Hoy en día, es común ver una gran cantidad de datos en la base de datos de una empresa, pero dependiendo del tamaño, puede ser difícil de administrar y el rendimiento puede verse afectado durante el alto tráfico si no lo configuramos o implementamos de manera correcta. . En general, si tenemos una base de datos enorme y queremos tener un tiempo de respuesta bajo, querremos escalarla. PostgreSQL no es la excepción a este punto. Hay muchos enfoques disponibles para escalar PostgreSQL, pero primero, aprendamos qué es escalar.
La escalabilidad es la propiedad de un sistema/base de datos para manejar una cantidad creciente de demandas mediante la adición de recursos.
Los motivos de esta cantidad de demandas pueden ser temporales, por ejemplo, si estamos lanzando un descuento en una venta, o permanentes, por aumento de clientes o empleados. En cualquier caso, deberíamos poder agregar o quitar recursos para administrar estos cambios en las demandas o el aumento en el tráfico.
En este blog, veremos cómo podemos escalar nuestra base de datos PostgreSQL y cuándo debemos hacerlo.
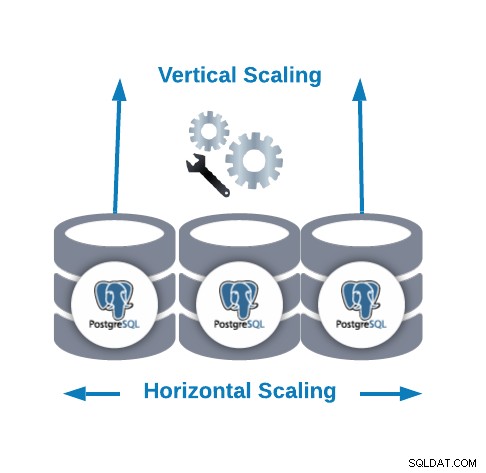
Escalado horizontal frente a escalado vertical
Hay dos formas principales de escalar nuestra base de datos...
- Escalado horizontal (scale-out):se realiza agregando más nodos de base de datos creando o aumentando un clúster de base de datos.
- Escalado vertical (ampliación):se realiza agregando más recursos de hardware (CPU, memoria, disco) a un nodo de base de datos existente.
Para el escalado horizontal, podemos agregar más nodos de base de datos como nodos esclavos. Nos puede ayudar a mejorar el rendimiento de lectura equilibrando el tráfico entre los nodos. En este caso, necesitaremos agregar un balanceador de carga para distribuir el tráfico al nodo correcto según la política y el estado del nodo.
Para evitar un único punto de falla al agregar solo un balanceador de carga, debemos considerar agregar dos o más nodos de balanceador de carga y usar alguna herramienta como "Keepalived", para garantizar la disponibilidad.
Como PostgreSQL no tiene soporte multimaestro nativo, si queremos implementarlo para mejorar el rendimiento de escritura, necesitaremos usar una herramienta externa para esta tarea.
Para Vertical Scaling, podría ser necesario cambiar algún parámetro de configuración para permitir que PostgreSQL use un recurso de hardware nuevo o mejor. Veamos algunos de estos parámetros de la documentación de PostgreSQL.
- work_mem:especifica la cantidad de memoria que usarán las operaciones de clasificación internas y las tablas hash antes de escribir en archivos de disco temporales. Varias sesiones en ejecución podrían estar realizando este tipo de operaciones al mismo tiempo, por lo que la memoria total utilizada podría ser muchas veces el valor de work_mem.
- maintenance_work_mem:especifica la cantidad máxima de memoria que usarán las operaciones de mantenimiento, como VACUUM, CREATE INDEX y ALTER TABLE ADD FOREIGN KEY. Las configuraciones más grandes pueden mejorar el rendimiento para la limpieza y la restauración de volcados de bases de datos.
- autovacuum_work_mem:especifica la cantidad máxima de memoria que utilizará cada proceso de trabajo de autovacuum.
- autovacuum_max_workers:especifica el número máximo de procesos de autovacuum que pueden estar ejecutándose en cualquier momento.
- max_worker_processes:establece la cantidad máxima de procesos en segundo plano que el sistema puede admitir. Especifique el límite del proceso como aspiración, puntos de control y más trabajos de mantenimiento.
- max_parallel_workers:establece la cantidad máxima de trabajadores que el sistema puede admitir para operaciones paralelas. Los trabajadores paralelos se toman del conjunto de procesos de trabajo establecidos por el parámetro anterior.
- max_parallel_maintenance_workers:establece la cantidad máxima de trabajadores paralelos que se pueden iniciar con un solo comando de utilidad. Actualmente, el único comando de utilidad paralela que admite el uso de trabajadores paralelos es CREATE INDEX, y solo cuando se crea un índice de árbol B.
- efective_cache_size:establece la suposición del planificador sobre el tamaño efectivo de la caché de disco que está disponible para una única consulta. Esto se tiene en cuenta en las estimaciones del costo de usar un índice; un valor más alto hace que sea más probable que se usen escaneos de índice, un valor más bajo hace que sea más probable que se usen escaneos secuenciales.
- shared_buffers:establece la cantidad de memoria que utiliza el servidor de la base de datos para los búferes de memoria compartida. Por lo general, se necesitan configuraciones significativamente más altas que el mínimo para un buen rendimiento.
- temp_buffers:establece el número máximo de búferes temporales utilizados por cada sesión de base de datos. Estos son búferes locales de sesión que se usan solo para acceder a tablas temporales.
- efective_io_concurrency:establece la cantidad de operaciones de E/S de disco simultáneas que PostgreSQL espera que se puedan ejecutar simultáneamente. Elevar este valor aumentará la cantidad de operaciones de E/S que cualquier sesión individual de PostgreSQL intenta iniciar en paralelo. Actualmente, esta configuración solo afecta a los análisis de montón de mapas de bits.
- max_connections:determina el número máximo de conexiones simultáneas al servidor de la base de datos. El aumento de este parámetro permite que PostgreSQL ejecute más procesos de back-end simultáneamente.
En este punto, hay una pregunta que debemos hacernos. ¿Cómo podemos saber si necesitamos escalar nuestra base de datos y cómo podemos saber la mejor manera de hacerlo?
Monitoreo
Escalar nuestra base de datos PostgreSQL es un proceso complejo, por lo que debemos revisar algunas métricas para poder determinar la mejor estrategia para escalarla.
Podemos monitorear el uso de la CPU, la memoria y el disco para determinar si hay algún problema de configuración o si realmente necesitamos escalar nuestra base de datos. Por ejemplo, si vemos una carga alta en el servidor pero la actividad de la base de datos es baja, probablemente no sea necesario escalarlo, solo necesitamos verificar los parámetros de configuración para que coincidan con nuestros recursos de hardware.
Verificar el espacio en disco utilizado por el nodo PostgreSQL por base de datos puede ayudarnos a confirmar si necesitamos más disco o incluso una partición de tabla. Para verificar el espacio en disco utilizado por una base de datos/tabla, podemos usar alguna función de PostgreSQL como pg_database_size o pg_table_size.
Desde el lado de la base de datos, debemos verificar
- Cantidad de conexión
- Ejecutar consultas
- Uso del índice
- Inflar
- Retraso de replicación
Estas podrían ser métricas claras para confirmar si es necesario escalar nuestra base de datos.
ClusterControl como Sistema de Escalado y Monitoreo
ClusterControl puede ayudarnos a hacer frente a las dos formas de escalado que vimos anteriormente y a monitorear todas las métricas necesarias para confirmar el requisito de escalado. Veamos cómo...
Si aún no usa ClusterControl, puede instalarlo e implementar o importar su base de datos PostgreSQL actual seleccionando la opción "Importar" y siga los pasos para aprovechar todas las funciones de ClusterControl, como copias de seguridad, conmutación por error automática, alertas, monitoreo, y más.
Escalado horizontal
Para el escalado horizontal, si vamos a las acciones del clúster y seleccionamos "Agregar esclavo de replicación", podemos crear una nueva réplica desde cero o agregar una base de datos PostgreSQL existente como réplica.
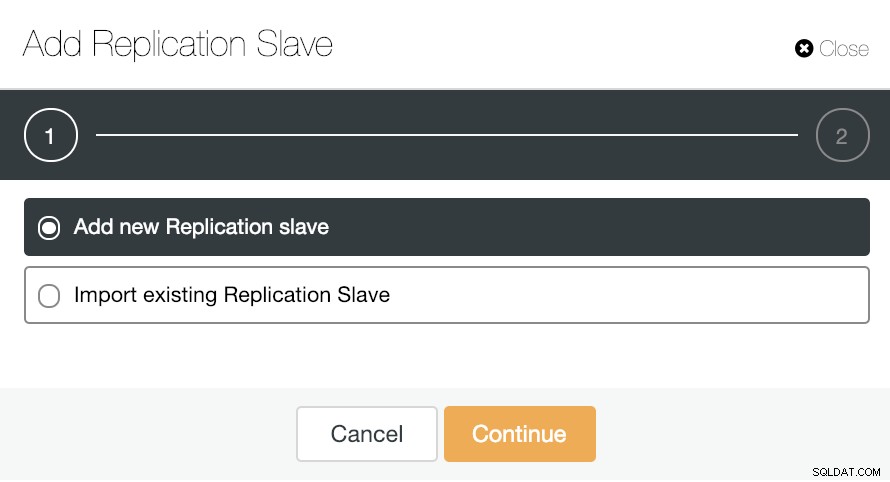
Veamos cómo agregar un nuevo esclavo de replicación puede ser una tarea realmente fácil.
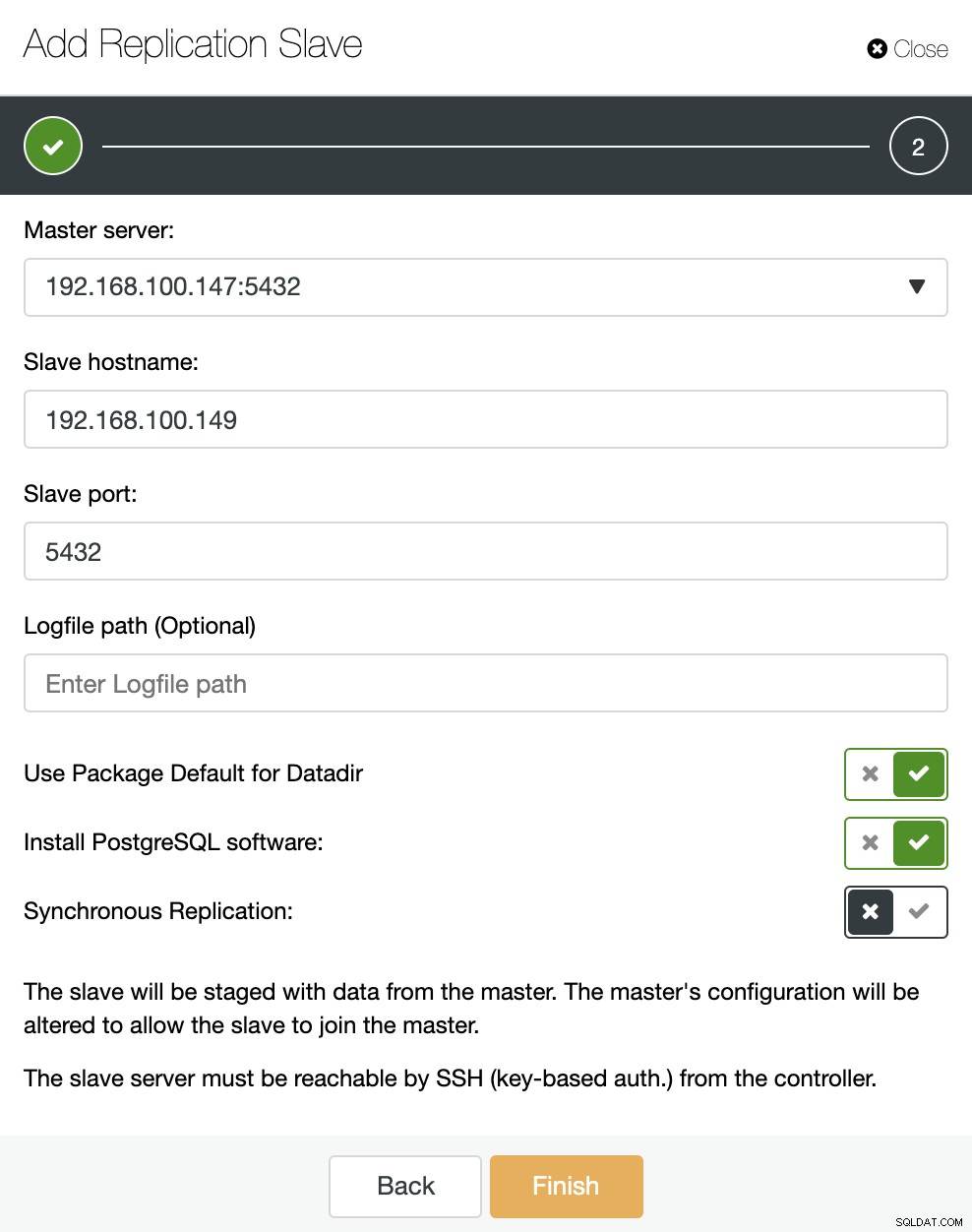
Como puede ver en la imagen, solo necesitamos elegir nuestro servidor Master, ingresar la dirección IP para nuestro nuevo servidor esclavo y el puerto de la base de datos. Luego, podemos elegir si queremos que ClusterControl instale el software por nosotros y si el esclavo de replicación debe ser síncrono o asíncrono.
De esta forma, podemos añadir tantas réplicas como queramos y repartir el tráfico de lectura entre ellas mediante un balanceador de carga, que también podemos implementar con ClusterControl.
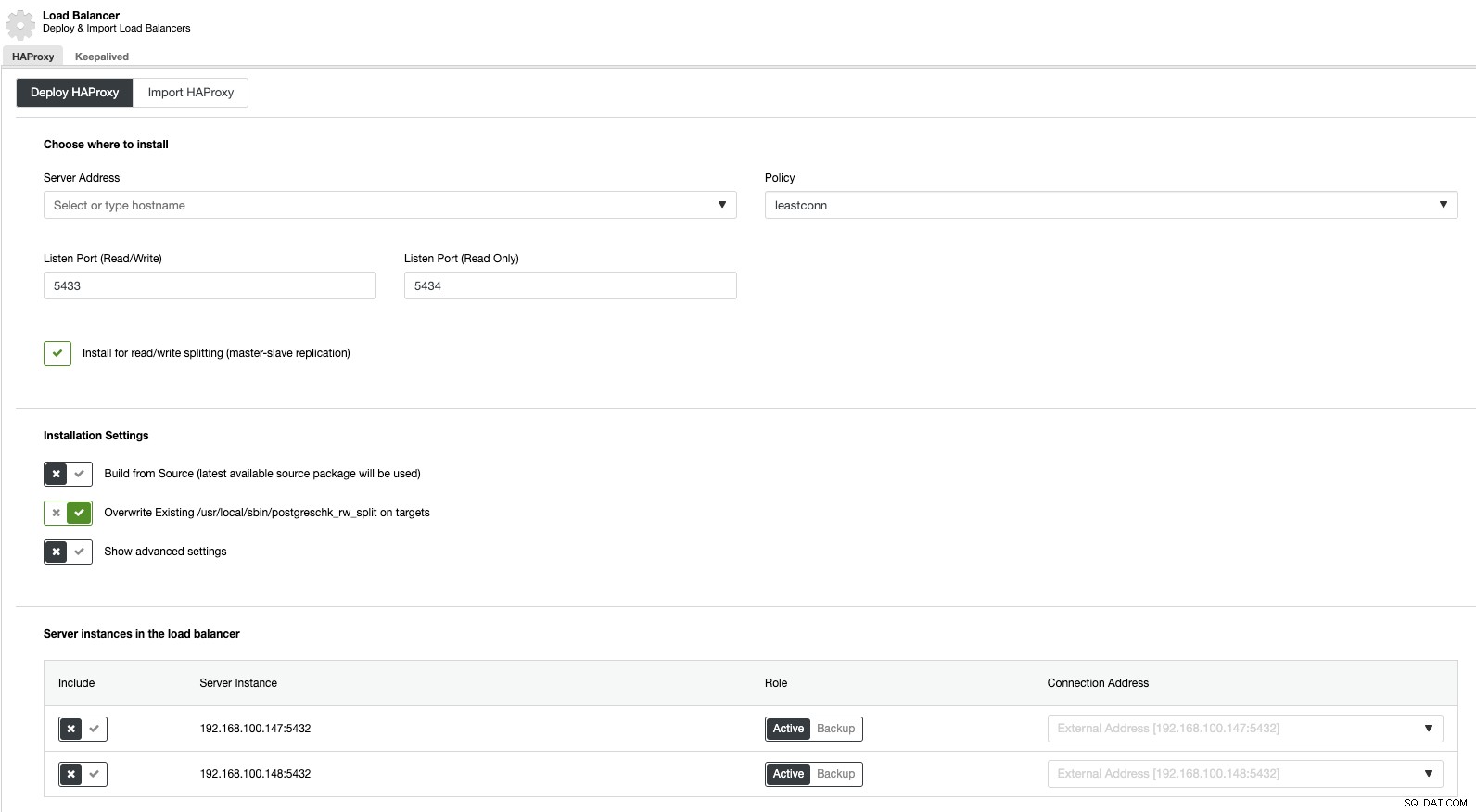
Ahora, si vamos a las acciones del clúster y seleccionamos "Agregar Load Balancer", podemos implementar un nuevo HAProxy Load Balancer o agregar uno existente.
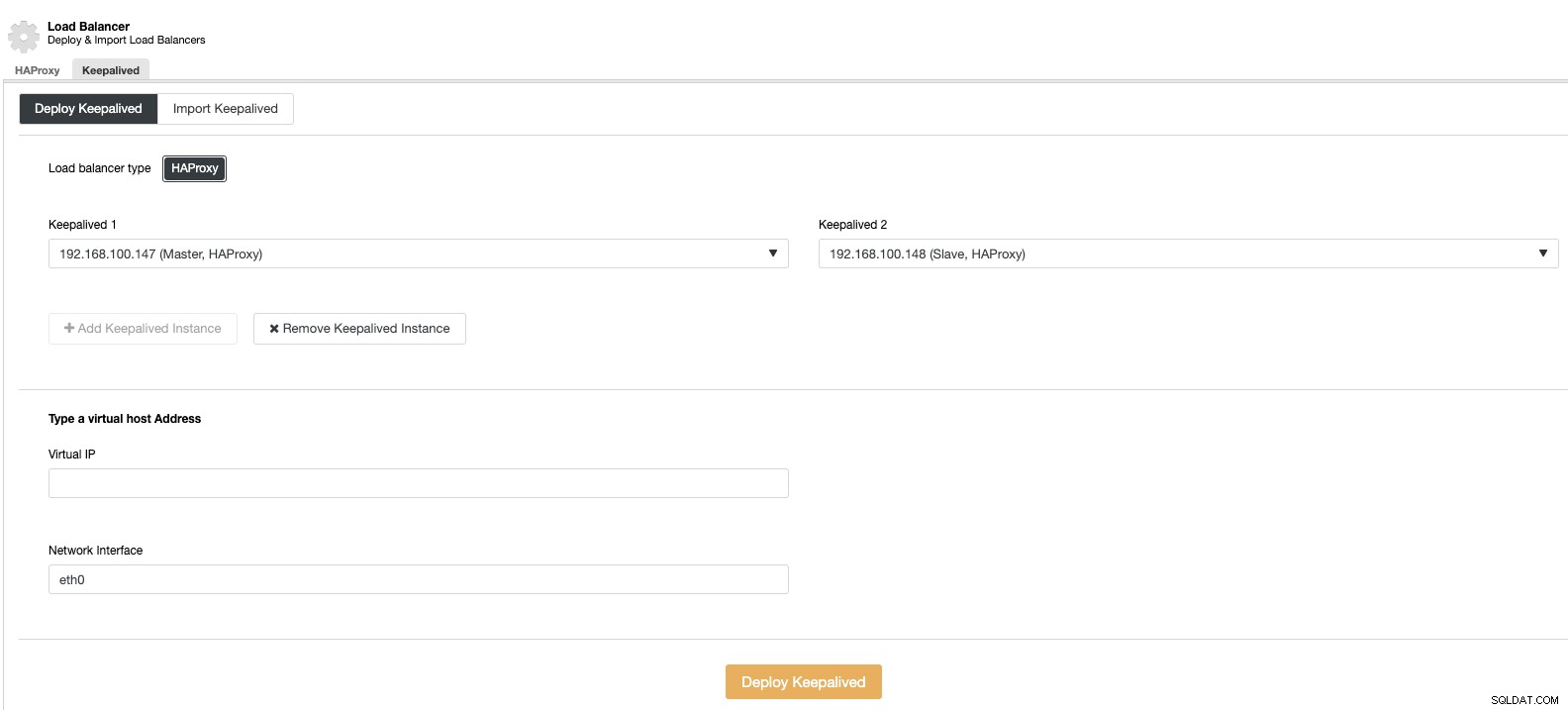
Y luego, en la misma sección del balanceador de carga, podemos agregar un servicio Keepalived que se ejecuta en los nodos del balanceador de carga para mejorar nuestro entorno de alta disponibilidad.
Escala vertical
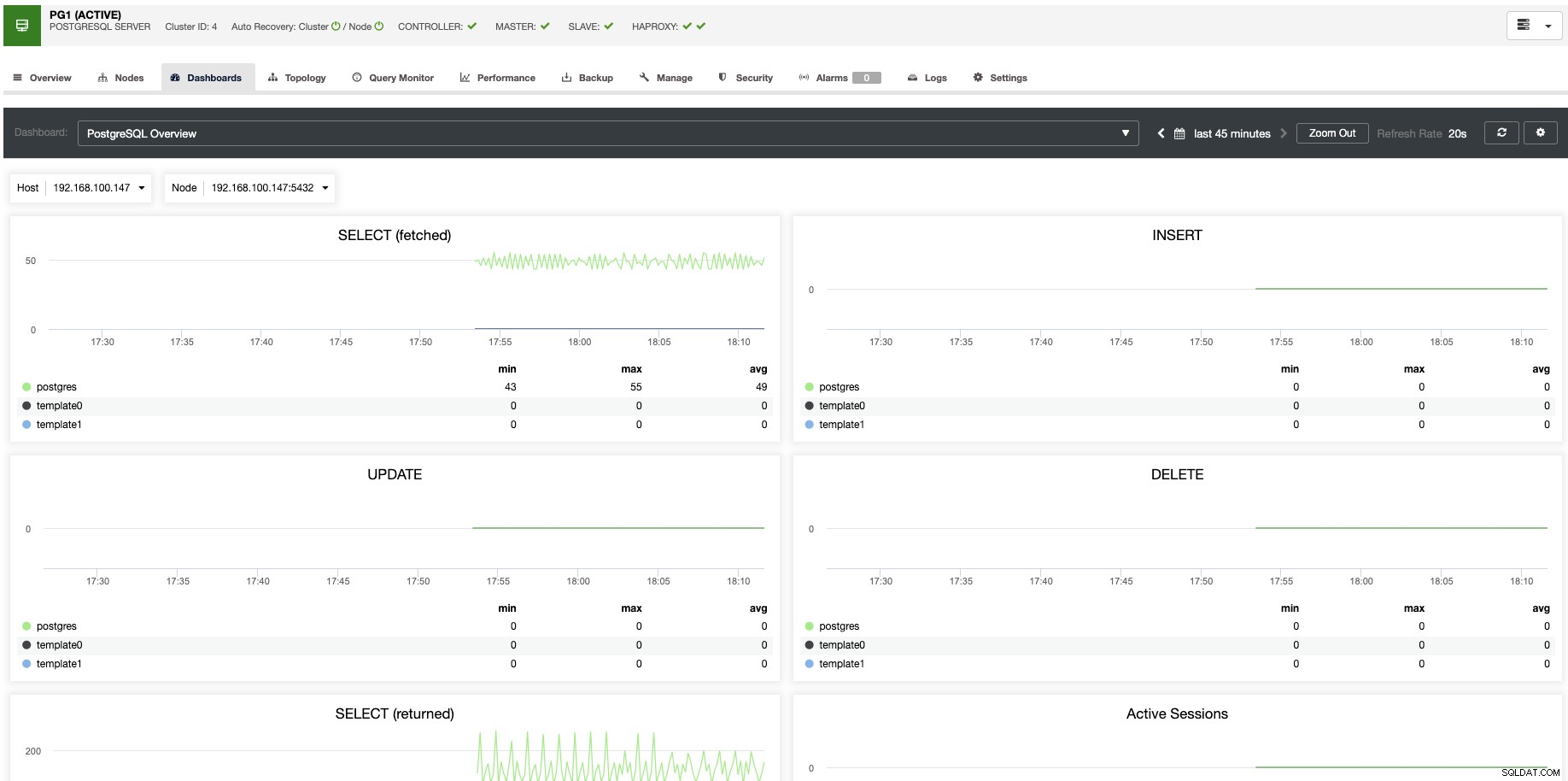
Para el escalado vertical, con ClusterControl podemos monitorear los nodos de nuestra base de datos tanto desde el sistema operativo como desde el lado de la base de datos. Podemos verificar algunas métricas como el uso de la CPU, la memoria, las conexiones, las consultas principales, las consultas en ejecución y aún más. También podemos habilitar la sección Dashboard, que nos permite ver las métricas de forma más detallada y más amigable nuestras métricas.
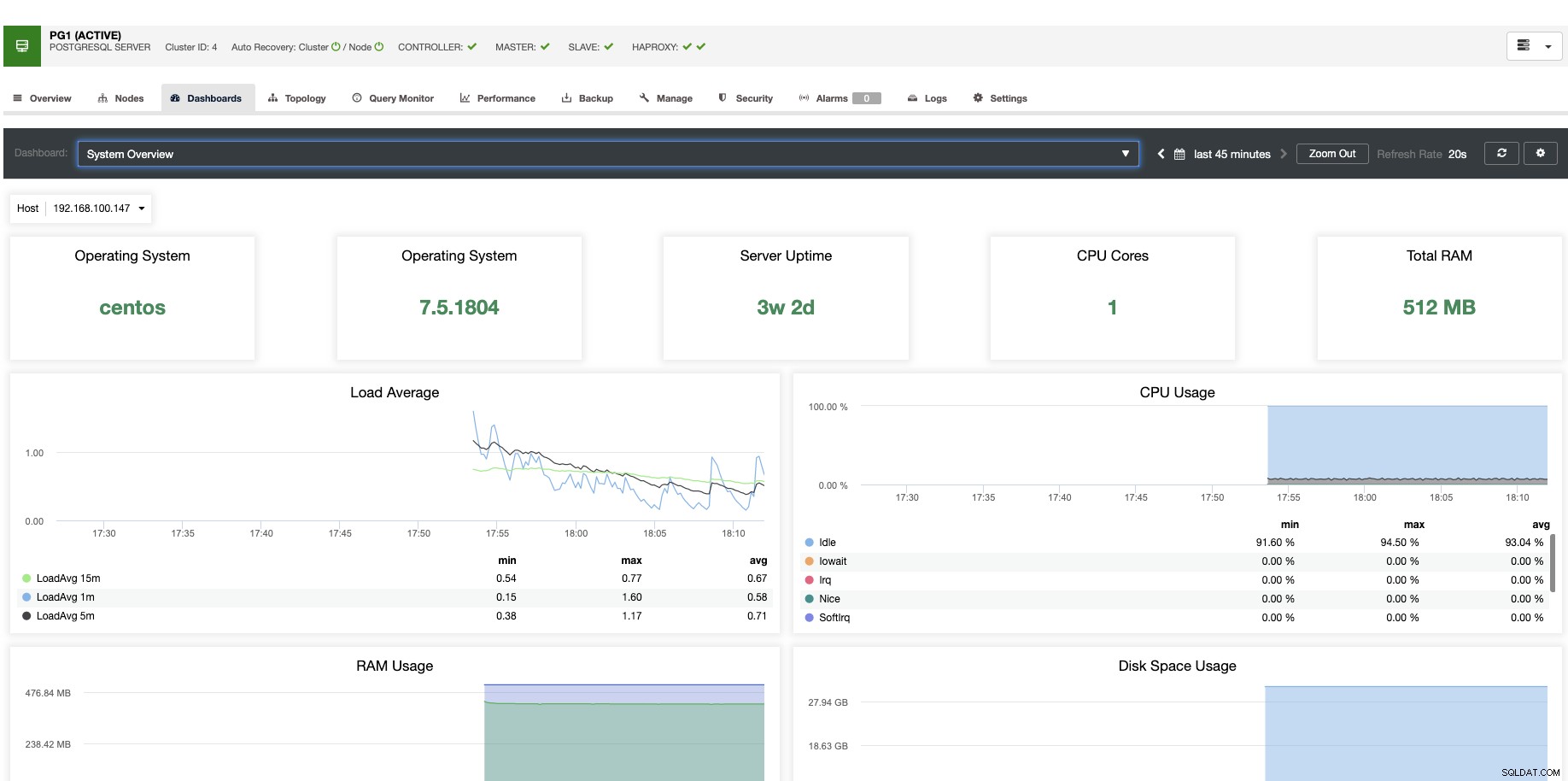
Desde ClusterControl, también puede realizar diferentes tareas de administración como Reiniciar host, Reconstruir esclavo de replicación o Promover esclavo, con un solo clic.
Conclusión
La ampliación de las bases de datos de PostgreSQL puede ser una tarea que requiere mucho tiempo. Necesitamos saber qué necesitamos escalar y cuál es la mejor manera de hacerlo. En última instancia, administrar y escalar clústeres de forma manual se vuelve bastante arduo después de cierto punto, por lo que la mayoría recurre a herramientas como la nuestra.
Si elige la ruta manual, consulte cuándo considerar agregar un nodo adicional a su clúster. ¿Quieres evitar la molestia? Evalúe ClusterControl gratis durante 30 días para ver cómo sus características hacen que el manejo de código abierto a gran escala sea simple y eficiente.
Independientemente de cómo desee administrar y escalar sus bases de datos, síganos en Twitter o LinkedIn, o suscríbase a nuestro boletín para obtener las últimas noticias y las mejores prácticas al administrar la infraestructura de base de datos basada en código abierto, ¡y nos vemos pronto!