuario de ClusterControl. Ahora, veamos cómo hacerlo usando la línea de comando.
Nota:Como mencionamos al comienzo de este blog, asumiremos que tiene instalado ClusterControl y que Master Cluster se implementó usándolo.
Crear el clúster esclavo
Primero, veamos un comando de ejemplo para crear un clúster esclavo mediante la CLI de ClusterControl:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logAhora que tiene su proceso de creación de esclavos en ejecución, veamos cada parámetro utilizado:
- Cluster:para enumerar y manipular clústeres.
- Crear:crea e instala un nuevo clúster.
- Nombre del clúster:el nombre del nuevo clúster esclavo.
- Cluster-type:El tipo de clúster a instalar.
- Proveedor-version:La versión del software.
- Nodos:Lista de los nuevos nodos en el clúster esclavo.
- Os-user:El nombre de usuario para los comandos SSH.
- Os-key-file:el archivo de clave que se utilizará para la conexión SSH.
- Db-admin:El nombre de usuario del administrador de la base de datos.
- Db-admin-passwd:La contraseña para el administrador de la base de datos.
- Remote-cluster-id:ID de clúster maestro para la replicación de clúster a clúster.
- Registro:esperar y monitorear mensajes de trabajo.
Usando el indicador --log, podrá ver los registros en tiempo real:
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.Reconstrucción de un clúster esclavo
Puede reconstruir un clúster esclavo con el siguiente comando:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logLos parámetros son:
- Replicación:Para monitorear y controlar la replicación de datos.
- Etapa:etapa/reconstrucción de un esclavo de replicación.
- Maestro:el maestro de replicación en el clúster maestro.
- Esclavo:El esclavo de replicación en el clúster esclavo.
- Cluster-id:ID del clúster esclavo.
- Remote-cluster-id:El ID del clúster maestro.
- Registro:esperar y monitorear mensajes de trabajo.
El registro de trabajo debe ser similar a este:
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.Detener/Iniciar esclavo de replicación
Como mencionamos en la sección de interfaz de usuario, detener e iniciar la replicación en PostgreSQL significa pausarla y reanudarla, pero usamos estos términos para mantener el paralelismo con otras tecnologías.
Puede detenerse para replicar los datos del Master Cluster de esta manera:
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logVerá esto:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().Y ahora, puedes empezarlo de nuevo:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logEntonces, verás:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().Ahora, revisemos los parámetros usados.
- Replicación:Para monitorear y controlar la replicación de datos.
- Detener/Iniciar:Para hacer que el esclavo detenga/comience a replicar.
- Esclavo:el nodo esclavo de replicación.
- Cluster-id:el ID del clúster en el que se encuentra el nodo esclavo.
- Registro:esperar y monitorear mensajes de trabajo.
Conclusión
Esta nueva característica de ClusterControl le permitirá configurar rápidamente la replicación entre diferentes clústeres de PostgreSQL y administrar la configuración de una manera fácil y amigable. El equipo de desarrollo de Variousnines está trabajando para mejorar esta función, por lo que cualquier idea o sugerencia será bienvenida.