Este blog inicia una serie múltiple que documenta mi viaje en la evaluación comparativa de PostgreSQL en la nube.
La primera parte incluye una descripción general de las herramientas de evaluación comparativa y comienza la diversión con Amazon Aurora PostgreSQL.
Selección de los proveedores de servicios en la nube de PostgreSQL
Hace un tiempo me encontré con el procedimiento de referencia de AWS para Aurora y pensé que sería genial si pudiera realizar esa prueba y ejecutarla en otros proveedores de alojamiento en la nube. Para crédito de Amazon, de los tres proveedores de servicios informáticos más conocidos (AWS, Google y Microsoft), AWS es el único contribuyente importante al desarrollo de PostgreSQL y el primero en ofrecer el servicio de PostgreSQL administrado (desde noviembre de 2013).
Si bien los servicios administrados de PostgreSQL también están disponibles en una gran cantidad de proveedores de alojamiento de PostgreSQL, quería centrarme en dichos tres proveedores de computación en la nube, ya que sus entornos son donde muchas organizaciones que buscan las ventajas de la computación en la nube eligen ejecutar sus aplicaciones, siempre que tengan los conocimientos necesarios sobre el manejo de PostgreSQL. Creo firmemente que en el panorama de TI actual, las organizaciones que trabajan con cargas de trabajo críticas en la nube se beneficiarían enormemente de los servicios de un proveedor de servicios de PostgreSQL especializado, que puede ayudarlos a navegar por el complejo mundo de GUCS y las innumerables presentaciones de SlideShare.
Selección de la herramienta de evaluación comparativa adecuada
La evaluación comparativa de PostgreSQL aparece con bastante frecuencia en la lista de correo de rendimiento y, como se destacó innumerables veces, las pruebas no están destinadas a validar una configuración para una aplicación de la vida real. Sin embargo, seleccionar la herramienta y los parámetros de referencia correctos es importante para recopilar resultados significativos. Espero que todos los proveedores de la nube proporcionen procedimientos para evaluar comparativamente sus servicios, especialmente cuando la primera experiencia en la nube puede no comenzar con el pie derecho. La buena noticia es que dos de los tres jugadores en esta prueba han incluido puntos de referencia en su documentación. La guía Procedimiento de referencia de AWS para Aurora es fácil de encontrar y está disponible en la página de recursos de Amazon Aurora. Google no proporciona una guía específica para PostgreSQL; sin embargo, la documentación de Compute Engine contiene una guía de prueba de carga para SQL Server basada en HammerDB.
A continuación, se incluye un resumen de las herramientas comparativas basadas en sus referencias que vale la pena consultar:
- La comparativa de AWS mencionada anteriormente se basa en pgbench y sysbench.
- HammerDB, también mencionado anteriormente, se analiza en una publicación reciente en la lista de pgsql-hackers.
- Pruebas de TPC-C basadas en oltpbench como se menciona en esta otra discusión sobre pgsql-hackers.
- benchmarksql es otra prueba de TPC-C que se usó para validar los cambios en las divisiones de página de B-Tree.
- pg_ycsb es el nuevo chico en la ciudad, mejora a pgbench y ya está siendo utilizado por algunos de los piratas informáticos de PostgreSQL.
- pgbench-tools, como sugiere su nombre, se basa en pgbench y, aunque no ha recibido ninguna actualización desde 2016, es el producto de Greg Smith, el autor de los libros de alto rendimiento de PostgreSQL.
- la prueba comparativa de orden de unión es una prueba comparativa que probará el optimizador de consultas.
- pgreplay, con el que me encontré mientras leía el blog del símbolo del sistema, es lo más cercano que puede llegar a compararse con un escenario de la vida real.
Otro punto a tener en cuenta es que PostgreSQL aún no es adecuado para el estándar de referencia TPC-H y, como se indicó anteriormente, todas las herramientas (excepto pgreplay) deben ejecutarse en modo TPC-C (pgbench lo usa de manera predeterminada).
A los fines de este blog, pensé que el Procedimiento de referencia de AWS para Aurora es un buen comienzo simplemente porque establece un estándar para los proveedores de la nube y se basa en herramientas ampliamente utilizadas.
Además, utilicé la última versión de PostgreSQL disponible en ese momento. Al seleccionar un proveedor de la nube, es importante tener en cuenta la frecuencia de las actualizaciones, especialmente cuando las características importantes introducidas por las nuevas versiones pueden afectar el rendimiento (como es el caso de las versiones 10 y 11 frente a la 9). A partir de este escrito tenemos:
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS para PostgreSQL 10.6
- Google Cloud SQL para PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
...y el ganador aquí es AWS al ofrecer la versión más reciente (aunque no es la última, que al momento de escribir este artículo es la 11.2).
Configuración del entorno de evaluación comparativa
Decidí limitar mis pruebas a cargas de trabajo promedio por un par de razones:primero, los recursos de la nube disponibles no son idénticos entre los proveedores. En la guía, las especificaciones de AWS para la instancia de la base de datos son 64 vCPU / 488 GiB RAM / 25 Gigabit Network, mientras que la RAM máxima de Google para cualquier tamaño de instancia (la opción debe configurarse como "personalizada" en Google Calculator) es 208 GiB, y Business Critical Gen5 de Microsoft con 32 vCPU viene con solo 163 GiB). En segundo lugar, la inicialización de pgbench lleva el tamaño de la base de datos a 160 GiB que, en el caso de una instancia con 488 GiB de RAM, es probable que se almacene en la memoria.
Además, dejé intacta la configuración de PostgreSQL. La razón para apegarse a los valores predeterminados del proveedor de la nube es que, de forma inmediata, cuando se estresa por un punto de referencia estándar, se espera que un servicio administrado funcione razonablemente bien. Recuerde que la comunidad de PostgreSQL ejecuta pruebas de pgbench como parte del proceso de gestión de versiones. Además, la guía de AWS no menciona ningún cambio en la configuración predeterminada de PostgreSQL.
Como se explica en la guía, AWS aplicó dos parches a pgbench. Dado que el parche para la cantidad de clientes no se aplicó correctamente en la versión 10.6 de PostgreSQL y no quería invertir tiempo en solucionarlo, la cantidad de clientes se limitó a un máximo de 1000.
La guía especifica un requisito para que la instancia del cliente tenga habilitada la red mejorada; para este tipo de instancia, ese es el valor predeterminado:
[[email protected] ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 0a:cd:ee:40:2b:e6 brd ff:ff:ff:ff:ff:ff
inet 172.31.19.190/20 brd 172.31.31.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::8cd:eeff:fe40:2be6/64 scope link
valid_lft forever preferred_lft forever
[[email protected] ~]$ ethtool -i eth0
driver: ena
version: 2.0.2g
firmware-version:
bus-info: 0000:00:03.0
supports-statistics: yes
supports-test: no
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: no
>>> aws (master *%) ~ $ aws ec2 describe-instances --instance-ids i-0ee51642334c1ec57 --query "Reservations[].Instances[].EnaSupport"
[
true
]Ejecución de Benchmark en Amazon Aurora PostgreSQL
Durante la ejecución real, decidí hacer una desviación más de la guía:en lugar de ejecutar la prueba durante 1 hora, establezca el límite de tiempo en 10 minutos, lo que generalmente se acepta como un buen valor.
Ejecutar #1
Específicos
- Esta prueba utiliza las especificaciones de AWS para los tamaños de instancia de cliente y de base de datos.
- Equipo cliente:Instancia EC2 optimizada para memoria bajo demanda:
- vCPU:32 (16 núcleos x 2 subprocesos/núcleo)
- RAM:244 GiB
- Almacenamiento:optimizado para EBS
- Red:10 Gigabits
- Clúster de base de datos:db.r4.16xlarge
- vCPU:64
- ECU (capacidad de la CPU):195 x [1,0-1,2 GHz] 2007 Opteron / Xeon
- RAM:488 GiB
- Almacenamiento:EBS optimizado (capacidad dedicada para E/S)
- Red:14 000 Mbps de ancho de banda máximo en una red de 25 Gps
- Equipo cliente:Instancia EC2 optimizada para memoria bajo demanda:
- La configuración de la base de datos incluía una réplica.
- El almacenamiento de la base de datos no estaba cifrado.
Realización de las pruebas y resultados
- Siga las instrucciones de la guía para instalar pgbench y sysbench.
- Edite ~/.bashrc para configurar las variables de entorno para la conexión de la base de datos y las rutas requeridas a las bibliotecas de PostgreSQL:
export PGHOST=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com export PGUSER=postgres export PGPASSWORD=postgres export PGDATABASE=postgres export PATH=$PATH:/usr/local/pgsql/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib - Inicialice la base de datos:
[[email protected] ~]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.05 s, remaining 457.23 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 631.70 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 688.29 s) ... 999500000 of 1000000000 tuples (99%) done (elapsed 811.41 s, remaining 0.41 s) 999600000 of 1000000000 tuples (99%) done (elapsed 811.50 s, remaining 0.32 s) 999700000 of 1000000000 tuples (99%) done (elapsed 811.58 s, remaining 0.24 s) 999800000 of 1000000000 tuples (99%) done (elapsed 811.65 s, remaining 0.16 s) 999900000 of 1000000000 tuples (99%) done (elapsed 811.73 s, remaining 0.08 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 811.80 s, remaining 0.00 s) vacuum... set primary keys... done. - Verifique el tamaño de la base de datos:
postgres=> \l+ postgres List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description ----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------------------------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 160 GB | pg_default | default administrative connection database (1 row) - Utilice la siguiente consulta para verificar que el intervalo de tiempo entre los puntos de control esté configurado para que los puntos de control se forcen durante la ejecución de 10 minutos:
Resultado:SELECT total_checkpoints, seconds_since_start / total_checkpoints / 60 AS minutes_between_checkpoints FROM ( SELECT EXTRACT( EPOCH FROM ( now() - pg_postmaster_start_time() ) ) AS seconds_since_start, (checkpoints_timed+checkpoints_req) AS total_checkpoints FROM pg_stat_bgwriter) AS sub;postgres=> \e total_checkpoints | minutes_between_checkpoints -------------------+----------------------------- 50 | 0.977392292333333 (1 row) - Ejecute la carga de trabajo de lectura/escritura:
Salida[[email protected] ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048starting vacuum...end. progress: 60.0 s, 35670.3 tps, lat 27.243 ms stddev 10.915 progress: 120.0 s, 36569.5 tps, lat 27.352 ms stddev 11.859 progress: 180.0 s, 35845.2 tps, lat 27.896 ms stddev 12.785 progress: 240.0 s, 36613.7 tps, lat 27.310 ms stddev 11.804 progress: 300.0 s, 37323.4 tps, lat 26.793 ms stddev 11.376 progress: 360.0 s, 36828.8 tps, lat 27.155 ms stddev 11.318 progress: 420.0 s, 36670.7 tps, lat 27.268 ms stddev 12.083 progress: 480.0 s, 37176.1 tps, lat 26.899 ms stddev 10.981 progress: 540.0 s, 37210.8 tps, lat 26.875 ms stddev 11.341 progress: 600.0 s, 37415.4 tps, lat 26.727 ms stddev 11.521 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 22040445 latency average = 27.149 ms latency stddev = 11.617 ms tps = 36710.828624 (including connections establishing) tps = 36811.054851 (excluding connections establishing) - Prepare la prueba de sysbench:
Salida:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250\ --oltp-table-size=450000 \ preparesysbench 0.5: multi-threaded system evaluation benchmark Creating table 'sbtest1'... Inserting 450000 records into 'sbtest1' Creating secondary indexes on 'sbtest1'... Creating table 'sbtest2'... ... Creating table 'sbtest250'... Inserting 450000 records into 'sbtest250' Creating secondary indexes on 'sbtest250'... - Ejecute la prueba de sysbench:
Salida:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250 \ --oltp-table-size=450000 \ --max-requests=0 \ --forced-shutdown \ --report-interval=60 \ --oltp_simple_ranges=0 \ --oltp-distinct-ranges=0 \ --oltp-sum-ranges=0 \ --oltp-order-ranges=0 \ --oltp-point-selects=0 \ --rand-type=uniform \ --max-time=600 \ --num-threads=1000 \ runsysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 20443.09, reads: 0.00, writes: 81834.16, response time: 68.24ms (95%), errors: 0.62, reconnects: 0.00 [ 120s] threads: 1000, tps: 20580.68, reads: 0.00, writes: 82324.33, response time: 70.75ms (95%), errors: 0.73, reconnects: 0.00 [ 180s] threads: 1000, tps: 20531.85, reads: 0.00, writes: 82127.21, response time: 70.63ms (95%), errors: 0.73, reconnects: 0.00 [ 240s] threads: 1000, tps: 20212.67, reads: 0.00, writes: 80861.67, response time: 71.99ms (95%), errors: 0.43, reconnects: 0.00 [ 300s] threads: 1000, tps: 19383.90, reads: 0.00, writes: 77537.87, response time: 75.64ms (95%), errors: 0.75, reconnects: 0.00 [ 360s] threads: 1000, tps: 19797.20, reads: 0.00, writes: 79190.78, response time: 75.27ms (95%), errors: 0.68, reconnects: 0.00 [ 420s] threads: 1000, tps: 20304.43, reads: 0.00, writes: 81212.87, response time: 73.82ms (95%), errors: 0.70, reconnects: 0.00 [ 480s] threads: 1000, tps: 20933.80, reads: 0.00, writes: 83737.16, response time: 74.71ms (95%), errors: 0.68, reconnects: 0.00 [ 540s] threads: 1000, tps: 20663.05, reads: 0.00, writes: 82626.42, response time: 73.56ms (95%), errors: 0.75, reconnects: 0.00 [ 600s] threads: 1000, tps: 20746.02, reads: 0.00, writes: 83015.81, response time: 73.58ms (95%), errors: 0.78, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 48868458 other: 24434022 total: 73302480 transactions: 12216804 (20359.59 per sec.) read/write requests: 48868458 (81440.43 per sec.) other operations: 24434022 (40719.87 per sec.) ignored errors: 414 (0.69 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0516s total number of events: 12216804 total time taken by event execution: 599964.4735s response time: min: 6.27ms avg: 49.11ms max: 350.24ms approx. 95 percentile: 72.90ms Threads fairness: events (avg/stddev): 12216.8040/31.27 execution time (avg/stddev): 599.9645/0.01
Métricas recopiladas
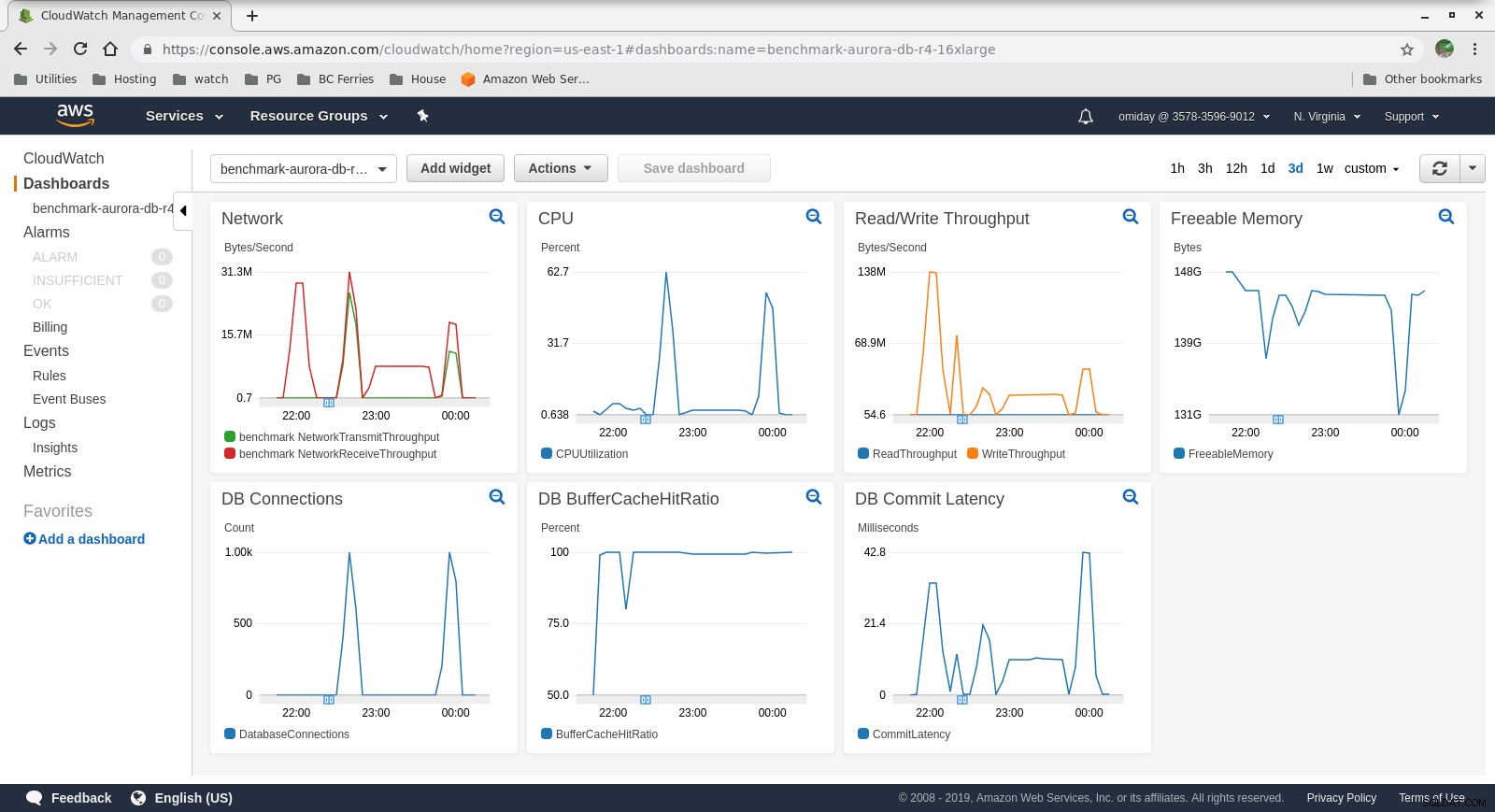 Métricas de Cloudwatch
Métricas de Cloudwatch 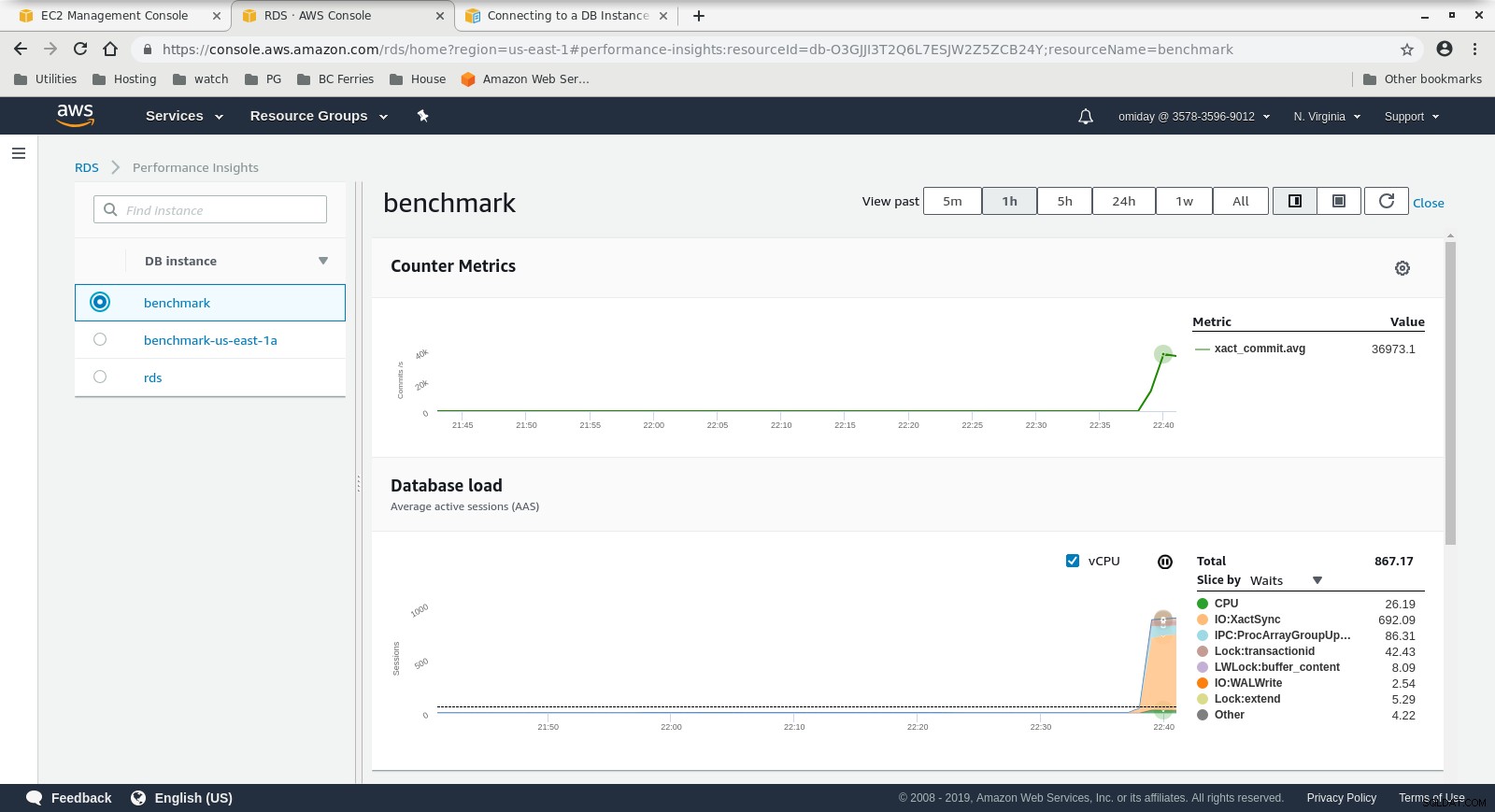 Performance Insights MetricsDescargue el documento técnico hoy Administración y automatización de PostgreSQL con ClusterControlObtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el Whitepaper
Performance Insights MetricsDescargue el documento técnico hoy Administración y automatización de PostgreSQL con ClusterControlObtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el Whitepaper Ejecución #2
Específicos
- Esta prueba utiliza las especificaciones de AWS para el cliente y un tamaño de instancia más pequeño para la base de datos:
- Equipo cliente:Instancia EC2 optimizada para memoria bajo demanda:
- vCPU:32 (16 núcleos x 2 subprocesos/núcleo)
- RAM:244 GiB
- Almacenamiento:optimizado para EBS
- Red:10 Gigabits
- Clúster de base de datos:db.r4.2xlarge:
- vCPU:8
- RAM:61 GiB
- Almacenamiento:optimizado para EBS
- Red:ancho de banda máximo de 1750 Mbps en una conexión de hasta 10 Gbps
- Equipo cliente:Instancia EC2 optimizada para memoria bajo demanda:
- La base de datos no incluía una réplica.
- El almacenamiento de la base de datos no estaba cifrado.
Realización de las pruebas y resultados
Los pasos son idénticos a la ejecución n.º 1, por lo que solo muestro el resultado:
-
Carga de trabajo de lectura/escritura de pgbench:
... 745700000 of 1000000000 tuples (74%) done (elapsed 794.93 s, remaining 271.09 s) 745800000 of 1000000000 tuples (74%) done (elapsed 795.00 s, remaining 270.97 s) 745900000 of 1000000000 tuples (74%) done (elapsed 795.09 s, remaining 270.86 s) 746000000 of 1000000000 tuples (74%) done (elapsed 795.17 s, remaining 270.74 s) 746100000 of 1000000000 tuples (74%) done (elapsed 795.24 s, remaining 270.62 s) 746200000 of 1000000000 tuples (74%) done (elapsed 795.33 s, remaining 270.51 s) ... 999800000 of 1000000000 tuples (99%) done (elapsed 1067.11 s, remaining 0.21 s) 999900000 of 1000000000 tuples (99%) done (elapsed 1067.19 s, remaining 0.11 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 1067.28 s, remaining 0.00 s) vacuum... set primary keys... total time: 4386.44 s (insert 1067.33 s, commit 0.46 s, vacuum 2088.25 s, index 1230.41 s) done.starting vacuum...end. progress: 60.0 s, 3361.3 tps, lat 286.143 ms stddev 80.417 progress: 120.0 s, 3466.8 tps, lat 288.386 ms stddev 76.373 progress: 180.0 s, 3683.1 tps, lat 271.840 ms stddev 75.712 progress: 240.0 s, 3444.3 tps, lat 289.909 ms stddev 69.564 progress: 300.0 s, 3475.8 tps, lat 287.736 ms stddev 73.712 progress: 360.0 s, 3449.5 tps, lat 289.832 ms stddev 71.878 progress: 420.0 s, 3518.1 tps, lat 284.432 ms stddev 74.276 progress: 480.0 s, 3430.7 tps, lat 291.359 ms stddev 73.264 progress: 540.0 s, 3515.7 tps, lat 284.522 ms stddev 73.206 progress: 600.0 s, 3482.9 tps, lat 287.037 ms stddev 71.649 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 2090702 latency average = 286.030 ms latency stddev = 74.245 ms tps = 3481.731730 (including connections establishing) tps = 3494.157830 (excluding connections establishing) -
prueba de banco de sistema:
sysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 4809.05, reads: 0.00, writes: 19301.02, response time: 288.03ms (95%), errors: 0.05, reconnects: 0.00 [ 120s] threads: 1000, tps: 5264.15, reads: 0.00, writes: 21005.40, response time: 255.23ms (95%), errors: 0.08, reconnects: 0.00 [ 180s] threads: 1000, tps: 5178.27, reads: 0.00, writes: 20713.07, response time: 260.40ms (95%), errors: 0.03, reconnects: 0.00 [ 240s] threads: 1000, tps: 5145.95, reads: 0.00, writes: 20610.08, response time: 255.76ms (95%), errors: 0.05, reconnects: 0.00 [ 300s] threads: 1000, tps: 5127.92, reads: 0.00, writes: 20507.98, response time: 264.24ms (95%), errors: 0.05, reconnects: 0.00 [ 360s] threads: 1000, tps: 5063.83, reads: 0.00, writes: 20278.10, response time: 268.55ms (95%), errors: 0.05, reconnects: 0.00 [ 420s] threads: 1000, tps: 5057.51, reads: 0.00, writes: 20237.28, response time: 269.19ms (95%), errors: 0.10, reconnects: 0.00 [ 480s] threads: 1000, tps: 5036.32, reads: 0.00, writes: 20139.29, response time: 279.62ms (95%), errors: 0.10, reconnects: 0.00 [ 540s] threads: 1000, tps: 5115.25, reads: 0.00, writes: 20459.05, response time: 264.64ms (95%), errors: 0.08, reconnects: 0.00 [ 600s] threads: 1000, tps: 5124.89, reads: 0.00, writes: 20510.07, response time: 265.43ms (95%), errors: 0.10, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 12225686 other: 6112822 total: 18338508 transactions: 3056390 (5093.75 per sec.) read/write requests: 12225686 (20375.20 per sec.) other operations: 6112822 (10187.57 per sec.) ignored errors: 42 (0.07 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0277s total number of events: 3056390 total time taken by event execution: 600005.2104s response time: min: 9.57ms avg: 196.31ms max: 608.70ms approx. 95 percentile: 268.71ms Threads fairness: events (avg/stddev): 3056.3900/67.44 execution time (avg/stddev): 600.0052/0.01
Métricas recopiladas
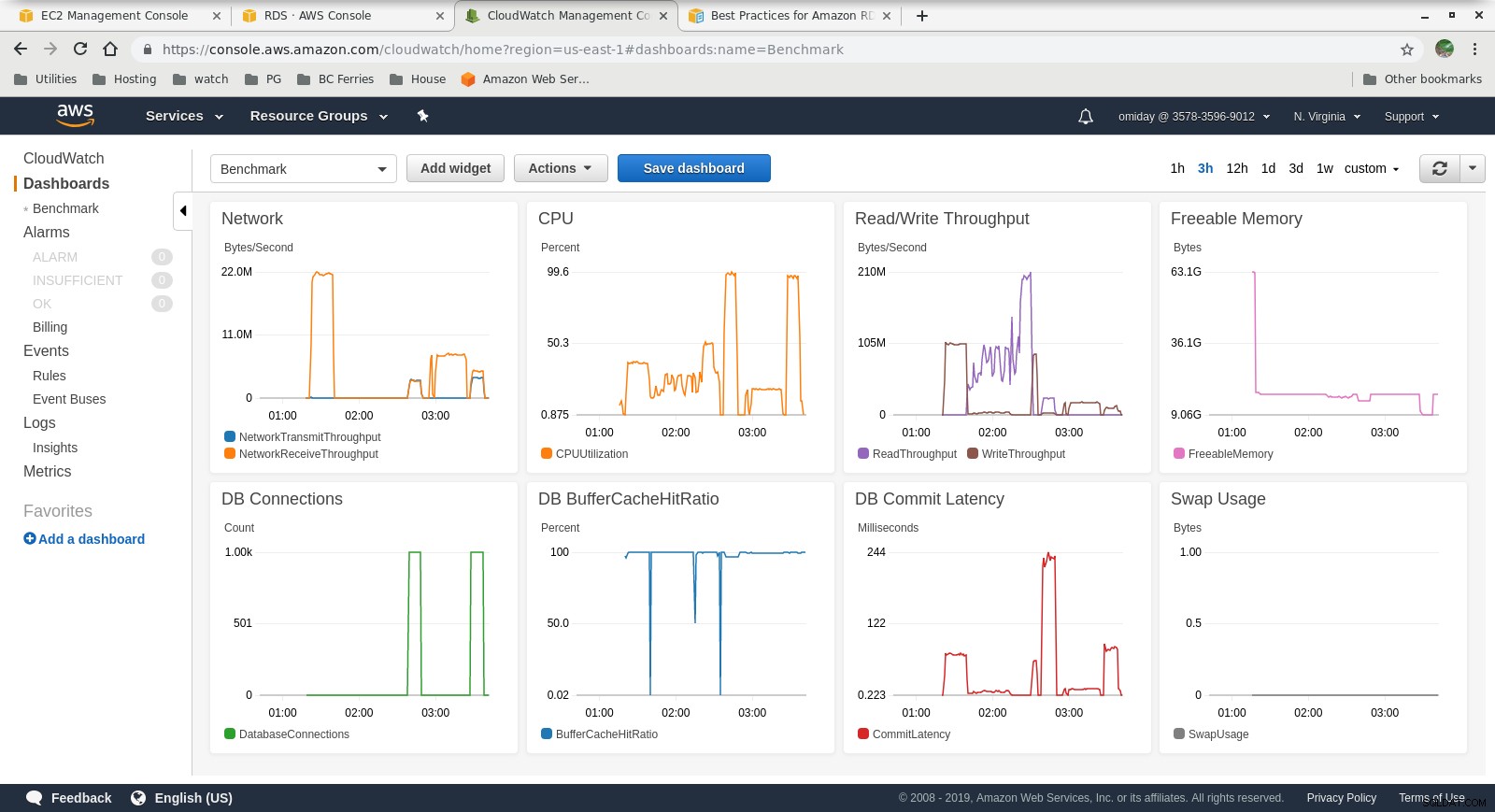 Métricas de Cloudwatch
Métricas de Cloudwatch 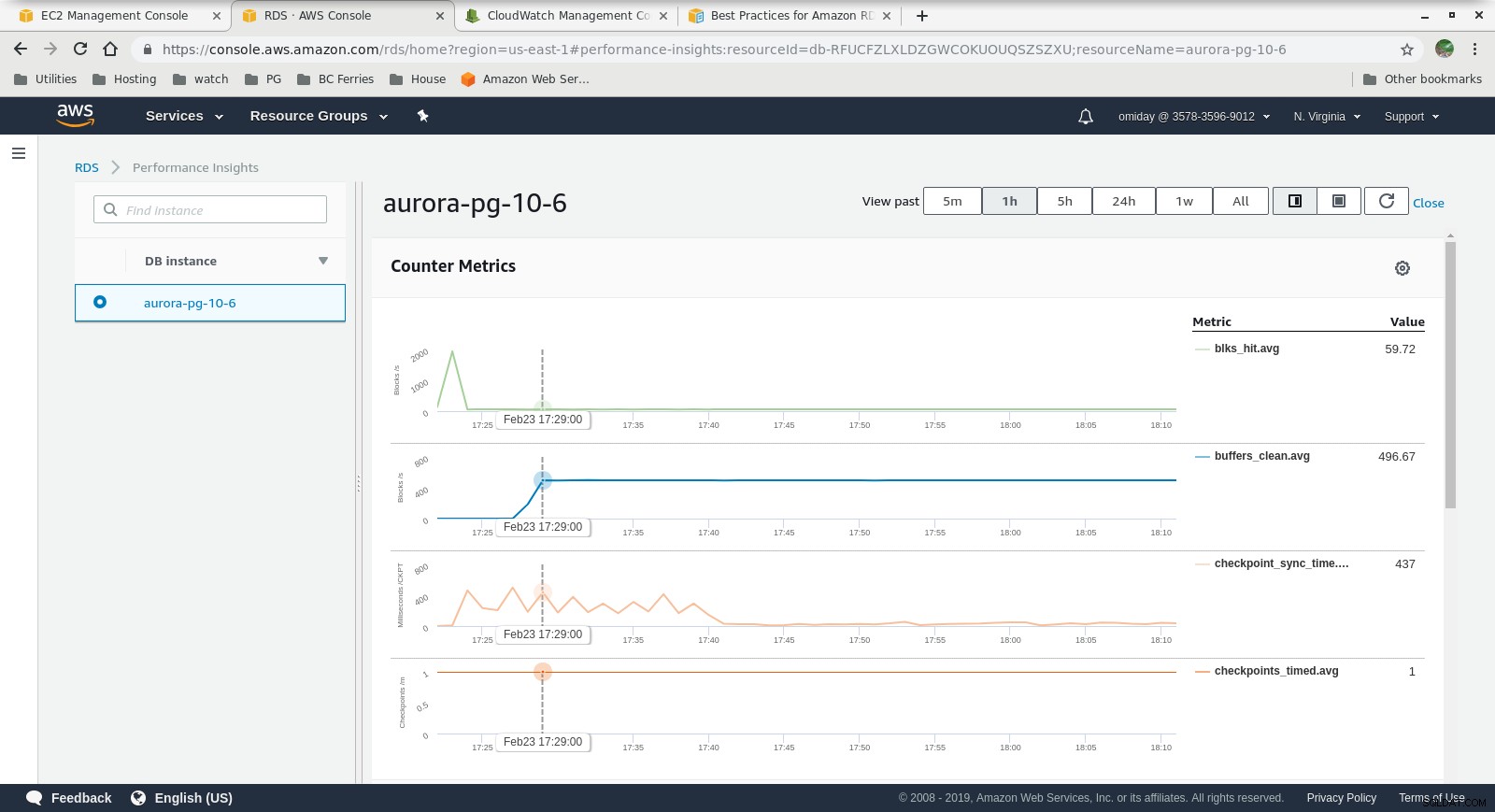 Perspectivas de rendimiento:métricas de contador
Perspectivas de rendimiento:métricas de contador 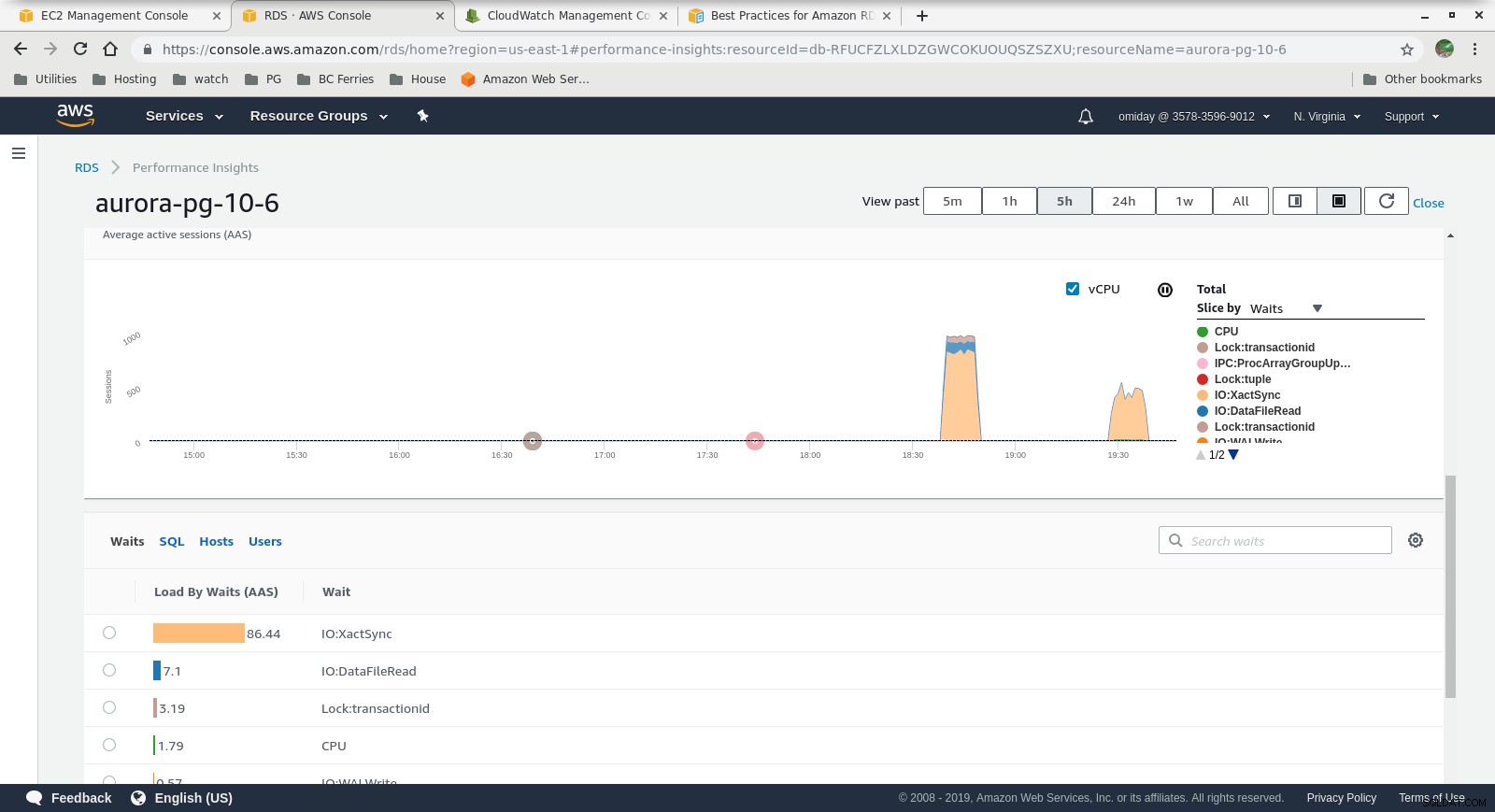 Perspectivas de rendimiento:carga de base de datos por esperas
Perspectivas de rendimiento:carga de base de datos por esperas Reflexiones finales
- Los usuarios están limitados a usar tamaños de instancia predefinidos. Como desventaja, si el punto de referencia muestra que la instancia puede beneficiarse de la memoria adicional, no es posible "simplemente agregar más RAM". Agregar más memoria se traduce en aumentar el tamaño de la instancia, lo que conlleva un costo mayor (el costo se duplica por cada tamaño de instancia).
- El motor de almacenamiento de Amazon Aurora es muy diferente de RDS y está construido sobre hardware SAN. Las métricas de rendimiento de E/S por instancia muestran que la prueba no se acercó ni siquiera al máximo para los volúmenes EBS SSD de IOPS aprovisionados de 1750 MiB/s.
- Se pueden realizar ajustes adicionales revisando los eventos de AWS PostgreSQL incluidos en los gráficos de Performance Insights.
Siguiente en serie
Estén atentos a la siguiente parte:Amazon RDS para PostgreSQL 10.6.