No existe un sistema, hardware o topología perfectos para evitar todos los posibles problemas que podrían ocurrir en un entorno de producción. Superar estos desafíos requiere un DRP (Plan de recuperación ante desastres) eficaz, configurado de acuerdo con los requisitos de su aplicación, infraestructura y negocio. La clave del éxito en este tipo de situaciones siempre es qué tan rápido podemos solucionar o recuperarnos del problema.
En este blog, analizaremos los escenarios de falla más comunes de PostgreSQL y le mostraremos cómo puede resolver o lidiar con los problemas. También veremos cómo ClusterControl puede ayudarnos a volver a estar en línea
La topología común de PostgreSQL
Para comprender los escenarios de fallas comunes, primero debe comenzar con una topología común de PostgreSQL. Puede ser cualquier aplicación conectada a un nodo principal de PostgreSQL que tenga una réplica conectada.
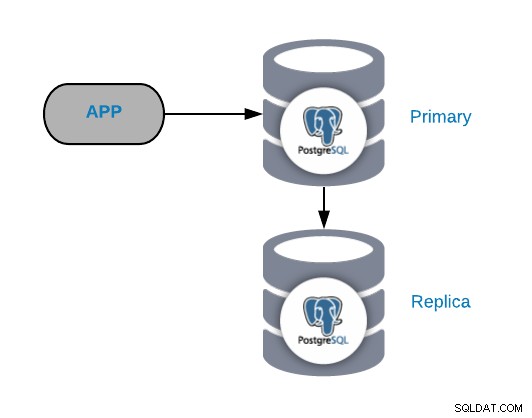
Siempre puede mejorar o expandir esta topología agregando más nodos o balanceadores de carga , pero esta es la topología básica con la que comenzaremos a trabajar.
Fallo del nodo principal de PostgreSQL
Esta es una de las fallas más críticas, ya que debemos solucionarla lo antes posible si queremos mantener nuestros sistemas en línea. Para este tipo de falla, es importante contar con algún tipo de mecanismo automático de conmutación por error. Después de la falla, puede investigar el motivo de los problemas. Después del proceso de conmutación por error, nos aseguramos de que el nodo principal fallido no siga pensando que es el nodo principal. Esto es para evitar la inconsistencia de datos al escribir en él.
Las causas más comunes de este tipo de problema son una falla del sistema operativo, una falla del hardware o una falla del disco. En cualquier caso, deberíamos comprobar la base de datos y los registros del sistema operativo para encontrar el motivo.
La solución más rápida para este problema es realizar una tarea de conmutación por error para reducir el tiempo de inactividad. Para promover una réplica, podemos usar el comando pg_ctl promover en el nodo de la base de datos esclava y, luego, debemos enviar el tráfico desde el aplicación al nuevo nodo primario. Para esta última tarea, podemos implementar un balanceador de carga entre nuestra aplicación y los nodos de la base de datos, para evitar cualquier cambio del lado de la aplicación en caso de falla. También podemos configurar el balanceador de carga para detectar la falla del nodo y en lugar de enviarle tráfico a él, enviar el tráfico al nuevo nodo principal.
Después del proceso de conmutación por error y asegurarnos de que el sistema está funcionando nuevamente, podemos analizar el problema y recomendamos mantener siempre al menos un nodo esclavo en funcionamiento, de modo que en caso de una nueva falla principal, podemos realizar la tarea de conmutación por error nuevamente.
Error de nodo de réplica de PostgreSQL
Este no suele ser un problema crítico (siempre que tenga más de una réplica y no la utilizan para enviar el tráfico de producción de lectura). Si tiene problemas en el nodo principal y no tiene su réplica actualizada, tendrá un problema realmente crítico. Si está utilizando nuestra réplica para fines de informes o big data, probablemente querrá arreglarlo rápidamente de todos modos.
Las causas más comunes de este tipo de problema son las mismas que vimos para el nodo principal, una falla del sistema operativo, falla del hardware o falla del disco. Debe verificar la base de datos y los registros del sistema operativo. para encontrar la razón.
No se recomienda mantener el sistema funcionando sin ninguna réplica ya que, en caso de falla, no tiene una forma rápida de volver a conectarse. Si solo tiene un esclavo, debe resolver el problema lo antes posible; la forma más rápida es crear una nueva réplica desde cero. Para ello, deberá realizar una copia de seguridad consistente y restaurarla en el nodo esclavo, luego configurar la replicación entre este nodo esclavo y el nodo principal.
Si desea conocer el motivo de la falla, debe usar otro servidor para crear la nueva réplica y luego buscar en la antigua para descubrirlo. Cuando termine esta tarea, también puede reconfigurar la réplica anterior y mantener ambas funcionando como una opción de conmutación por error futura.
Si está utilizando la réplica para generar informes o para fines de big data, debe cambiar la dirección IP para conectarse a la nueva. Como en el caso anterior, una forma de evitar este cambio es utilizando un balanceador de carga que conocerá el estado de cada servidor, permitiéndote agregar/eliminar réplicas como desees.
Error de replicación de PostgreSQL
En general, este tipo de problema se genera debido a una red o configuración tema. Está relacionado con una pérdida WAL (Write-Ahead Logging) en el nodo principal y la forma en que PostgreSQL administra la replicación.
Si tiene un tráfico importante, realiza puntos de control con demasiada frecuencia o almacena WALS solo durante unos minutos; si tiene un problema de red, tendrá poco tiempo para resolverlo. Sus WAL se eliminarán antes de que pueda enviarlos y aplicarlos a la réplica.
Si se eliminó el WAL que la réplica necesita para seguir funcionando, debe reconstruirlo, por lo que para evitar esta tarea, debemos verificar la configuración de nuestra base de datos para aumentar los wal_keep_segments (cantidades de WALS para mantener en el directorio pg_xlog) o los parámetros max_wal_senders (número máximo de procesos de remitente WAL que se ejecutan simultáneamente).
Otra opción recomendada es configurar archive_mode y enviar los archivos WAL a otra ruta con el parámetro archive_command. De esta manera, si PostgreSQL llega al límite y elimina el archivo WAL, lo tendremos en otra ruta de todos modos.
Corrupción de datos PostgreSQL / Inconsistencia de datos / Eliminación accidental

Esta es una pesadilla para cualquier DBA y probablemente el problema más complejo arreglado, dependiendo de qué tan extendido esté el problema.
Cuando sus datos se ven afectados por algunos de estos problemas, la forma más común de solucionarlo (y probablemente la única) es restaurar una copia de seguridad. Es por eso que las copias de seguridad son la forma básica de cualquier plan de recuperación ante desastres y se recomienda tener al menos tres copias de seguridad almacenadas en diferentes lugares físicos. Las mejores prácticas dictan que los archivos de respaldo deben tener uno almacenado localmente en el servidor de la base de datos (para una recuperación más rápida), otro en un servidor de respaldo centralizado y el último en la nube.
También podemos crear una combinación de copias de seguridad compatibles con PITR completas/incrementales/diferenciales para reducir nuestro objetivo de punto de recuperación.
Gestión de errores de PostgreSQL con ClusterControl
Ahora que hemos analizado estos escenarios comunes de fallas de PostgreSQL, veamos qué sucedería si estuviéramos administrando sus bases de datos de PostgreSQL desde un sistema de administración de bases de datos centralizado. Uno que es excelente en términos de llegar a una manera rápida y fácil de solucionar el problema, lo antes posible, en caso de falla.
ClusterControl proporciona automatización para la mayoría de las tareas de PostgreSQL descritas anteriormente; todo de forma centralizada y fácil de usar. Con este sistema podrás configurar fácilmente cosas que, de forma manual, te llevarían tiempo y esfuerzo. Ahora revisaremos algunas de sus características principales relacionadas con los escenarios de falla de PostgreSQL.
Implementar/Importar un clúster de PostgreSQL
Una vez que ingresamos a la interfaz de ClusterControl, lo primero que debemos hacer es implementar un nuevo clúster o importar uno existente. Para realizar una implementación, simplemente seleccione la opción Implementar clúster de base de datos y siga las instrucciones que aparecen.
Escalado de su clúster de PostgreSQL
Si va a Acciones de clúster y selecciona Agregar esclavo de replicación, puede crear una nueva réplica desde cero o agregar una base de datos PostgreSQL existente como réplica. De esta forma, podrás tener tu nueva réplica funcionando en unos minutos y podremos añadir tantas réplicas como queramos; distribuyendo el tráfico de lectura entre ellos usando un balanceador de carga (que también podemos implementar con ClusterControl).
Conmutación por error automática de PostgreSQL
ClusterControl administra la conmutación por error en su configuración de replicación. Detecta fallas en el maestro y promueve un esclavo con los datos más actuales como nuevo maestro. También falla automáticamente el resto de los esclavos para replicar desde el nuevo maestro. En cuanto a las conexiones de clientes, aprovecha dos herramientas para la tarea:HAProxy y Keepalived.
HAProxy es un balanceador de carga que distribuye el tráfico desde un origen a uno o más destinos y puede definir reglas y/o protocolos específicos para la tarea. Si alguno de los destinos deja de responder, se marca como fuera de línea y el tráfico se envía a uno de los destinos disponibles. Esto evita que el tráfico se envíe a un destino inaccesible y la pérdida de esta información al dirigirlo a un destino válido.
Keepalived le permite configurar una IP virtual dentro de un grupo de servidores activo/pasivo. Esta IP virtual está asignada a un servidor "Principal" activo. Si este servidor falla, la IP se migra automáticamente al servidor “Secundario” que resultó ser pasivo, lo que le permite seguir trabajando con la misma IP de forma transparente para nuestros sistemas.
Agregar un balanceador de carga de PostgreSQL
Si va a Acciones del clúster y selecciona Agregar equilibrador de carga (o desde la vista del clúster, vaya a Administrar -> Equilibrador de carga), puede agregar equilibradores de carga a nuestra topología de base de datos.
La configuración necesaria para crear su nuevo balanceador de carga es bastante simple. Solo necesita agregar IP/Hostname, puerto, política y los nodos que vamos a usar. Puede agregar dos balanceadores de carga con Keepalived entre ellos, lo que nos permite tener una conmutación por error automática de nuestro balanceador de carga en caso de falla. Keepalived usa una dirección IP virtual y la migra de un balanceador de carga a otro en caso de falla, para que nuestra configuración pueda continuar funcionando normalmente.
Copias de seguridad PostgreSQL
Ya hemos discutido la importancia de tener copias de seguridad. ClusterControl proporciona la funcionalidad para generar una copia de seguridad inmediata o programarla.
Puede elegir entre tres métodos diferentes de copia de seguridad, pgdump, pg_basebackup o pgBackRest. También puede especificar dónde almacenar las copias de seguridad (en el servidor de la base de datos, en el servidor de ClusterControl o en la nube), el nivel de compresión, el cifrado requerido y el período de retención.
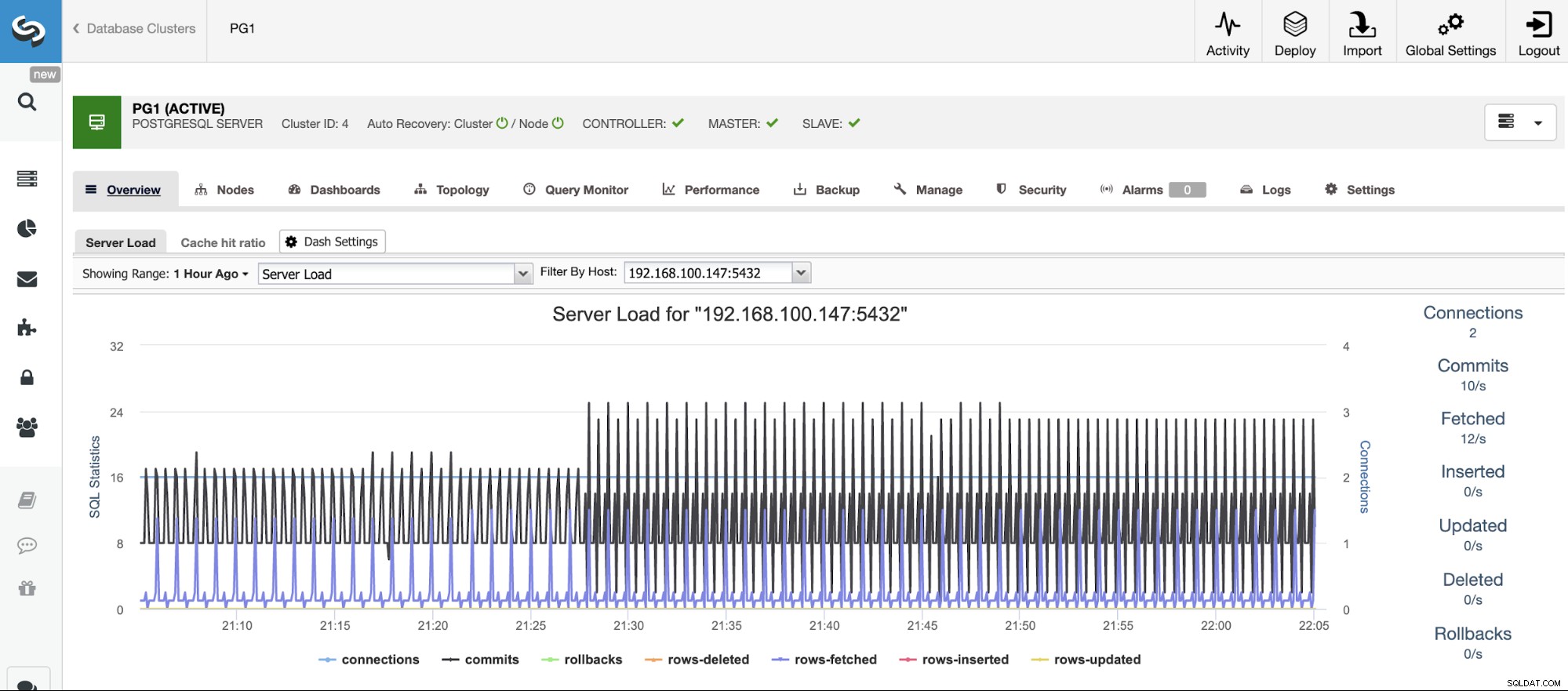
Supervisión y alertas de PostgreSQL
Antes de poder tomar medidas, debe saber qué está sucediendo, por lo que deberá monitorear su clúster de base de datos. ClusterControl le permite monitorear nuestros servidores en tiempo real. Hay gráficos con datos básicos como CPU, red, disco, RAM, IOPS, así como métricas específicas de la base de datos recopiladas de las instancias de PostgreSQL. Las consultas de la base de datos también se pueden ver desde Query Monitor.
De la misma manera que habilita el monitoreo desde ClusterControl, también puede configurar alertas que le informen sobre eventos en su clúster. Estas alertas son configurables y se pueden personalizar según sea necesario.
Conclusión
Todos eventualmente tendrán que hacer frente a los problemas y fallas de PostgreSQL. Y dado que no puede evitar el problema, debe poder solucionarlo lo antes posible y mantener el sistema en funcionamiento. También vimos cómo el uso de ClusterControl puede ayudar con estos problemas; todo desde una plataforma única y fácil de usar.
Estos son algunos de los escenarios de falla más comunes para PostgreSQL. Nos encantaría conocer tus propias experiencias y cómo lo solucionaste.