En esta tercera parte de Benchmarking Managed PostgreSQL Cloud Solutions , aproveché la oferta de nivel gratuito de GCP de Google. Ha sido una experiencia valiosa y, como administrador de sistemas que pasa la mayor parte de su tiempo en la consola, no podía perder la oportunidad de probar Cloud Shell, una de las características de la consola que diferencia a Google del proveedor de nube con el que estoy más familiarizado. , Servicios web de Amazon.
Para recapitular rápidamente, en la Parte 1 analicé las herramientas de evaluación comparativa disponibles y expliqué por qué elegí el Procedimiento de evaluación comparativa de AWS para Aurora. También evalué Amazon Aurora para PostgreSQL versión 10.6. En la Parte 2, revisé AWS RDS para PostgreSQL versión 11.1.
Durante esta ronda, las pruebas basadas en el procedimiento de referencia de AWS para Aurora se ejecutarán en Google Cloud SQL para PostgreSQL 9.6, ya que la versión 11.1 aún se encuentra en versión beta.
Instancias en la nube
Requisitos
Como se mencionó en los dos artículos anteriores, opté por dejar la configuración de PostgreSQL en sus valores predeterminados de GUC en la nube, a menos que eviten que se ejecuten las pruebas (ver más abajo). Recuerde de artículos anteriores que la suposición ha sido que, desde el primer momento, el proveedor de la nube debe tener la instancia de la base de datos configurada para proporcionar un rendimiento razonable.
El parche de sincronización de AWS pgbench para PostgreSQL 9.6.5 se aplicó sin problemas a la versión de Google Cloud de PostgreSQL 9.6.10.
Con la información que Google publicó en su blog Google Cloud for AWS Professionals, comparé las especificaciones del cliente y las instancias de destino con respecto a los componentes de computación, almacenamiento y redes. Por ejemplo, el equivalente de Google Cloud de AWS Enhanced Networking se logra dimensionando el nodo de cómputo según la fórmula:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)Cuando se trata de configurar la instancia de la base de datos de destino, de manera similar a AWS, Google Cloud no permite réplicas; sin embargo, el almacenamiento está encriptado en reposo y no hay opción para deshabilitarlo.
Finalmente, para lograr el mejor rendimiento de la red, el cliente y las instancias de destino deben estar ubicados en la misma zona de disponibilidad.
Cliente
Las especificaciones de la instancia del cliente que coinciden con la más cercana a la instancia de AWS son:
- vCPU:32 (16 núcleos x 2 subprocesos/núcleo)
- RAM:208 GiB (máximo para la instancia de 32 vCPU)
- Almacenamiento:disco persistente de Compute Engine
- Red:16 Gbps (máximo de [32 vCPU x 2 Gbps/vCPU] y 16 Gbps)
Detalles de la instancia después de la inicialización:
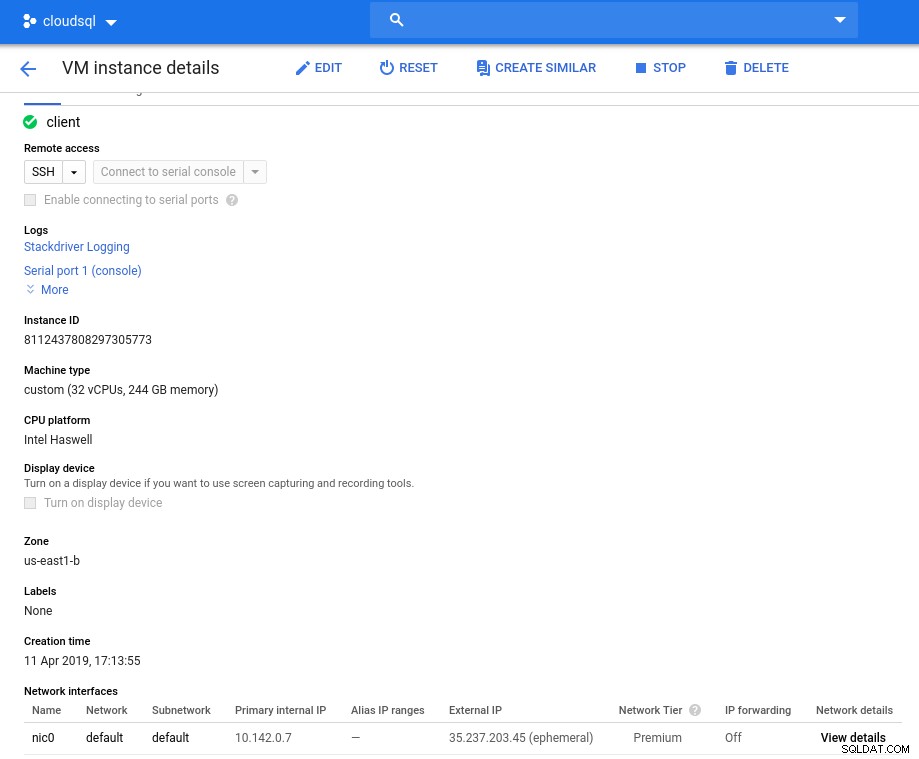 Instancia de cliente:computación y red
Instancia de cliente:computación y red Nota:Las instancias están limitadas de manera predeterminada a 24 vCPU. El soporte técnico de Google debe aprobar el aumento de la cuota a 32 vCPU por instancia.

Si bien este tipo de solicitudes generalmente se procesan dentro de los 2 días hábiles, tengo que dar el visto bueno a los Servicios de asistencia de Google por completar mi solicitud en solo 2 horas.
Para los curiosos, la fórmula de velocidad de la red se basa en la documentación del motor de cómputo a la que se hace referencia en este blog de GCP.
Clúster de base de datos
A continuación se encuentran las especificaciones de la instancia de la base de datos:
- vCPU:8
- RAM:52 GiB (máximo)
- Almacenamiento:144 MB/s, 9000 IOPS
- Red:2000 MB/s
Tenga en cuenta que la memoria máxima disponible para una instancia de 8 CPU virtuales es de 52 GiB. Se puede asignar más memoria seleccionando una instancia más grande (más vCPU):
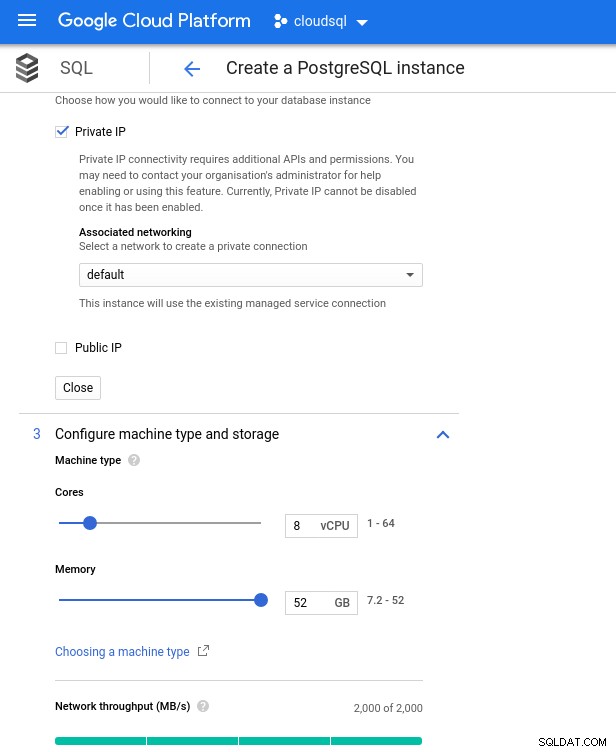 CPU de base de datos y tamaño de memoria
CPU de base de datos y tamaño de memoria Si bien Google SQL puede expandir automáticamente el almacenamiento subyacente, que por cierto es una función realmente interesante, elegí desactivar la opción para ser coherente con el conjunto de funciones de AWS y evitar un posible impacto de E/S durante la operación de cambio de tamaño. ("potencial", porque no debería tener ningún impacto negativo, sin embargo, según mi experiencia, cambiar el tamaño de cualquier tipo de almacenamiento subyacente aumenta la E/S, aunque sea por unos segundos).
Recuerde que la instancia de la base de datos de AWS fue respaldada por un almacenamiento EBS optimizado que proporcionó un máximo de:
- Ancho de banda de 1700 Mbps
- 212,5 MB/s de rendimiento
- 12 000 IOPS
Con Google Cloud logramos una configuración similar ajustando la cantidad de vCPU (ver arriba) y la capacidad de almacenamiento:
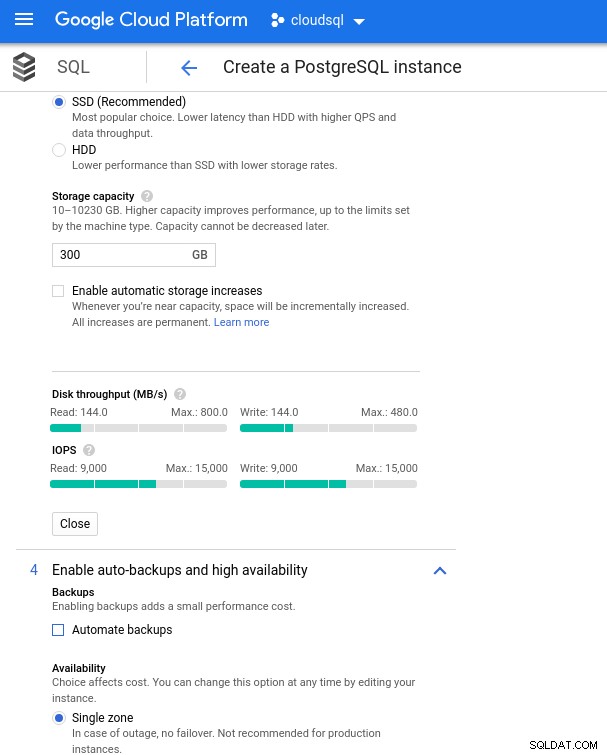 Configuración de copia de seguridad y configuración de almacenamiento de la base de datos
Configuración de copia de seguridad y configuración de almacenamiento de la base de datos Ejecución de los puntos de referencia
Configuración
A continuación, instale las herramientas de referencia, pgbench y sysbench siguiendo las instrucciones de la guía de Amazon adaptada a PostgreSQL versión 9.6.10.
Inicialice las variables de entorno de PostgreSQL en .bashrc y configure las rutas a los binarios y bibliotecas de PostgreSQL:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libLista de comprobación previa al vuelo:
[[email protected] ~]# psql --version
psql (PostgreSQL) 9.6.10
[[email protected] ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[[email protected] ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)Y estamos listos para el despegue:
banco pg
Inicialice la base de datos pgbench.
[[email protected] ~]# pgbench -i --fillfactor=90 --scale=10000…y varios minutos después:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Como ya estamos acostumbrados, el tamaño de la base de datos debe ser de 160 GB. Verifiquemos que:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)Con todos los preparativos completados, comience la prueba de lectura/escritura:
[[email protected] ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connections¡Ups! ¿Cuál es el máximo?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Por lo tanto, aunque AWS establece max_connections en gran medida, ya que no encontré ese problema, Google Cloud requiere un pequeño ajuste... Vuelva a la consola en la nube, actualice el parámetro de la base de datos, espere unos minutos y luego verifique:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)Al reiniciar la prueba, todo parece funcionar bien:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998... pero hay otra trampa. Me encontré con una sorpresa al intentar abrir una nueva sesión de psql para contar el número de conexiones:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connections¿Podría ser que superuser_reserved_connections no esté en su configuración predeterminada?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)Ese es el valor predeterminado, entonces, ¿qué más podría ser?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)¡Bingo! Otro golpe de max_connections se encarga de eso, sin embargo, requirió que reinicie la prueba de pgbench. Y esa es la historia detrás de la aparente ejecución duplicada en los gráficos a continuación.
Y finalmente, los resultados están en:
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)banco de sistema
Rellene la base de datos:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareSalida:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...Y ahora ejecuta la prueba:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runY los resultados:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Métricas comparativas
El complemento de PostgreSQL para Stackdriver quedó obsoleto a partir del 28 de febrero de 2019. Si bien Google recomienda Blue Medora, a los efectos de este artículo, opté por eliminar la creación de una cuenta y confiar en las métricas de Stackdriver disponibles.
- Utilización de la CPU:
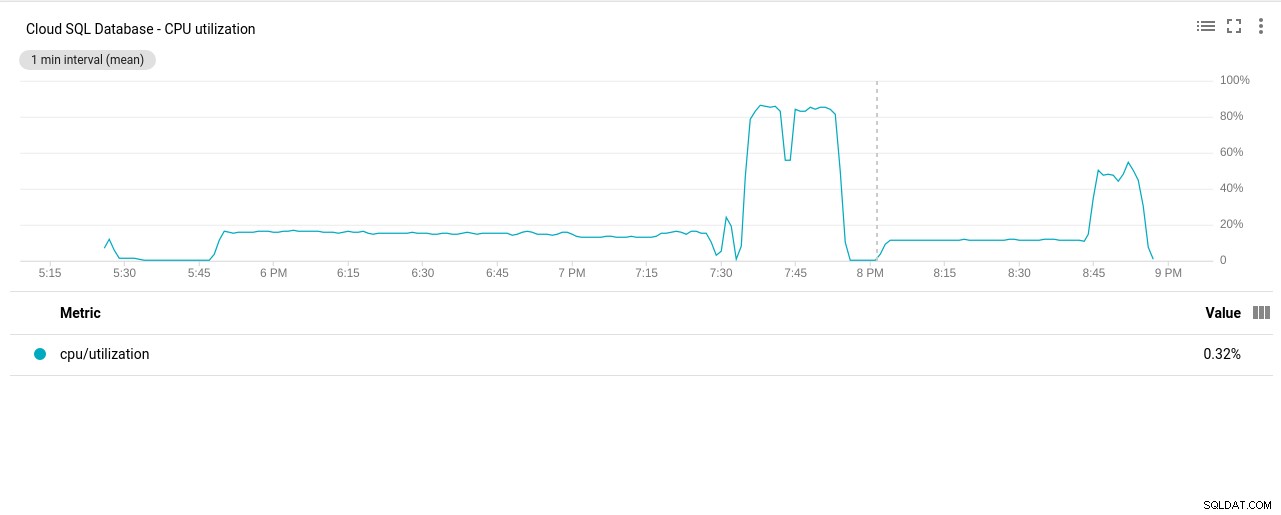 Autor de la fotografía Google Cloud SQL:uso de la CPU de PostgreSQL
Autor de la fotografía Google Cloud SQL:uso de la CPU de PostgreSQL - Operaciones de lectura/escritura de disco:
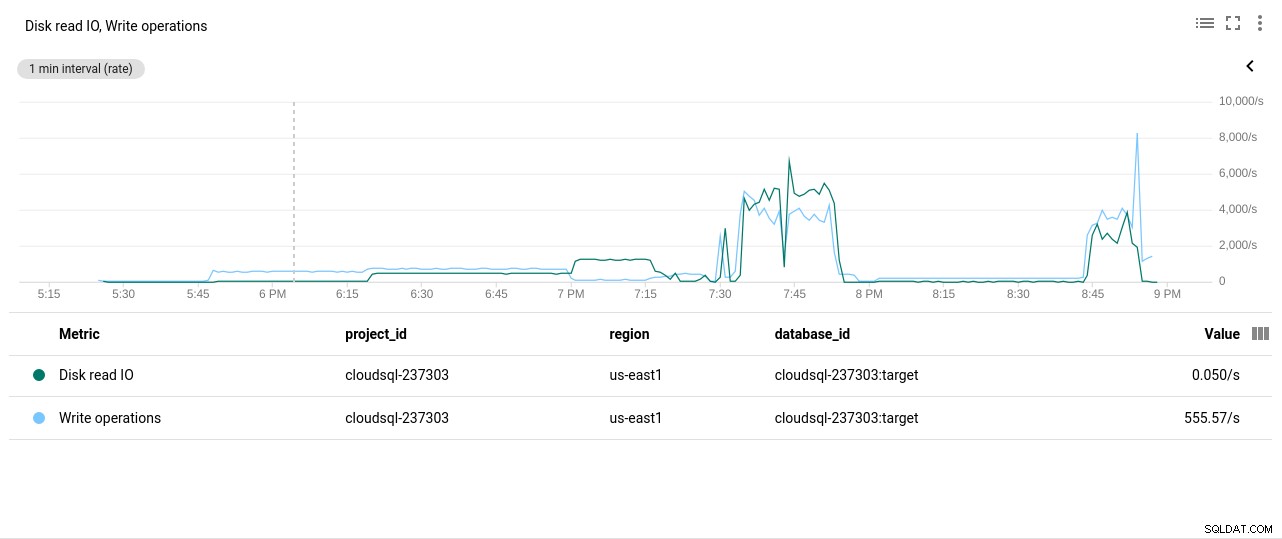 Autor de la fotografía Google Cloud SQL:operaciones de lectura/escritura de disco de PostgreSQL
Autor de la fotografía Google Cloud SQL:operaciones de lectura/escritura de disco de PostgreSQL - Bytes de red enviados/recibidos:
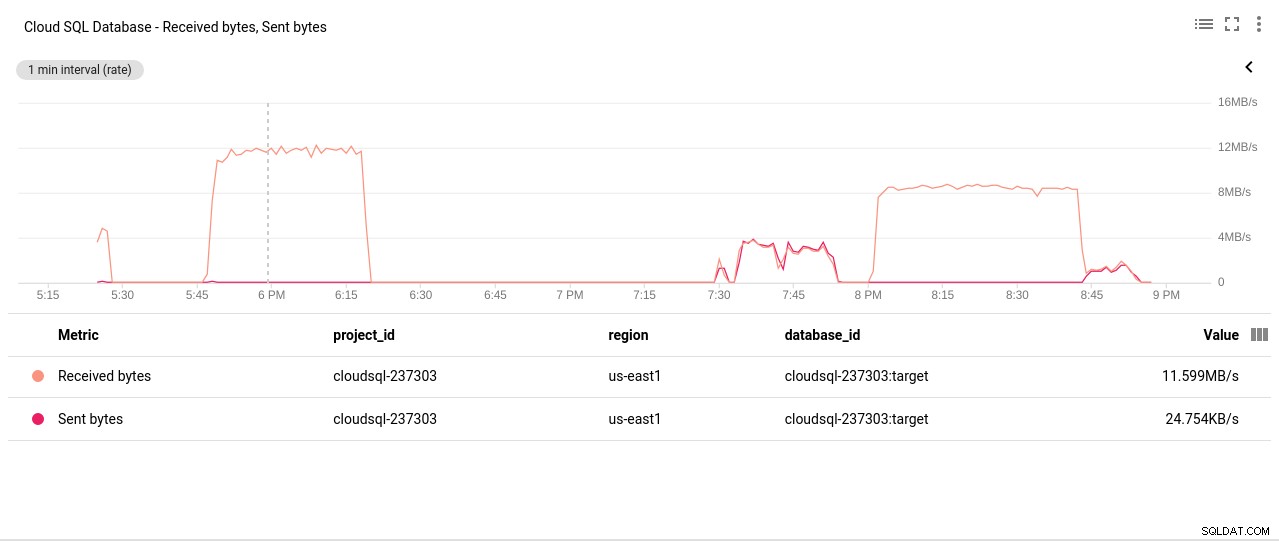 Autor de la fotografía Google Cloud SQL:Bytes enviados/recibidos de la red de PostgreSQL
Autor de la fotografía Google Cloud SQL:Bytes enviados/recibidos de la red de PostgreSQL - Recuento de conexiones de PostgreSQL:
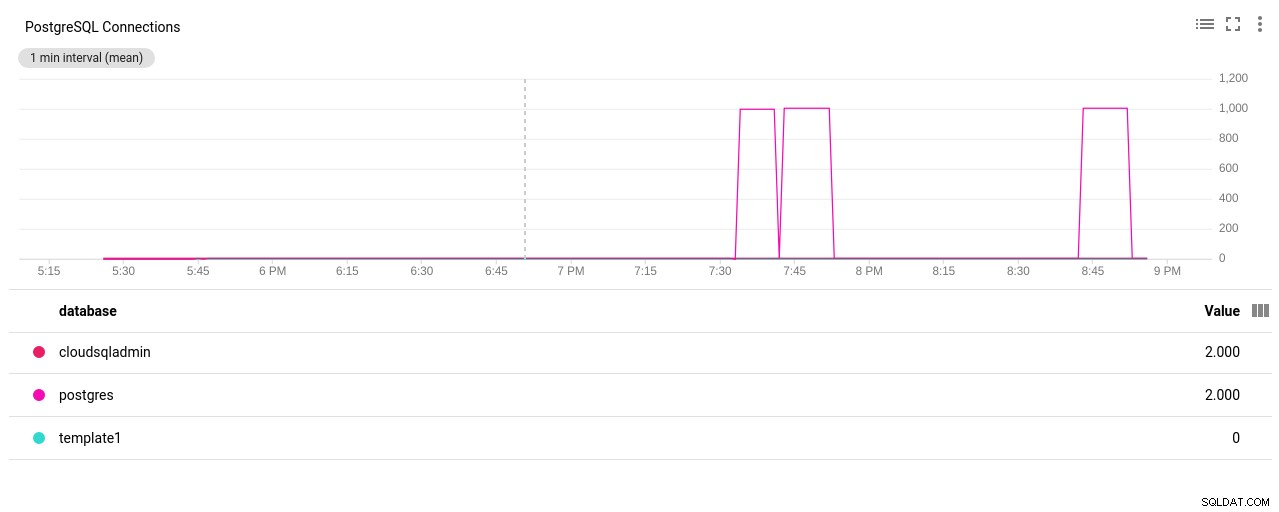 Autor de la fotografía Google Cloud SQL:Recuento de conexiones de PostgreSQL
Autor de la fotografía Google Cloud SQL:Recuento de conexiones de PostgreSQL
Resultados de referencia
Inicialización de pgbench
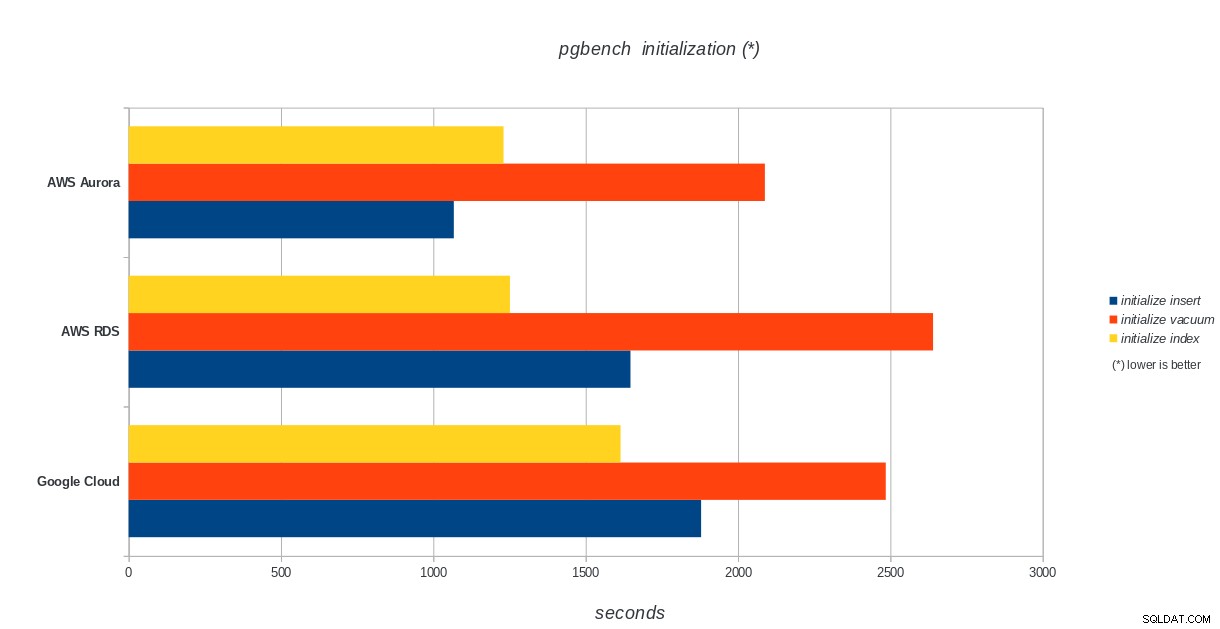 AWS Aurora, AWS RDS, Google Cloud SQL:resultados de inicialización de pgbench de PostgreSQL
AWS Aurora, AWS RDS, Google Cloud SQL:resultados de inicialización de pgbench de PostgreSQL ejecutar pgbench
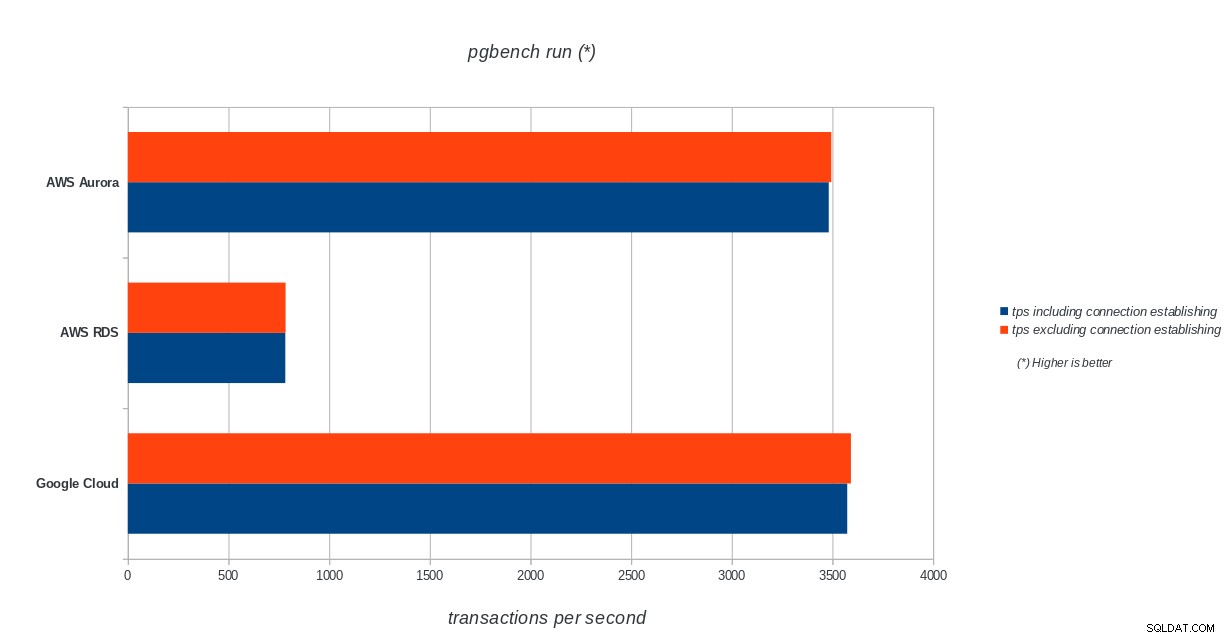 AWS Aurora, AWS RDS, Google Cloud SQL:resultados de la ejecución de PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL:resultados de la ejecución de PostgreSQL pgbench banco de sistema
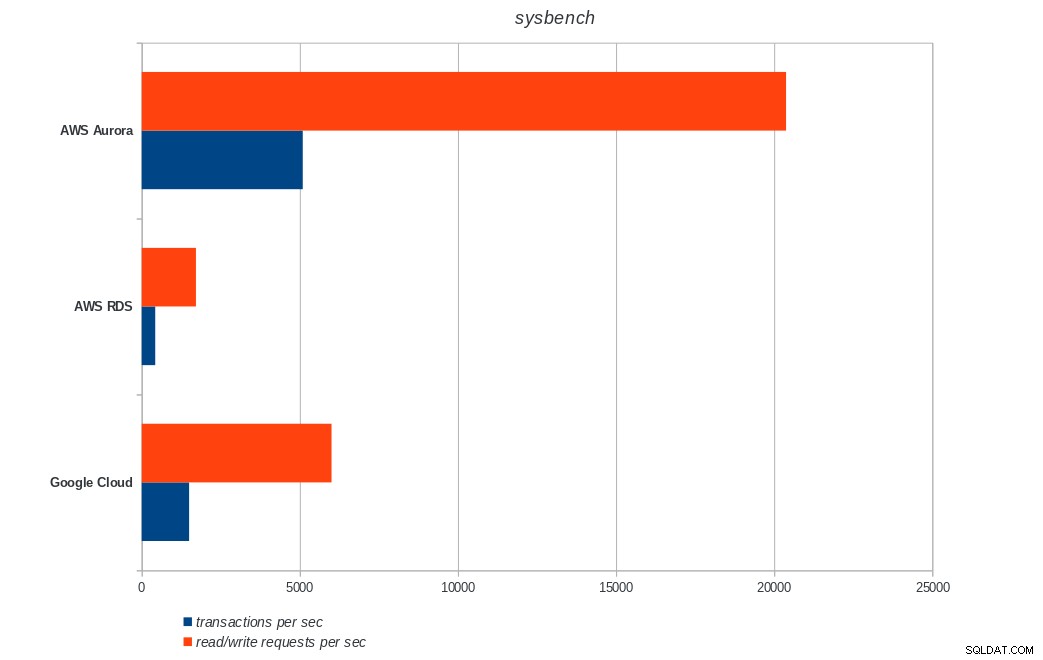 AWS Aurora, AWS RDS, Google Cloud SQL:resultados de Sysbench de PostgreSQL
AWS Aurora, AWS RDS, Google Cloud SQL:resultados de Sysbench de PostgreSQL Conclusión
Amazon Aurora ocupa el primer lugar con diferencia en las pruebas de escritura pesada (sysbench), mientras que está a la par con Google Cloud SQL en las pruebas de lectura/escritura de pgbench. La prueba de carga (inicialización de pgbench) coloca a Google Cloud SQL en primer lugar, seguido de Amazon RDS. Basándome en una mirada superficial a los modelos de precios para AWS Aurora y Google Cloud SQL, me atrevería a decir que Google Cloud es una mejor opción para el usuario promedio, mientras que AWS Aurora es más adecuado para entornos de alto rendimiento. Seguirán más análisis después de completar todos los puntos de referencia.
La siguiente y última parte de esta serie de referencias estará en Microsoft Azure PostgreSQL.
Gracias por leer y comente a continuación si tiene comentarios.



