Esta es la cuarta y última parte de la serie Benchmarking Managed PostgreSQLCloud Solutions . Al momento de escribir este artículo, Microsoft Azure PostgreSQL estaba en la versión 10.7, más reciente que los dos competidores:Amazon Aurora PostgreSQL en la versión 10.6 y Google Cloud SQL para PostgreSQL en la versión 9.6.
Microsoft decidió ejecutar Azure PostgreSQL en Windows:
postgres=> select version();
version
------------------------------------------------------------
PostgreSQL 10.7, compiled by Visual C++ build 1800, 64-bit
(1 row)Para esta prueba en particular, no funcionó muy bien, y me aventuro a suponer que Microsoft es muy consciente de las limitaciones, razón por la cual, bajo el paraguas de PostgreSQL, también ofrecen una versión preliminar de la versión Citus Data de PostgreSQL. El enfoque se parece a los tipos de AWS PostgreSQL, RDS y Aurora, respectivamente.
Como nota al margen, mientras configuraba mi cuenta de Azure, me sorprendió la falta de autenticación 2FA/MFA (dos factores/multifactor) que daba por sentado con AWS Virtual MFA de Amazon y la verificación en dos pasos de Google. Microsoft ofrece MFA solo a clientes empresariales suscritos a Active Directory u Office 365. Dado que Citus Cloud aplica 2FA para la base de datos de producción, quizás Microsoft no esté tan lejos de implementarlo en Azure.
TL;DR
No hay resultados para Azure. En la instancia de la base de datos de 8 núcleos, idéntica en la cantidad de núcleos a los utilizados en AWS y G Cloud, las pruebas no se completaron debido a errores en la base de datos. En una instancia de 16 núcleos, pgbench se completó y sysbench llegó tan lejos como para crear las primeras 3 tablas, momento en el que interrumpí el proceso. Si bien estaba dispuesto a gastar una cantidad razonable de esfuerzo, tiempo y dinero en realizar las pruebas y documentar los errores y sus causas, el objetivo de este ejercicio era ejecutar el punto de referencia, por lo tanto, nunca consideré buscar una solución de problemas avanzada o contactar soporte de Azure, ni terminé la prueba de sysbench en la base de datos de 16 núcleos.
Instancias en la nube
Cliente
La instancia de cliente de Azure más cercana a la instancia de AWS seleccionada al comienzo de esta serie de blogs era una instancia E32s v3 con las siguientes especificaciones:
- vCPU:32 (16 núcleos x 2 subprocesos/núcleo)
- RAM:256 GiB
- Almacenamiento:Azure Premium SSD
- Red:Redes aceleradas de hasta 30 Gbps
Aquí hay una captura de pantalla del portal con los detalles de la instancia:
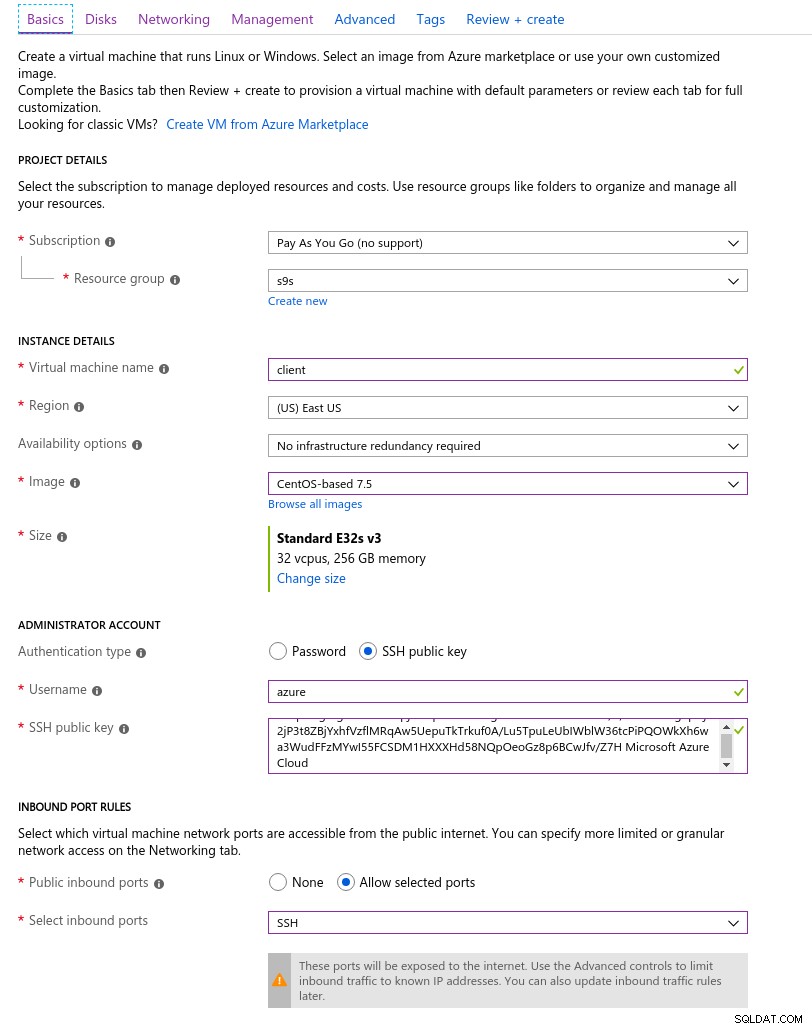 Detalles de la instancia del cliente
Detalles de la instancia del cliente Accelerated Networking está habilitado de forma predeterminada al elegir cualquiera de las máquinas virtuales compatibles:
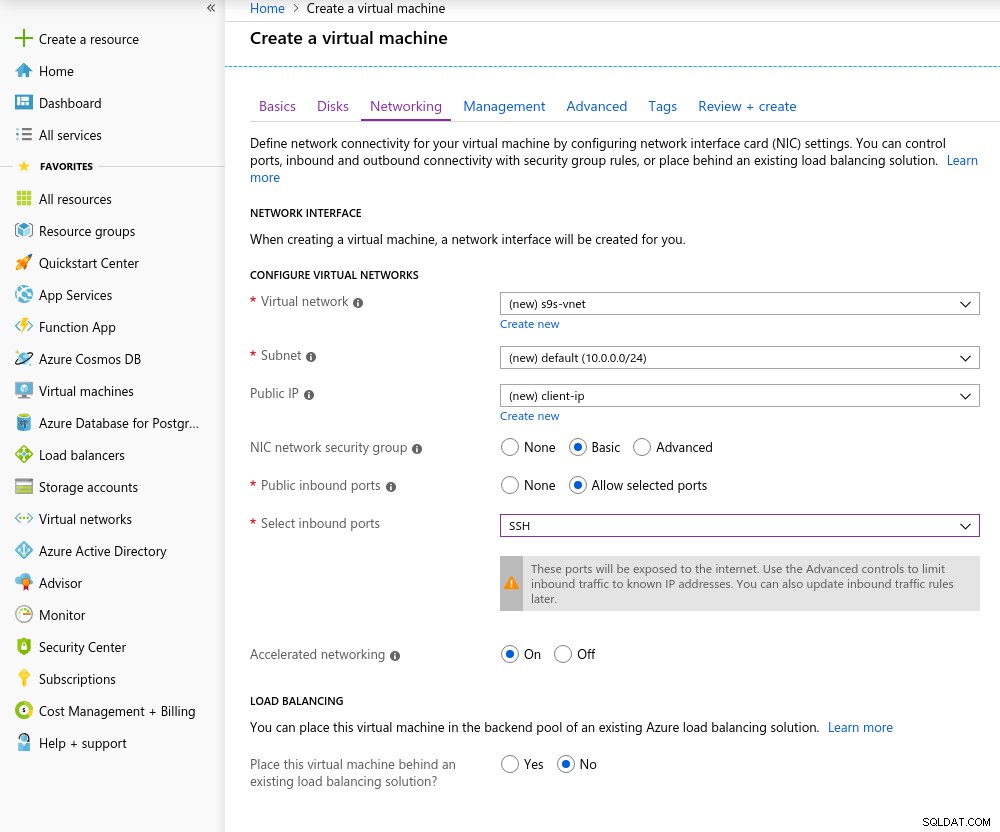 Acceso de red acelerado
Acceso de red acelerado Como es la regla en la nube, para lograr el mejor rendimiento de la red, el cliente y el servidor deben estar ubicados en la misma zona de disponibilidad, lo cual hice configurando el entorno en el Este de EE. UU. AZ.
De manera similar a Google Cloud, se debe solicitar un aumento de cuota para instancias con más de 10 núcleos. Microsoft lo hizo realmente fácil. Una vez que cambié a una cuenta paga, recibí la confirmación de aprobación antes de que pudiera terminar mi respuesta en el ticket explicando por qué estoy solicitando el aumento.
Base de datos
Al seleccionar el tamaño de la instancia, intenté hacer coincidir las especificaciones de las instancias utilizadas en AWS y Google Cloud:
- vCPU:8
- RAM:80 GiB (máximo)
- Almacenamiento:6000 IOPS (tamaño de 2 TiB a 3 IOPS/GB)
- Red:2000 MB/s
El tamaño de memoria bajo se debe a la fórmula de memoria por núcleo virtual utilizada para asignar memoria:
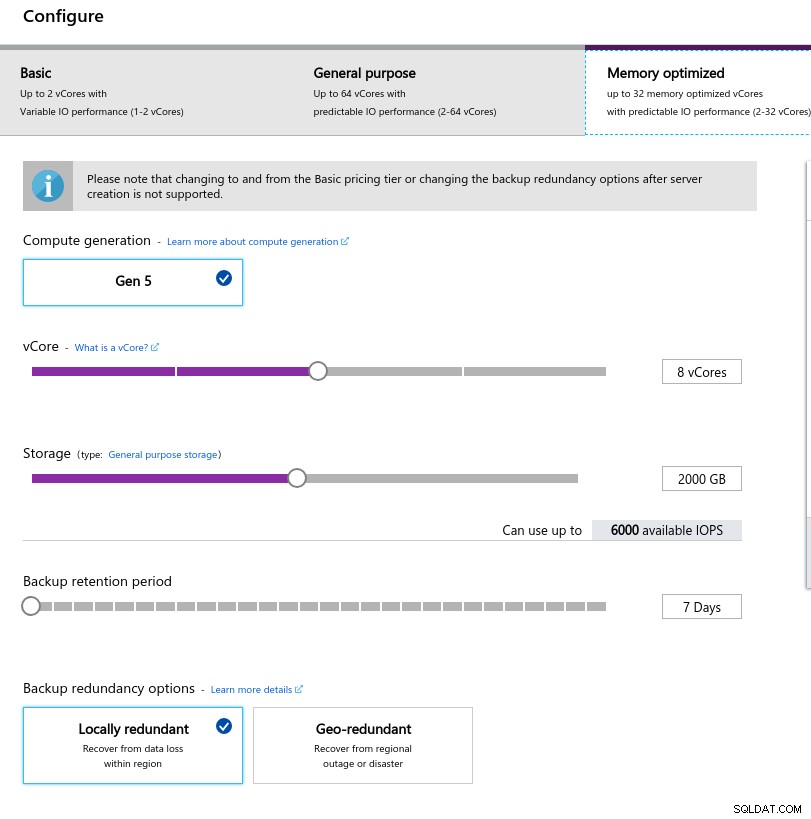 Configuración de instancia de base de datos
Configuración de instancia de base de datos De forma similar a Google Cloud, y a diferencia de AWS, cuanto mayor sea el almacenamiento, mayor será el IOPS, con un aumento de la proporción de 3:1; sin embargo, una vez que el tamaño alcanza los 2 TiB, el IOPS se limita a 6000 IOPS.
Ejecución de los puntos de referencia
Configuración
La configuración siguió el proceso descrito en partes anteriores de la serie de blogs, con el parche de temporización de AWS pgbench para 11.1 aplicándose limpiamente a Azure PostgreSQL versión 10.7. Los parches también se pueden obtener de las contribuciones de AWS Labs al repositorio PostgreSQL Github.
En el transcurso de la ejecución de los puntos de referencia, utilicé el siguiente script que solo sigue la guía de Amazon y, en este caso, está diseñado para la versión de PostgreSQL en Azure (10.7). La máquina cliente ejecuta CentOS 7.5:
#!/bin/bash
set -eE
trap "exit 1" ERR
yum -y install \
wget ant git php gnuplot gcc make readline-devel zlib-devel \
postgresql-jdbc bzr automake libtool patch libevent-devel \
openssl-devel ncurses-devel
wget https://ftp.postgresql.org/pub/source/v10.7/postgresql-10.7.tar.gz
rm -rf postgresql-10.7
tar -xzf postgresql-10.7.tar.gz
cd postgresql-10.7
wget https://s3.amazonaws.com/aurora-pgbench-patches/pgbench-init-timing.patch
patch --verbose -p1 -b < pgbench-init-timing.patch
./configure
make -j 4 all
make install
cd ..
rm -rf sysbench
git clone -b 0.5 https://github.com/akopytov/sysbench.git
cd sysbench
./autogen.sh
CFLAGS="-L/usr/local/pgsql/lib/ -I /usr/local/pgsql/include/" \
| ./configure \
--with-pgsql \
--without-mysql \
--with-pgsql-includes=/usr/local/pgsql/include/ \
--with-pgsql-libs=/usr/local/pgsql/lib/
make
make install
cd sysbench/tests
make install
sed -i \
'/^export PGHOST=/,/^export LD_LIBRARY_PATH.*pgsql/d' \
~/.bashrc
cat << "__eot__" >> ~/.bashrc
export PGHOST=CHANGEME
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=/usr/local/pgsql/bin:/usr/local/bin:$PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
__eot__
echo "All done."Una vez que se complete el script, edite .bashrc para establecer las variables de entorno de PostgreSQL. Azure es peculiar sobre el formato del nombre de usuario de PostgreSQL al esperar un formato {nombre de usuario}@{host} en lugar del omnipresente {nombre de usuario}:
[[email protected] scripts]# psql
psql: FATAL: Invalid Username specified. Please check the Username and retry connection. The Username should be in <[email protected]> format.Antes de comenzar las pruebas, verifique que estamos usando la versión correcta de las herramientas del cliente:
[[email protected] scripts]# psql --version
psql (PostgreSQL) 10.7[[email protected] scripts]# pgbench --version
pgbench (PostgreSQL) 10.7[[email protected] scripts]# sysbench --version
sysbench 0.5pgench
Inicialice la base de datos pgbench.
[[email protected] ~]# pgbench -i --fillfactor=90 --scale=10000…y varios minutos después:
[[email protected] scripts]# pgbench -i --fillfactor=90 --scale=10000
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.04 s, remaining 426.44 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 427.22 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.18 s, remaining 600.63 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 530.99 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.30 s, remaining 595.12 s)
...
584300000 of 1000000000 tuples (58%) done (elapsed 2421.82 s, remaining 1723.01 s)
584400000 of 1000000000 tuples (58%) done (elapsed 2421.86 s, remaining 1722.32 s)
584500000 of 1000000000 tuples (58%) done (elapsed 2422.81 s, remaining 1722.29 s)
584600000 of 1000000000 tuples (58%) done (elapsed 2422.84 s, remaining 1721.60 s)
584700000 of 1000000000 tuples (58%) done (elapsed 2422.88 s, remaining 1720.92 s)
584800000 of 1000000000 tuples (58%) done (elapsed 2425.06 s, remaining 1721.76 s)
584900000 of 1000000000 tuples (58%) done (elapsed 2425.09 s, remaining 1721.07 s)
585000000 of 1000000000 tuples (58%) done (elapsed 2425.28 s, remaining 1720.50 s)
...
999700000 of 1000000000 tuples (99%) done (elapsed 4142.69 s, remaining 1.24 s)
999800000 of 1000000000 tuples (99%) done (elapsed 4142.95 s, remaining 0.83 s)
999900000 of 1000000000 tuples (99%) done (elapsed 4142.98 s, remaining 0.41 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 4143.92 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 14805.73 s (insert 4146.94 s, commit 0.02 s, vacuum 6581.15 s, index 4077.61 s)
done.Hasta ahora todo bien.
Una mirada rápida a la base de datos para confirmar que está lista para funcionar:
[email protected]:5432 postgres> \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Table space | Description
-------------------+-----------------+----------+----------------------------+----------------------------+-------------------------------------+-----------+------------+--------------------------------------------
azure_maintenance | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | azure_superuser=CTc/azure_superuser | No Access | pg_default |
azure_sys | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | | 12 MB | pg_default |
postgres | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | | 160 GB | pg_default | default administrative connection database
template0 | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | =c/azure_superuser +| 7865 kB | pg_default | unmodifiable empty database
| | | | | azure_superuser=CTc/azure_superuser | | |
template1 | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | =c/azure_superuser +| 7865 kB | pg_default | default template for new databases
| | | | | azure_superuser=CTc/azure_superuser | | |
(5 rows)Dado que Azure no permite cambiar max_connections y dado que para la instancia seleccionada el límite está limitado a 960, tendremos que ajustar la cantidad de clientes de pgbench en consecuencia:
[[email protected] scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
could not translate host name "postgresql-10-7.postgres.database.azure.com" to address: Name or service not known
connection to database "postgres" failed:
could not translate host name "postgresql-10-7.postgres.database.azure.com" to address: Name or service not knownY ahí está, el primer contratiempo.
Una comprobación rápida de la resolución DNS del host no muestra ningún problema:
[[email protected] scripts]# dig +short $PGHOST
cr1.eastus1-a.control.database.windows.net.
191.238.6.43[[email protected] scripts]# cat /etc/resolv.conf
; generated by /usr/sbin/dhclient-script
search 11jv1qvdjs5utlhtlyb5vdyeth.bx.internal.cloudapp.net
nameserver 168.63.129.16Una revisión de mi registro de pantalla muestra que casi la mitad de las conexiones terminaron:
~$ cat screenlog.1 | nl | grep 'could not translate host name "postgresql-10-7.*Name or service not known' | wc -l
469pg_stat_activity cuenta una historia más detallada:alcanzamos un pico de 950 conexiones:
[email protected]:5432 postgres> select now(), count(*) from pg_stat_activity where usename = 'postgres' and application_name = 'pgbench'; now | count
-------------------------------+-------
2019-05-03 23:39:18.200291+00 | 950
(1 row)…sin embargo, el seguimiento de la consulta anterior muestra una caída repentina en el número de conexiones de 950 a 628, en solo 10 segundos:
[email protected]:5432 postgres> \watch 10
Fri 03 May 2019 11:41:05 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:41:05.044025+00 | 950
(1 row)
...
Fri 03 May 2019 11:43:10 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:10.512766+00 | 950
(1 row)
Fri 03 May 2019 11:43:20 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:17.419011+00 | 628
(1 row)
Fri 03 May 2019 11:43:30 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:31.434638+00 | 613
(1 row)Para solucionar el problema de DNS, asigné a PGHOST la dirección IP del host:
[[email protected] scripts]# set | grep PG
PGDATABASE=postgres
PGHOST=191.238.6.43
[email protected]
PGPORT=5432
[email protected]Con esa solución en su lugar, reinicié la prueba:
[[email protected] scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
progress: 61.1 s, 457.7 tps, lat 559.138 ms stddev 1755.888
progress: 120.1 s, 78.8 tps, lat 3883.772 ms stddev 10551.545
progress: 180.1 s, 17.6 tps, lat 50831.708 ms stddev 31214.512
progress: 240.1 s, 15.2 tps, lat 42474.763 ms stddev 32702.050
progress: 300.1 s, 16.1 tps, lat 43584.559 ms stddev 29818.142
progress: 360.1 s, 26.5 tps, lat 36914.096 ms stddev 37152.588
progress: 420.0 s, 33.4 tps, lat 27542.926 ms stddev 37075.457
progress: 480.0 s, 20.2 tps, lat 47149.060 ms stddev 47087.474
progress: 540.0 s, 13.5 tps, lat 55609.260 ms stddev 60394.287
progress: 600.0 s, 36.5 tps, lat 49566.853 ms stddev 99155.598
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 950
number of threads: 950
duration: 600 s
number of transactions actually processed: 44293
latency average = 12493.888 ms
latency stddev = 40490.231 ms
tps = 60.907130 (including connections establishing)
tps = 64.213520 (excluding connections establishing)A primera vista, las cosas parecían haber funcionado bien, sin embargo, los valores de latencia extremadamente altos, junto con los problemas de DNS anteriores y el cliente habilitado para "redes aceleradas", sugieren que algo anda mal a nivel de red, y esa es la probabilidad. causa de resultados bajos de tps. Pero lo peor está por venir.
Descargue el documento técnico hoy Gestión y automatización de PostgreSQL con ClusterControl Obtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnicobanco de sistema
Primero, crea las tablas:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepare
After a little while:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
FATAL: PQexec() failed: 7 server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
FATAL: failed query: CREATE TABLE sbtest1 (
id SERIAL NOT NULL,
k INTEGER DEFAULT '0' NOT NULL,
c CHAR(120) DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY (id)
)
FATAL: failed to execute function `prepare': 3Eso no se veía nada bien, así que revisé los registros de PostgreSQL:
2019-05-03 23:51:12 UTC-5ccbbe4f.88-WARNING: worker took too long to start; canceled
2019-05-03 23:51:14 UTC-5ccbbe4f.84-PANIC: could not write to log file 000000010000001F000000CD at offset 13664256, length 8192: Invalid argument
+++ NT HARD ERROR (0xd0000144) +++
Parameter 0: 0xffffffffc0000005
Parameter 1: 0x1b80f0f73b
Parameter 2: 0x1
Parameter 3: 0x0Aunque el servicio debería recuperarse por sí solo, decidí reiniciar la instancia para acelerar el proceso.
2019-05-04 00:43:23 UTC-5ccce02a.2c-HINT: Is another postmaster already running on port 20108? If not, wait a few seconds and retry.
2019-05-04 00:43:23 UTC-5ccce02a.2c-LOG: could not bind IPv6 address "::": A socket operation was attempted to an unreachable host.
2019-05-04 00:43:23 UTC-5ccce02a.2c-LOG: listening on IPv4 address "0.0.0.0", port 20108
2019-05-04 00:43:24 UTC-5ccce02a.2c-LOG: database system is ready to accept connections
...
2019-05-05 00:03:35 UTC-5cce2856.2c-HINT: Is another postmaster already running on port 20326? If not, wait a few seconds and retry.
2019-05-05 00:03:35 UTC-5cce2856.2c-LOG: could not bind IPv6 address "::": A socket operation was attempted to an unreachable host.
2019-05-05 00:03:35 UTC-5cce2856.2c-LOG: listening on IPv4 address "0.0.0.0", port 20326
2019-05-05 00:03:38 UTC-5cce285a.3c-FATAL: the database system is starting up
2019-05-05 00:03:38 UTC-5cce285a.3c-LOG: connection received: host=127.0.0.1 port=47247 pid=60
2019-05-05 00:03:49 UTC-5cce2865.40-FATAL: the database system is starting up
2019-05-05 00:03:49 UTC-5cce2865.40-LOG: connection received: host=127.0.0.1 port=47284 pid=64
2019-05-05 00:03:59 UTC-5cce286f.44-FATAL: the database system is starting up
2019-05-05 00:03:59 UTC-5cce286f.44-LOG: connection received: host=127.0.0.1 port=47312 pid=68
2019-05-05 00:04:00 UTC-5cce2856.2c-LOG: database system is ready to accept connections
2019-05-05 00:04:00 UTC-5cce2870.38-LOG: database system was shut down at 2019-05-05 00:03:34 UTCEn este punto, también habilité información sobre el rendimiento de las consultas:
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: parameter "pgms_wait_sampling.query_capture_mode" changed to "ALL"
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: parameter "pg_qs.query_capture_mode" changed to "TOP"
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: received SIGHUP, reloading configuration files
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: received SIGHUP, reloading configuration files
2019-05-05 00:04:13 UTC-5cce287a.6c-ERROR: database "azure_sys" already exists
2019-05-05 00:04:13 UTC-5cce287a.6c-STATEMENT: CREATE DATABASE azure_sys TEMPLATE template0Antes de reiniciar la tarea de sysbench, quería asegurarme de que la base de datos estuviera en buen estado y, por lo tanto, encendí una segunda prueba de pgbench:
[[email protected] scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.Según el monitor de consultas pg_stat_activity, el servidor murió cuando el número de conexiones llegó a 710:
[email protected]:5432 postgres> \watch 1
Sun 05 May 2019 12:44:11 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:44:11.010413+00 | 220
(1 row)
Sun 05 May 2019 12:44:12 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:44:12.041667+00 | 231
(1 row)
...
now | count
------------------------------+-------
2019-05-05 00:47:33.16533+00 | 710
(1 row)
Sun 05 May 2019 12:47:40 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:47:40.524662+00 | 710
(1 row)Y de los registros de PostgreSQL nos enteramos de que algo sucedió a lo largo de la tubería de conexión:
2019-05-05 00:44:11 UTC-5cce31da.c60-LOG: connection received: host=40.114.85.62 port=50925 pid=3168
2019-05-05 00:44:11 UTC-5cce31db.c58-LOG: connection received: host=40.114.85.62 port=55256 pid=3160
2019-05-05 00:44:11 UTC-5cce31db.c5c-LOG: connection received: host=40.114.85.62 port=34526 pid=3164
2019-05-05 00:44:11 UTC-5cce31db.c64-LOG: connection received: host=40.114.85.62 port=1178 pid=3172
...
2019-05-05 00:47:32 UTC-5cce329a.146c-LOG: connection received: host=40.114.85.62 port=41769 pid=5228
2019-05-05 00:47:33 UTC-5cce3287.1404-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3288.1428-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3289.1434-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3291.1448-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce32a3.1484-LOG: connection received: host=40.114.85.62 port=50296 pid=5252
2019-05-05 00:47:33 UTC-5cce32a5.1488-LOG: connection received: host=40.114.85.62 port=28304 pid=5256
2019-05-05 00:47:39 UTC-5cce31d2.a24-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31d5.ae8-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31e3.ee4-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31e9.1054-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce3291.1444-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:40 UTC-5cce31cd.8ec-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.Ante la limitación de max_connections y los problemas encontrados durante las pruebas de pgbench y sysbench, comencé a sentir curiosidad por saber si una base de datos de 16 núcleos exhibiría el mismo comportamiento.
Instancia de base de datos de 16 núcleos
En una instancia de base de datos de 16 núcleos, el límite max_connections es lo suficientemente grande como para acomodar 1000 clientes:
[email protected]:5432 postgres> show max_connections ;
max_connections
-----------------
1900
(1 row)Eso me permitió ejecutar los mismos comandos de referencia que usé en los proveedores de nube anteriores.
El punto de referencia se completó con éxito y los resultados se muestran a continuación:
banco pg
- Inicialización:
[[email protected] scripts]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.08 s, remaining 807.39 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 628.37 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.16 s, remaining 527.89 s) ... 600100000 of 1000000000 tuples (60%) done (elapsed 2499.90 s, remaining 1665.90 s) 600200000 of 1000000000 tuples (60%) done (elapsed 2500.07 s, remaining 1665.33 s) ... 999900000 of 1000000000 tuples (99%) done (elapsed 4170.91 s, remaining 0.42 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 4171.29 s, remaining 0.00 s) vacuum... set primary keys... total time: 13701.50 s (insert 4173.33 s, commit 0.05 s, vacuum 7098.74 s, index 2429.39 s) done. - Ejecutar:
[[email protected] scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048 starting vacuum...end. progress: 81.4 s, 5639.1 tps, lat 80.094 ms stddev 73.213 progress: 120.0 s, 4091.0 tps, lat 224.161 ms stddev 608.523 progress: 180.0 s, 6932.1 tps, lat 145.143 ms stddev 228.925 progress: 240.0 s, 7287.9 tps, lat 136.521 ms stddev 156.643 progress: 300.0 s, 7567.8 tps, lat 132.722 ms stddev 158.754 progress: 360.0 s, 8077.9 tps, lat 123.801 ms stddev 139.033 progress: 420.0 s, 6076.9 tps, lat 163.886 ms stddev 201.121 progress: 480.0 s, 5376.2 tps, lat 186.678 ms stddev 191.270 progress: 540.0 s, 4864.0 tps, lat 205.696 ms stddev 164.261 progress: 600.0 s, 3759.3 tps, lat 266.073 ms stddev 542.717 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 3614386 latency average = 152.935 ms latency stddev = 248.593 ms tps = 6002.082008 (including connections establishing) tps = 6513.306467 (excluding connections establishing)
Eso salió razonablemente bien, sin embargo, no hay una forma válida de comparar estos resultados con los de AWS y G Cloud, ya que no estamos probando en una plataforma similar. Pero esto es lo suficientemente bueno para llevarnos al siguiente punto.
banco de sistema
Como las pruebas de pgbench se completaron con éxito, decidí aprovechar al máximo el crédito de $200 de Azure y confirmar que sysbench llega más lejos que la ejecución anterior en la instancia de 8 núcleos:
sysbench \
--test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=191.238.6.43 \
--pgsql-db=postgres \
[email protected] \
[email protected] \
--pgsql-port=5432 \
--oltp-tables-count=250 \
--oltp-table-size=450000 prepare
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
Creating secondary indexes on 'sbtest2'...
Creating table 'sbtest3'...
Inserting 450000 records into 'sbtest3'
Creating secondary indexes on 'sbtest3'...
Creating table 'sbtest4'...Eso parecía estar funcionando bien, y dado que me estaba acercando a mi presupuesto, decidí detener la tarea.
Hiperescala (Citus)
Aunque no está lista para la producción, esta opción merece ser analizada, ya que proporciona características avanzadas que no están disponibles en AWS y G Cloud.
Como resultado de la adquisición de Citus Data, Microsoft ofrece una versión preliminar de su producto insignia PostgreSQL, bajo el nombre de Hiperescala (Citus).
El asistente del portal hace que la configuración de un entorno complicado sea muy sencilla:
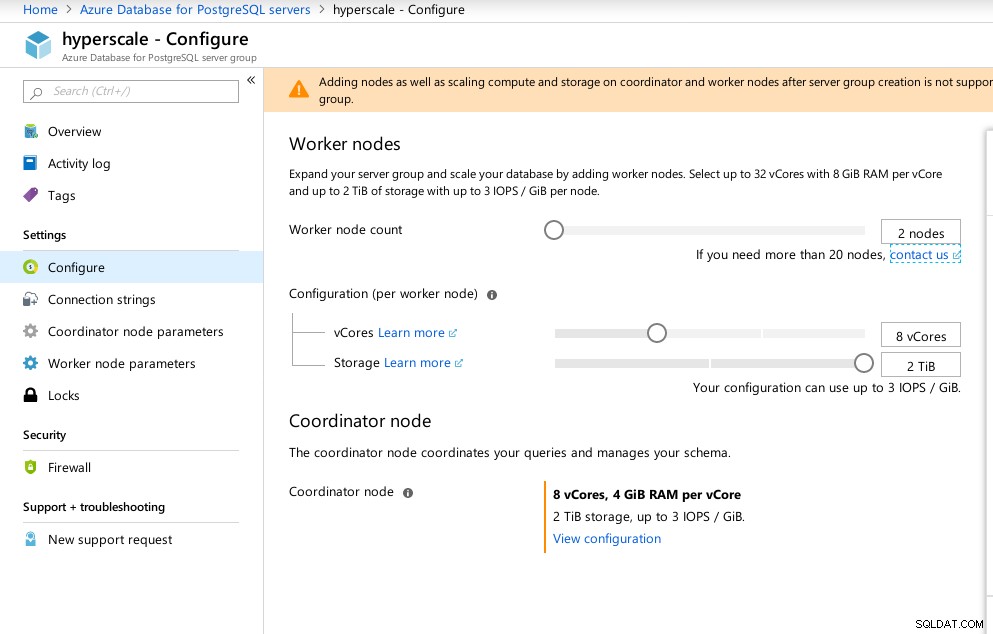 Configuración de hiperescala de Azure (Citus)
Configuración de hiperescala de Azure (Citus) Observé que, a diferencia de Azure PostgreSQL, que se ejecuta en Windows, Hiperescala se ejecuta en Linux:
[email protected]:5432 citus> select version();
version
----------------------------------------------------------------------------------------------------------------
PostgreSQL 11.2 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609, 64-bit
(1 row)Desafortunadamente, aunque Hiperescala prometía un viaje emocionante, en este momento no pude seguir adelante con la ejecución de las pruebas ya que max_connections actualmente tiene un límite de 300, sin opción de ajuste, aunque la capacidad está documentada para Citus PosgreSQL nativo:
[email protected]:5432 citus> show max_connections ;
max_connections
-----------------
300
(1 row)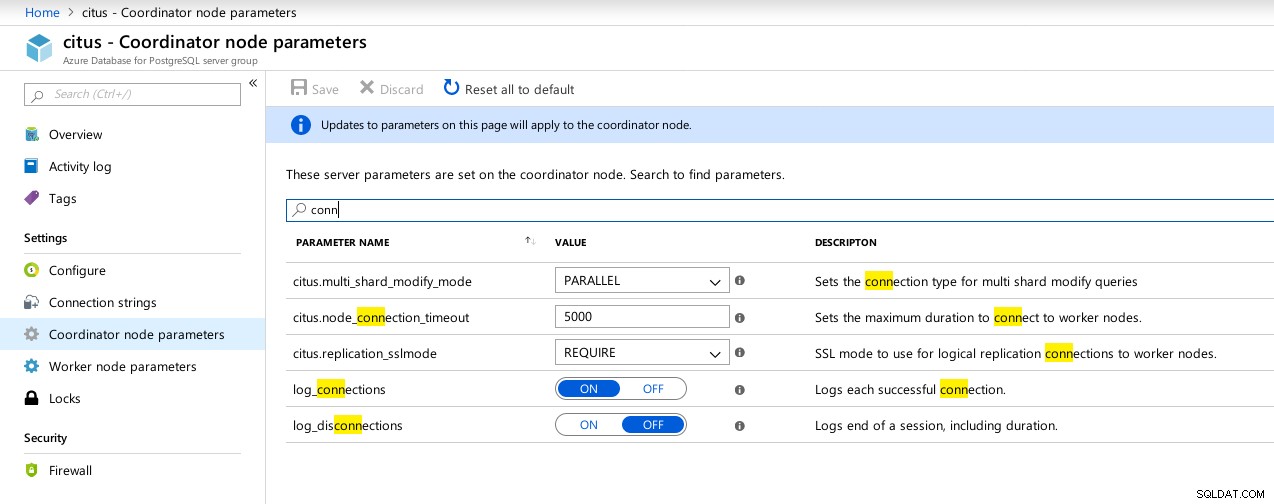 Parámetros disponibles de las conexiones del coordinador de hiperescala (Citus)
Parámetros disponibles de las conexiones del coordinador de hiperescala (Citus) 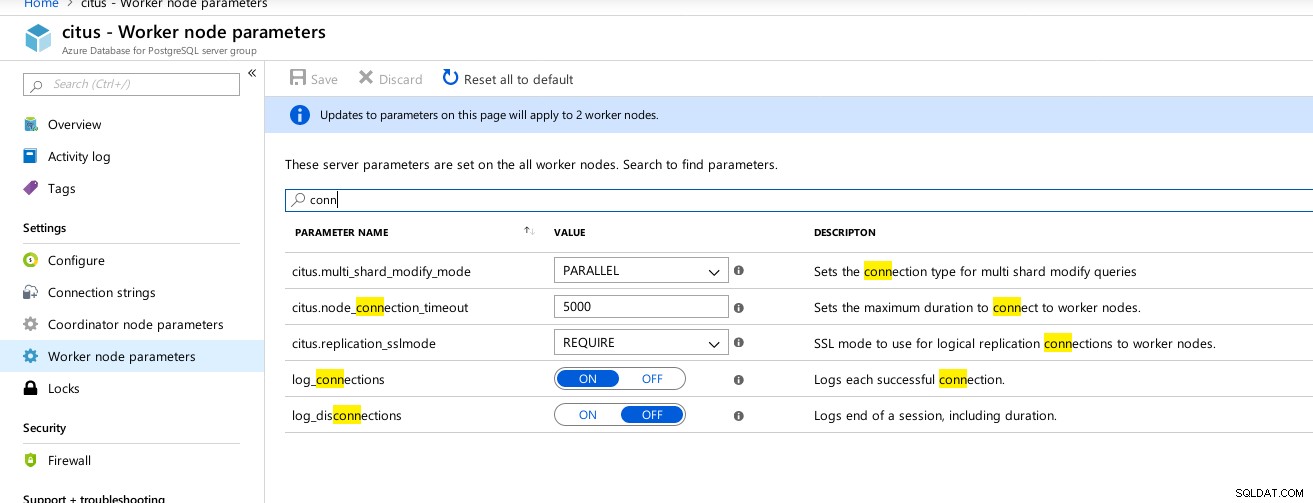 Trabajadores de hiperescala (Citus):max_connections no disponible
Trabajadores de hiperescala (Citus):max_connections no disponible Métricas comparativas
Algunas métricas indicativas del rendimiento y el comportamiento del cliente y del servidor:
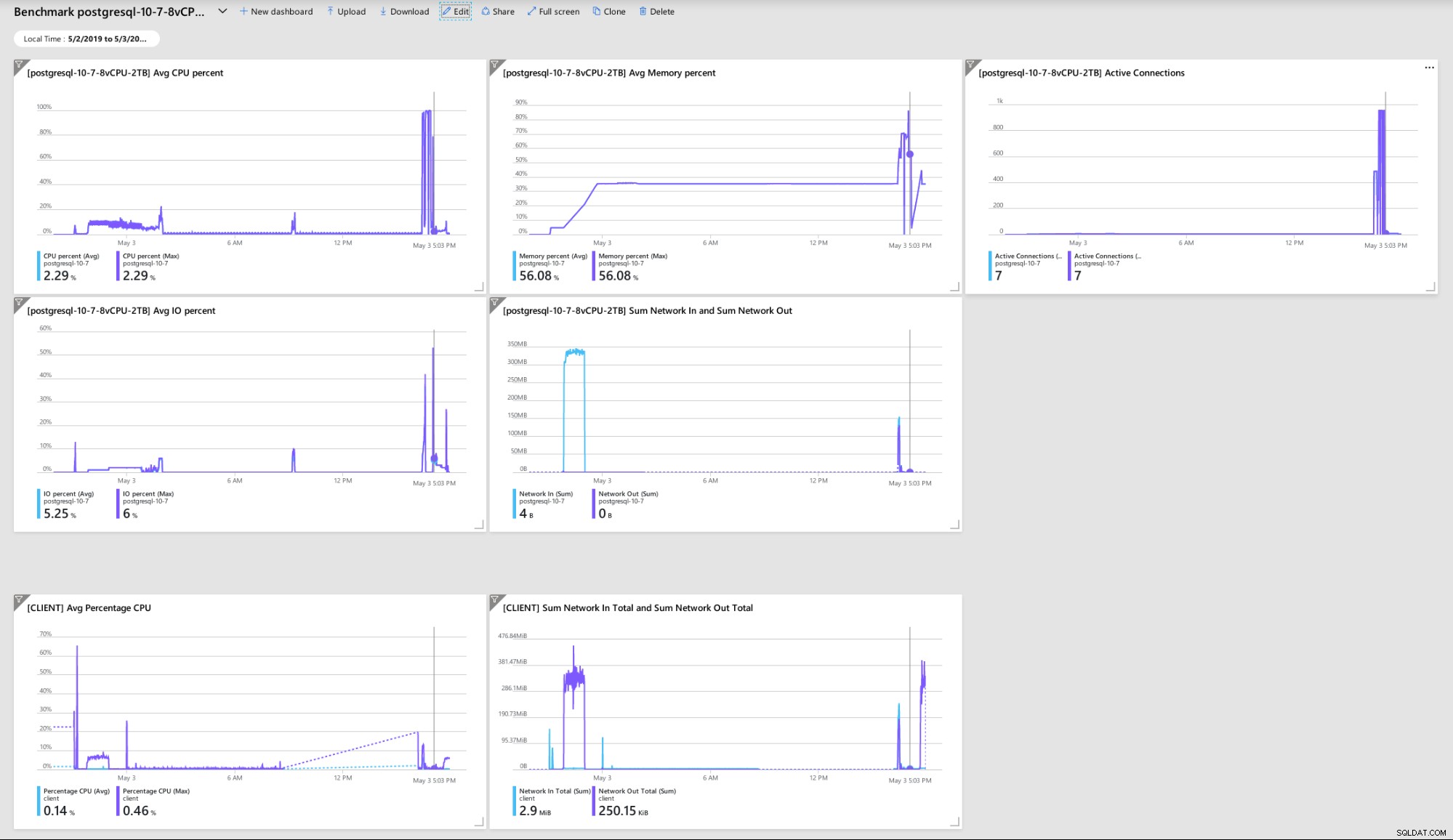 Panel de Azure Portal:métricas para el cliente y el servidor
Panel de Azure Portal:métricas para el cliente y el servidor Métricas de PostgreSQL recopiladas mediante Query Performance Insight:
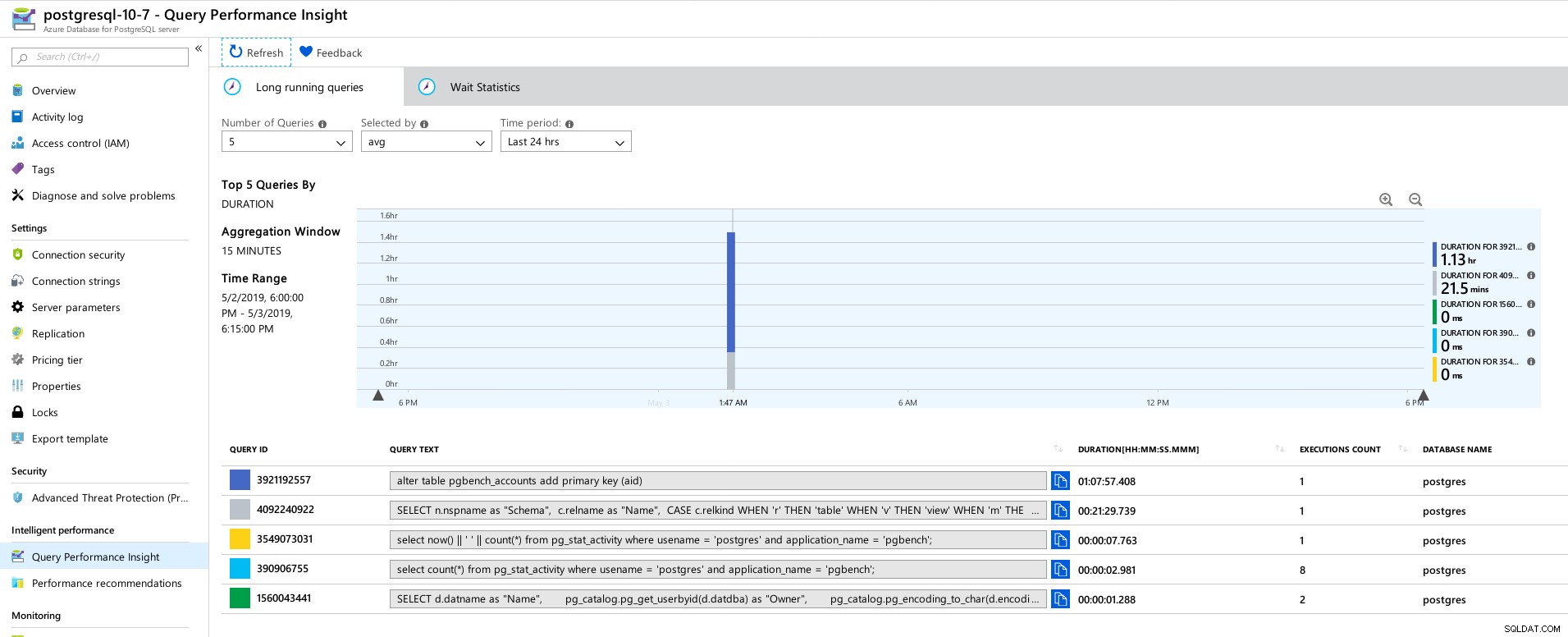 Azure PostgreSQL:información sobre el rendimiento de las consultas:5 consultas principales
Azure PostgreSQL:información sobre el rendimiento de las consultas:5 consultas principales 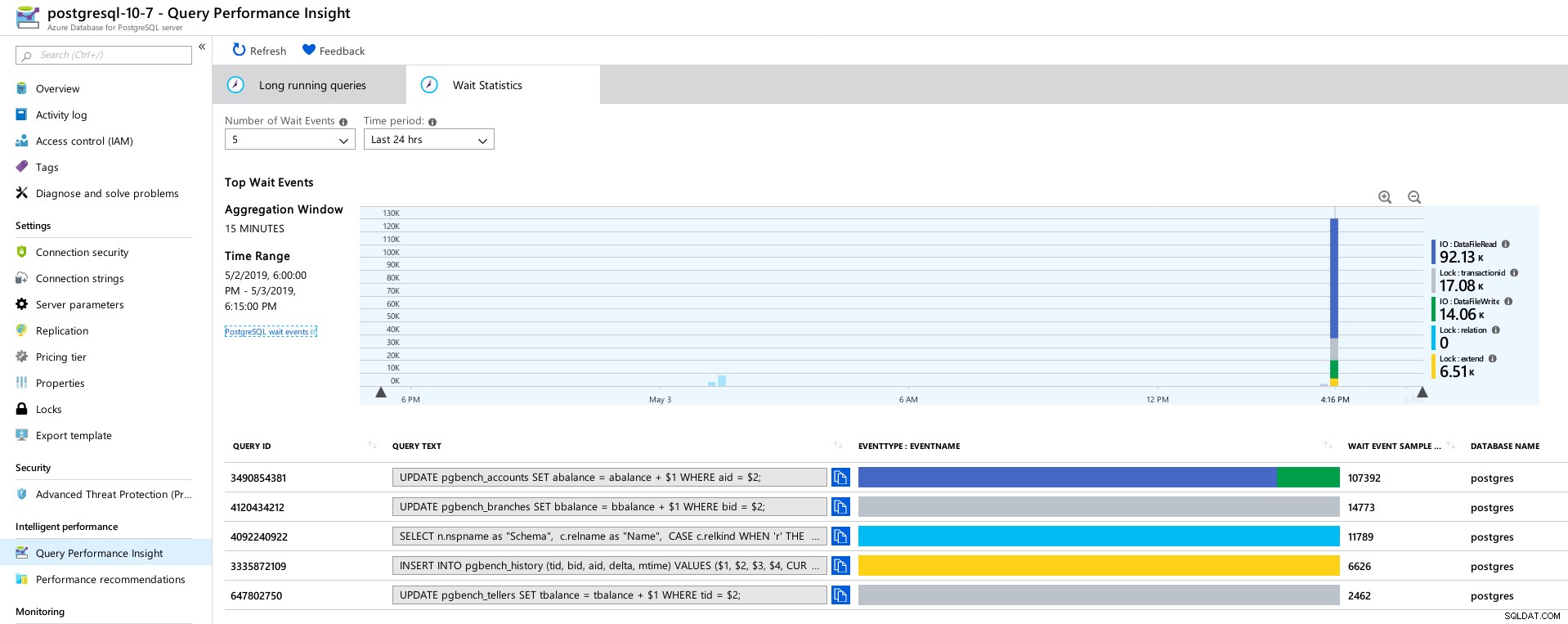 Azure PostgreSQL:información sobre el rendimiento de consultas:5 esperas principales
Azure PostgreSQL:información sobre el rendimiento de consultas:5 esperas principales Conclusión
Recursos relacionados Evaluación comparativa de soluciones en la nube de PostgreSQL administrado - Parte uno:Amazon Aurora Evaluación comparativa de soluciones en la nube de PostgreSQL administrado - Parte dos:Amazon RDS Evaluación comparativa de soluciones en la nube de PostgreSQL administrado - Parte tres:Google CloudPrimero, si llegaste hasta aquí, gracias por leer, y si detectas algún error que pueda haber causado que el entorno se comporte mal, agradecería mucho tus comentarios. Si me perdí algo obvio, estoy dispuesto a repetir las pruebas.
El bloqueo del motor de la base de datos que conduce al volcado hexadecimal "NT HARD ERROR" indica que sucedió algo fuera del control del usuario, y un buen servicio administrado se recuperaría mediante la automatización o alertando a los SRE a cargo. Si hubiera esperado más tiempo, ese podría haber sido el caso, aunque plantea la cuestión de cuánto tiempo deben esperar los usuarios hasta que se restablezca el servicio.
Bloquear max_connections a un valor basado en el nivel de precios y los núcleos virtuales me tomó por sorpresa, especialmente después de probar los otros tres servicios administrados, con Google Cloud permitiendo que el usuario configure el parámetro, aunque el valor predeterminado era mucho más bajo (600 en G Nube frente a 960 en Azure).
Es posible que se requiera una prueba con la instancia de la base de datos en el rango de 16 núcleos para evitar alterar los valores predeterminados, aunque en ese momento preferiría probar usando mejores herramientas, como HammerDB (consulte la Parte 1 para ver una discusión sobre las herramientas) .