En mi blog anterior, discutimos varias formas de seleccionar o escanear datos de una sola tabla. Pero en la práctica, obtener datos de una sola tabla no es suficiente. Requiere seleccionar datos de varias tablas y luego correlacionarlos. La correlación de estos datos entre tablas se denomina unión de tablas y se puede realizar de varias formas. Como la unión de tablas requiere datos de entrada (por ejemplo, del escaneo de la tabla), nunca puede ser un nodo de hoja en el plan generado.
Ej. considere un ejemplo de consulta simple como SELECT * FROM TBL1, TBL2 donde TBL1.ID> TBL2.ID; y supongamos que el plan generado es el siguiente:
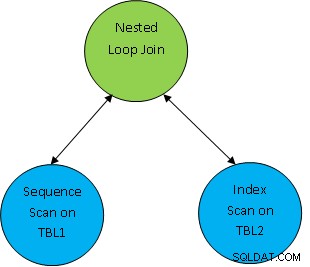
Así que aquí primero se escanean ambas tablas y luego se unen como según la condición de correlación como TBL.ID> TBL2.ID
Además del método de combinación, el orden de combinación también es muy importante. Considere el siguiente ejemplo:
SELECCIONE * DE TBL1, TBL2, TBL3 DONDE TBL1.ID=TBL2.ID Y TBL2.ID=TBL3.ID;
Considere que TBL1, TBL2 Y TBL3 tienen 10, 100 y 1000 registros respectivamente.
La condición TBL1.ID=TBL2.ID devuelve solo 5 registros, mientras que TBL2.ID=TBL3.ID devuelve 100 registros, entonces es mejor unir TBL1 y TBL2 primero para que se obtenga una menor cantidad de registros. se unió a TBL3. El plan será como se muestra a continuación:
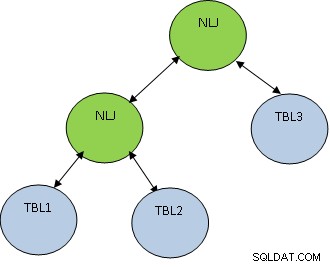
PostgreSQL admite los siguientes tipos de combinaciones:
- Unión de bucle anidado
- Unión hash
- Fusionar unirse
Cada uno de estos métodos Join son igualmente útiles según la consulta y otros parámetros, p. consulta, datos de tabla, cláusula de unión, selectividad, memoria, etc. Estos métodos de unión están implementados por la mayoría de las bases de datos relacionales.
Creemos una tabla preestablecida y completemos con algunos datos, que se usarán con frecuencia para explicar mejor estos métodos de escaneo.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEEn todos nuestros ejemplos posteriores, consideramos el parámetro de configuración predeterminado a menos que se especifique lo contrario.
Unión de bucle anidado
Nested Loop Join (NLJ) es el algoritmo de unión más simple en el que cada registro de la relación externa se compara con cada registro de la relación interna. La unión entre la relación A y B con la condición A.ID La combinación de bucle anidado (NLJ) es el método de combinación más común y se puede usar en casi cualquier conjunto de datos con cualquier tipo de cláusula de combinación. Dado que este algoritmo escanea todas las tuplas de la relación interna y externa, se considera que es la operación de unión más costosa. Según la tabla y los datos anteriores, la siguiente consulta dará como resultado una unión de bucle anidado como se muestra a continuación: Dado que la cláusula de unión es “<”, el único método de unión posible aquí es Unión de bucle anidado. Observe aquí un nuevo tipo de nodo como Materializar; este nodo actúa como caché de resultados intermedios, es decir, en lugar de obtener todas las tuplas de una relación varias veces, el resultado obtenido por primera vez se almacena en la memoria y en la siguiente solicitud para obtener la tupla se servirá desde la memoria en lugar de obtener de las páginas de relación nuevamente . En caso de que no quepan todas las tuplas en la memoria, las tuplas adicionales van a un archivo temporal. Es principalmente útil en el caso de Nested Loop Join y, hasta cierto punto, en el caso de Merge Join, ya que se basan en volver a escanear la relación interna. Materialise Node no solo se limita a almacenar en caché el resultado de la relación, sino que también puede almacenar en caché los resultados de cualquier nodo debajo del árbol del plan. CONSEJO:En caso de que la cláusula de unión sea “=” y se elija la unión de bucle anidado entre una relación, entonces es muy importante investigar si se puede elegir un método de unión más eficiente, como hash o combinación de combinación. configuración de ajuste (por ejemplo, work_mem pero no limitado a) o agregando un índice, etc. Algunas de las consultas pueden no tener una cláusula de unión, en ese caso también la única opción para unirse es Unión de bucle anidado. P.ej. considere las siguientes consultas según los datos preconfigurados: La unión en el ejemplo anterior es solo un producto cartesiano de ambas tablas. Este algoritmo funciona en dos fases: La unión entre la relación A y B con la condición A.ID =B.ID se puede representar de la siguiente manera: Según la tabla y los datos de configuración previa anteriores, la siguiente consulta dará como resultado una unión hash como se muestra a continuación: Aquí, la tabla hash se crea en la tabla blogtable2 porque es la tabla más pequeña, por lo que la memoria mínima requerida para la tabla hash y toda la tabla hash puede caber en la memoria. Merge Join es un algoritmo en el que cada registro de la relación externa se compara con cada registro de la relación interna hasta que existe la posibilidad de que coincidan las cláusulas de unión. Este algoritmo de unión solo se usa si ambas relaciones están ordenadas y el operador de la cláusula de unión es “=”. La unión entre la relación A y B con la condición A.ID =B.ID se puede representar de la siguiente manera: La consulta de ejemplo que resultó en una combinación hash, como se muestra arriba, puede generar una combinación de combinación si el índice se crea en ambas tablas. Esto se debe a que los datos de la tabla se pueden recuperar en orden debido al índice, que es uno de los principales criterios para el método Merge Join: Así que, como vemos, ambas tablas usan exploración de índice en lugar de exploración secuencial, por lo que ambas tablas emitirán registros ordenados. PostgreSQL admite varias configuraciones relacionadas con el planificador, que se pueden usar para sugerir al optimizador de consultas que no seleccione algún tipo particular de métodos de combinación. Si el método de unión elegido por el optimizador no es óptimo, estos parámetros de configuración se pueden desactivar para forzar al optimizador de consultas a elegir un tipo diferente de métodos de unión. Todos estos parámetros de configuración están "activados" de forma predeterminada. A continuación se encuentran los parámetros de configuración del planificador específicos para los métodos de unión. Hay muchos parámetros de configuración relacionados con el plan que se utilizan para varios propósitos. En este blog, manteniéndolo restringido solo a métodos de unión. Estos parámetros se pueden modificar desde una sesión en particular. Entonces, en caso de que queramos experimentar con el plan de una sesión en particular, estos parámetros de configuración se pueden manipular y otras sesiones seguirán funcionando como están. Ahora, considere los ejemplos anteriores de combinación de combinación y combinación hash. Sin un índice, el optimizador de consultas seleccionó un Hash Join para la siguiente consulta, como se muestra a continuación, pero después de usar la configuración, cambia a merge join incluso sin índice: Inicialmente se elige Hash Join porque los datos de las tablas no están ordenados. Para elegir el Plan de combinación de combinación, primero debe ordenar todos los registros recuperados de ambas tablas y luego aplicar la combinación de combinación. Por lo tanto, el costo de clasificación será adicional y, por lo tanto, aumentará el costo total. Entonces, posiblemente, en este caso, el costo total (incluido el aumento) es mayor que el costo total de Hash Join, por lo que se elige Hash Join. Una vez que el parámetro de configuración enable_hashjoin se cambia a "off", esto significa que el optimizador de consultas asigna directamente un costo para hash join como costo de inhabilitación (=1.0e10, es decir, 10000000000.00). El costo de cualquier posible unión será menor que esto. Por lo tanto, el mismo resultado de la consulta en Merge Join después de que enable_hashjoin cambiara a "off" ya que, incluso incluyendo el costo de clasificación, el costo total de merge join es menor que el costo de inhabilitación. Ahora considere el siguiente ejemplo: Como podemos ver arriba, a pesar de que el parámetro de configuración relacionado con la unión de bucle anidado se cambia a "desactivado", sigue eligiendo Unión de bucle anidado ya que no hay posibilidad alternativa de ningún otro tipo de método de unión para obtener seleccionado. En términos más simples, dado que Nested Loop Join es la única unión posible, cualquiera que sea el costo, siempre será el ganador (igual que solía ser el ganador en una carrera de 100 m si corría solo... :-)). Además, observe la diferencia de costo en el primer y segundo plan. El primer plan muestra el costo real de Nested Loop Join, pero el segundo muestra el costo de inhabilitación del mismo. Todos los tipos de métodos de unión de PostgreSQL son útiles y se seleccionan en función de la naturaleza de la consulta, los datos, la cláusula de unión, etc. En caso de que la consulta no funcione como se esperaba, es decir, los métodos de unión no seleccionado como se esperaba, el usuario puede jugar con los diferentes parámetros de configuración del plan disponibles y ver si falta algo.For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)Unión hash
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Fusionar Unión
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)Configuración
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)Conclusión