Introducción
Independientemente de la tecnología de la base de datos, es necesario contar con una configuración de monitorización, tanto para detectar problemas y tomar medidas, como simplemente para conocer el estado actual de nuestros sistemas.
Para ello existen varias herramientas, de pago y gratuitas. En este blog nos centraremos en uno en particular:Nagios Core.
¿Qué es el núcleo de Nagios?
Nagios Core es un sistema de código abierto para monitorear hosts, redes y servicios. Permite configurar alertas y dispone de diferentes estados para las mismas. Permite la implementación de complementos, desarrollados por la comunidad, o incluso nos permite configurar nuestros propios scripts de monitoreo.
¿Cómo instalar Nagios?
La documentación oficial nos muestra cómo instalar Nagios Core en sistemas CentOS o Ubuntu.
Veamos un ejemplo de los pasos necesarios para la instalación en CentOS 7.
Paquetes requeridos
[[email protected] ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzipDescargar Nagios Core, complementos de Nagios y NRPE
[[email protected] ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz
[[email protected] ~]# wget http://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[[email protected] ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gzAgregar usuario y grupo de Nagios
[[email protected] ~]# useradd nagios
[[email protected] ~]# groupadd nagcmd
[[email protected] ~]# usermod -a -G nagcmd nagios
[[email protected] ~]# usermod -a -G nagios,nagcmd apacheInstalación de Nagios
[[email protected] ~]# tar zxvf nagios-4.4.2.tar.gz
[[email protected] ~]# cd nagios-4.4.2
[[email protected] nagios-4.4.2]# ./configure --with-command-group=nagcmd
[[email protected] nagios-4.4.2]# make all
[[email protected] nagios-4.4.2]# make install
[[email protected] nagios-4.4.2]# make install-init
[[email protected] nagios-4.4.2]# make install-config
[[email protected] nagios-4.4.2]# make install-commandmode
[[email protected] nagios-4.4.2]# make install-webconf
[[email protected] nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
[[email protected] nagios-4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
[[email protected] nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgInstalación del complemento Nagios y NRPE
[[email protected] ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[[email protected] ~]# cd nagios-plugins-2.2.1
[[email protected] nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[[email protected] nagios-plugins-2.2.1]# make
[[email protected] nagios-plugins-2.2.1]# make install
[[email protected] ~]# yum install epel-release
[[email protected] ~]# yum install nagios-plugins-nrpe
[[email protected] ~]# tar zxvf nrpe-3.2.1.tar.gz
[[email protected] ~]# cd nrpe-3.2.1
[[email protected] nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[[email protected] nrpe-3.2.1]# make all
[[email protected] nrpe-3.2.1]# make install-pluginAgregamos la siguiente línea al final de nuestro archivo /usr/local/nagios/etc/objects/command.cfg para usar NRPE al verificar nuestros servidores:
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}Comienza Nagios
[[email protected] nagios-4.4.2]# systemctl start nagios
[[email protected] nagios-4.4.2]# systemctl start httpdAcceso web
Creamos el usuario para acceder a la interfaz web y ya podemos entrar al sitio.
[[email protected] nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminhttp://Dirección_IP/nagios/
 Acceso web de Nagios
Acceso web de Nagios ¿Cómo configurar Nagios?
Ahora que tenemos instalado nuestro Nagios, podemos continuar con la configuración. Para ello debemos ir a la ubicación correspondiente a nuestra instalación, en nuestro ejemplo /usr/local/nagios/etc.
Hay varios archivos de configuración diferentes que necesitará crear o editar antes de comenzar a monitorear cualquier cosa.
[[email protected] etc]# ls /usr/local/nagios/etc
cgi.cfg htpasswd.users nagios.cfg objects resource.cfg- cgi.cfg: El archivo de configuración de CGI contiene una serie de directivas que afectan el funcionamiento de los CGI. También contiene una referencia al archivo de configuración principal, por lo que los CGI saben cómo configuró Nagios y dónde se almacenan las definiciones de sus objetos.
- htpasswd.usuarios: Este archivo contiene los usuarios creados para acceder a la interfaz web de Nagios.
- nagios.cfg: El archivo de configuración principal contiene una serie de directivas que afectan el funcionamiento del demonio de Nagios Core.
- objetos: Cuando instala Nagios, aquí se colocan varios archivos de configuración de objetos de muestra. Puede usar estos archivos de muestra para ver cómo funciona la herencia de objetos y aprender a definir sus propias definiciones de objetos. Los objetos son todos los elementos que intervienen en la lógica de seguimiento y notificación.
- recurso.cfg: Esto se usa para especificar un archivo de recursos opcional que puede contener definiciones de macros. Las macros le permiten hacer referencia a la información de hosts, servicios y otras fuentes en sus comandos.
Dentro de los objetos, podemos encontrar plantillas, que se pueden utilizar al crear nuevos objetos. Por ejemplo, podemos ver que en nuestro archivo /usr/local/nagios/etc/objects/templates.cfg, hay una plantilla llamada linux-server, que se usará para agregar nuestros servidores.
define host {
name linux-server ; The name of this host template
use generic-host ; This template inherits other values from the generic-host template
check_period 24x7 ; By default, Linux hosts are checked round the clock
check_interval 5 ; Actively check the host every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each Linux host 10 times (max)
check_command check-host-alive ; Default command to check Linux hosts
notification_period workhours ; Linux admins hate to be woken up, so we only notify during the day
; Note that the notification_period variable is being overridden from
; the value that is inherited from the generic-host template!
notification_interval 120 ; Resend notifications every 2 hours
notification_options d,u,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}Usando esta plantilla, nuestros hosts heredarán la configuración sin tener que especificarlos uno por uno en cada servidor que agreguemos.
También tenemos comandos, contactos y períodos de tiempo predefinidos.
Los comandos los utilizará Nagios para sus comprobaciones, y eso es lo que añadimos dentro del archivo de configuración de cada servidor para monitorizarlo. Por ejemplo, PING:
define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}Tenemos la posibilidad de crear contactos o grupos, y especificar qué alertas quiero que llegue a qué persona o grupo.
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email [email protected] ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}Para nuestras consultas y alertas, podemos configurar en qué horas y días queremos recibirlas. Si tenemos un servicio que no es crítico, probablemente no queramos despertarnos de madrugada, por lo que sería bueno alertar solo en horario laboral para evitarlo.
define timeperiod {
name workhours
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}Veamos ahora cómo agregar alertas a nuestros Nagios.
Vamos a monitorear nuestros servidores PostgreSQL, por lo que primero los agregaremos como hosts en nuestro directorio de objetos. Crearemos 3 nuevos archivos:
[[email protected] ~]# cd /usr/local/nagios/etc/objects/
[[email protected] objects]# vi postgres1.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres1 ; Hostname
alias PostgreSQL1 ; Alias
address 192.168.100.123 ; IP Address
}
[[email protected] objects]# vi postgres2.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres2 ; Hostname
alias PostgreSQL2 ; Alias
address 192.168.100.124 ; IP Address
}
[[email protected] objects]# vi postgres3.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres3 ; Hostname
alias PostgreSQL3 ; Alias
address 192.168.100.125 ; IP Address
}Luego debemos agregarlos al archivo nagios.cfg y aquí tenemos 2 opciones.
Agregue nuestros hosts (archivos cfg) uno por uno usando la variable cfg_file (opción por defecto) o agregue todos los archivos cfg que tenemos dentro de un directorio usando la variable cfg_dir.
Agregaremos los archivos uno por uno siguiendo la estrategia por defecto.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres2.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres3.cfgCon esto tenemos nuestros hosts monitoreados. Ahora solo tenemos que añadir qué servicios queremos monitorizar. Para ello utilizaremos unas comprobaciones ya definidas (check_ssh y check_ping), y añadiremos algunas comprobaciones básicas del sistema operativo como carga y espacio en disco, entre otras, utilizando NRPE.
Descargue el documento técnico hoy Administración y automatización de PostgreSQL con ClusterControlObtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnico¿Qué es NRPE?
Ejecutor remoto de complementos de Nagios. Esta herramienta nos permite ejecutar complementos de Nagios en un host remoto de la manera más transparente posible.
Para poder utilizarlo debemos instalar el servidor en cada nodo que queramos monitorizar, y nuestro Nagios se conectará como cliente a cada uno de ellos, ejecutando el(los) plugin(s) correspondiente(s).
¿Cómo instalar NRPE?
[[email protected] ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz
[[email protected] ~]# wget http://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[[email protected] ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[[email protected] ~]# tar zxvf nrpe-3.2.1.tar.gz
[[email protected] ~]# cd nrpe-3.2.1
[[email protected] nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[[email protected] nrpe-3.2.1]# make all
[[email protected] nrpe-3.2.1]# make install-groups-users
[[email protected] nrpe-3.2.1]# make install
[[email protected] nrpe-3.2.1]# make install-config
[[email protected] nrpe-3.2.1]# make install-init
[[email protected] ~]# cd nagios-plugins-2.2.1
[[email protected] nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[[email protected] nagios-plugins-2.2.1]# make
[[email protected] nagios-plugins-2.2.1]# make install
[[email protected] nagios-plugins-2.2.1]# systemctl enable nrpeLuego editamos el archivo de configuración /usr/local/nagios/etc/nrpe.cfg
server_address=<Local IP Address>
allowed_hosts=127.0.0.1,<Nagios Server IP Address>Y reiniciamos el servicio NRPE:
[[email protected] ~]# systemctl restart nrpePodemos probar la conexión ejecutando lo siguiente desde nuestro servidor Nagios:
[[email protected] ~]# /usr/local/nagios/libexec/check_nrpe -H <Node IP Address>
NRPE v3.2.1¿Cómo monitorear PostgreSQL?
Al monitorear PostgreSQL, hay dos áreas principales a tener en cuenta:el sistema operativo y las bases de datos.
Para el sistema operativo, NRPE tiene configuradas algunas comprobaciones básicas como espacio en disco y carga, entre otras. Estos controles se pueden habilitar muy fácilmente de la siguiente manera.
En nuestros nodos editamos el archivo /usr/local/nagios/etc/nrpe.cfg y vamos a donde están las siguientes líneas:
command[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /
command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200Los nombres entre corchetes son los que usaremos en nuestro servidor Nagios para habilitar estas comprobaciones.
En nuestro Nagios, editamos los archivos de los 3 nodos:
/usr/local/nagios/etc/objects/postgres1.cfg
/usr/local/nagios/etc/objects/postgres2.cfg
/usr/local/nagios/etc/objects/postgres3.cfgAgregamos estos cheques que vimos anteriormente, dejando nuestros archivos de la siguiente manera:
define host {
use linux-server
host_name postgres1
alias PostgreSQL1
address 192.168.100.123
}
define service {
use generic-service
host_name postgres1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name postgres1
service_description SSH
check_command check_ssh
}
define service {
use generic-service
host_name postgres1
service_description Root Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name postgres1
service_description Total Processes zombie
check_command check_nrpe!check_zombie_procs
}
define service {
use generic-service
host_name postgres1
service_description Total Processes
check_command check_nrpe!check_total_procs
}
define service {
use generic-service
host_name postgres1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name postgres1
service_description Current Users
check_command check_nrpe!check_users
}Y reiniciamos el servicio de nagios:
[[email protected] ~]# systemctl start nagiosEn este punto, si vamos a la sección de servicios en la interfaz web de nuestro Nagios, deberíamos tener algo como lo siguiente:
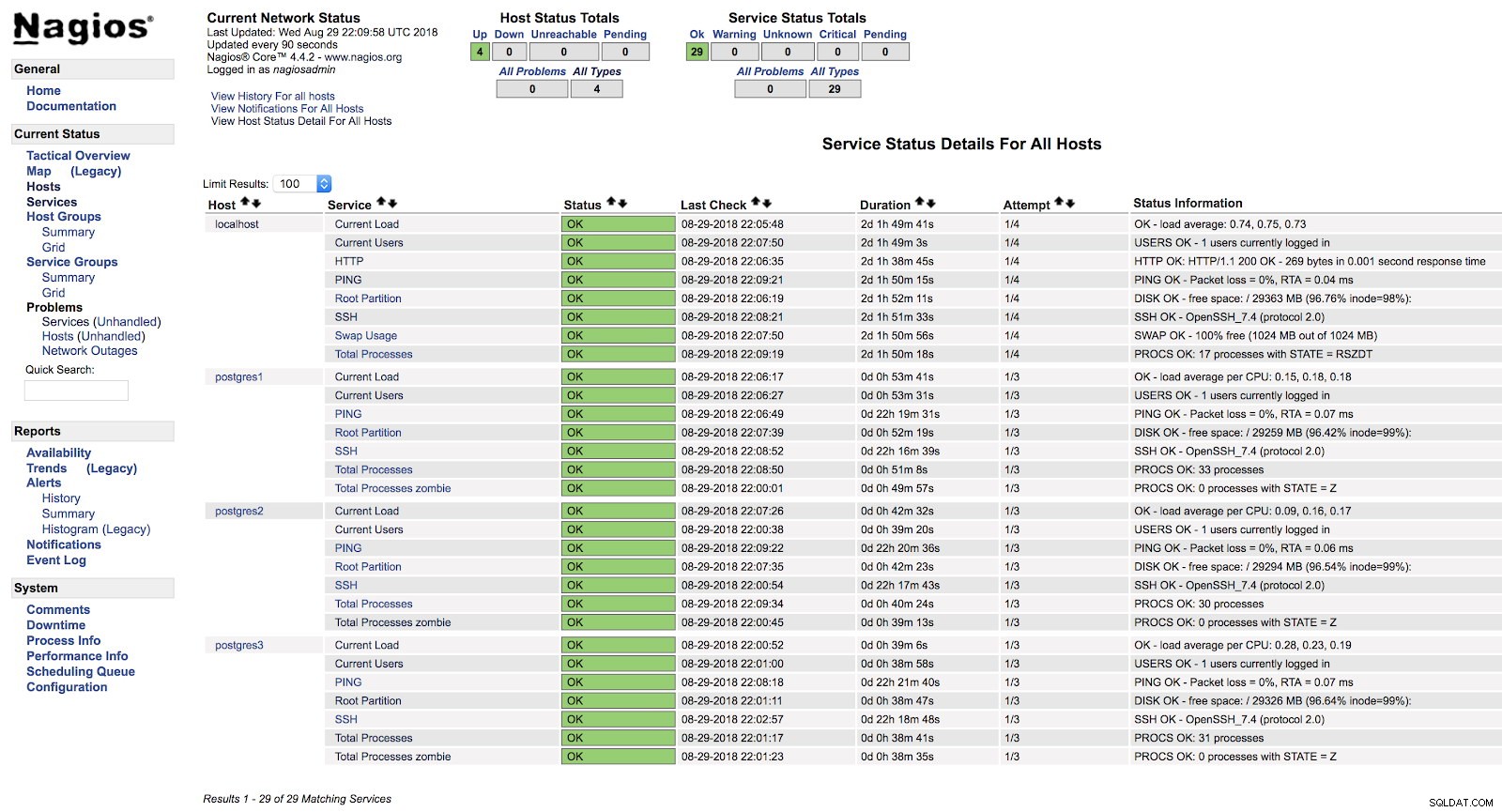 Alertas de host de Nagios
Alertas de host de Nagios De esta forma estaremos cubriendo las comprobaciones básicas de nuestro servidor a nivel de sistema operativo.
Tenemos muchos más cheques que podemos agregar e incluso podemos crear nuestros propios cheques (veremos un ejemplo más adelante).
Ahora veamos cómo monitorear nuestro motor de base de datos PostgreSQL usando dos de los principales complementos diseñados para esta tarea.
Comprobar_postgres
Uno de los complementos más populares para comprobar PostgreSQL es check_postgres de Bucardo.
Veamos cómo instalarlo y cómo usarlo con nuestra base de datos PostgreSQL.
Paquetes requeridos
[[email protected] ~]# yum install perl-develInstalación
[[email protected] ~]# wget http://bucardo.org/downloads/check_postgres.tar.gz
[[email protected] ~]# tar zxvf check_postgres.tar.gz
[[email protected] ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/
[[email protected] ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl
[[email protected] ~]# cd /usr/local/nagios/libexec/
[[email protected] libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinksEste último comando crea los enlaces para utilizar todas las funciones de esta comprobación, como check_postgres_connection, check_postgres_last_vacuum o check_postgres_replication_slots entre otras.
[[email protected] libexec]# ls |grep postgres
check_postgres.pl
check_postgres_archive_ready
check_postgres_autovac_freeze
check_postgres_backends
check_postgres_bloat
check_postgres_checkpoint
check_postgres_cluster_id
check_postgres_commitratio
check_postgres_connection
check_postgres_custom_query
check_postgres_database_size
check_postgres_dbstats
check_postgres_disabled_triggers
check_postgres_disk_space
…Añadimos en nuestro archivo de configuración de NRPE (/usr/local/nagios/etc/nrpe.cfg) la línea para ejecutar la comprobación que queremos utilizar:
command[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3
command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c='200 M'
command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgres
command[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 -c=100En nuestro ejemplo, agregamos 4 comprobaciones básicas para PostgreSQL. Supervisaremos los bloqueos, la hinchazón, la conexión y los backends.
En el archivo correspondiente a nuestra base de datos en el servidor de Nagios (/usr/local/nagios/etc/objects/postgres1.cfg), añadimos las siguientes entradas:
define service {
use generic-service
host_name postgres1
service_description PostgreSQL locks
check_command check_nrpe!check_postgres_locks
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Bloat
check_command check_nrpe!check_postgres_bloat
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Connection
check_command check_nrpe!check_postgres_connection
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Backends
check_command check_nrpe!check_postgres_backends
}Y tras reiniciar ambos servicios (NRPE y Nagios) en ambos servidores, podemos ver configuradas nuestras alertas.
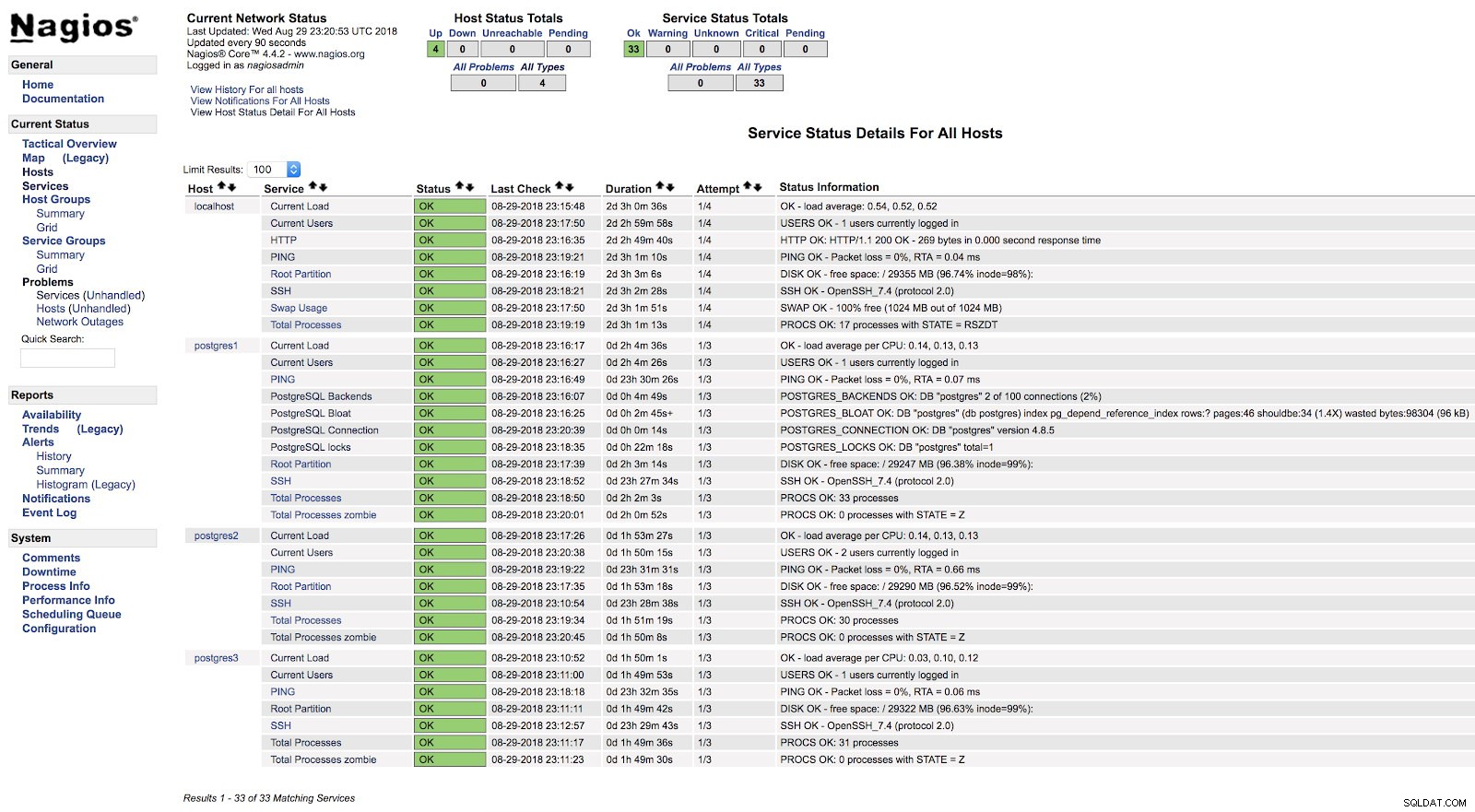 Nagios check_postgres Alertas
Nagios check_postgres Alertas En la documentación oficial del complemento check_postgres, puede encontrar información sobre qué más monitorear y cómo hacerlo.
Comprobar_pgactividad
Ahora es el turno de check_pgactivity, también popular para monitorear nuestra base de datos PostgreSQL.
Instalación
[[email protected] ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz
[[email protected] ~]# tar zxvf check_pgactivity-2.3.tgz
[[email protected] ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity
[[email protected] ~]# chown nagios.nagios /usr/local/nagios/libexec/check_pgactivityAñadimos en nuestro archivo de configuración de NRPE (/usr/local/nagios/etc/nrpe.cfg) la línea para ejecutar la comprobación que queremos utilizar:
command[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100
command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connection
command[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexes
command[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 -c 10En nuestro ejemplo, agregaremos 4 comprobaciones básicas para PostgreSQL. Supervisaremos los backends, la conexión, los índices no válidos y los bloqueos.
En el archivo correspondiente a nuestra base de datos en el servidor de Nagios (/usr/local/nagios/etc/objects/postgres2.cfg), añadimos las siguientes entradas:
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Backends
check_command check_nrpe!check_pgactivity_backends
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Connection
check_command check_nrpe!check_pgactivity_connection
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Indexes
check_command check_nrpe!check_pgactivity_indexes
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Locks
check_command check_nrpe!check_pgactivity_locks
}Y tras reiniciar ambos servicios (NRPE y Nagios) en ambos servidores, podemos ver configuradas nuestras alertas.
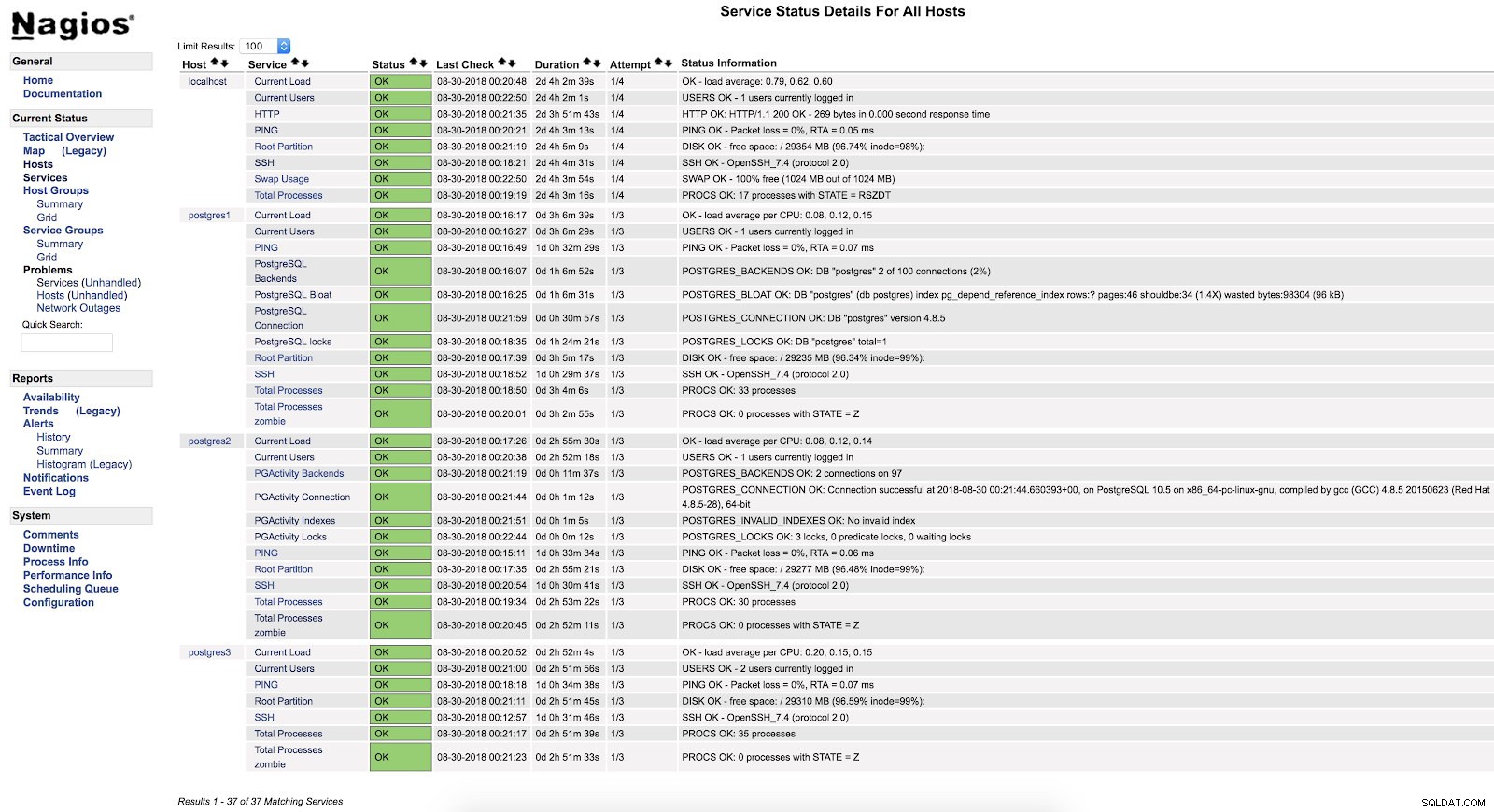 Alertas de actividad check_pg de Nagios
Alertas de actividad check_pg de Nagios Comprobar registro de errores
Una de las comprobaciones más importantes, o la más importante, es comprobar nuestro registro de errores.
Aquí podemos encontrar diferentes tipos de errores como FATAL o deadlock, y es un buen punto de partida para analizar cualquier problema que tengamos en nuestra base de datos.
Para verificar nuestro registro de errores, crearemos nuestro propio script de monitoreo y lo integraremos en nuestro Nagios (esto es solo un ejemplo, este script será básico y tiene mucho margen de mejora).
Guión
Crearemos el archivo /usr/local/nagios/libexec/check_postgres_log.sh en nuestro servidor PostgreSQL3.
[[email protected] ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh
#!/bin/bash
#Variables
LOG="/var/log/postgresql-$(date +%a).log"
CURRENT_DATE=$(date +'%Y-%m-%d %H')
ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)
#States
STATE_CRITICAL=2
STATE_OK=0
#Check
if [ $ERROR -ne 0 ]; then
echo "CRITICAL - Check PostgreSQL Log File - $ERROR Error Found"
exit $STATE_CRITICAL
else
echo "OK - PostgreSQL without errors"
exit $STATE_OK
fiLo importante del script es crear correctamente las salidas correspondientes a cada estado. Estas salidas son leídas por Nagios y cada número corresponde a un estado:
0=OK
1=WARNING
2=CRITICAL
3=UNKNOWNEn nuestro ejemplo solo utilizaremos 2 estados, OK y CRITICAL, ya que solo nos interesa saber si hay errores de tipo FATAL en nuestro log de errores en la hora actual.
El texto que usamos antes de nuestra salida se mostrará en la interfaz web de nuestro Nagios, por lo que debe ser lo más claro posible para usar esto como una guía para el problema.
Una vez hayamos terminado nuestro script de monitorización procederemos a darle permisos de ejecución, asignarlo al usuario nagios y añadirlo a nuestro servidor de base de datos NRPE así como a nuestro Nagios:
[[email protected] ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh
[[email protected] ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres_log.sh
[[email protected] ~]# vi /usr/local/nagios/etc/nrpe.cfg
command[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh
[[email protected] ~]# vi /usr/local/nagios/etc/objects/postgres3.cfg
define service {
use generic-service ; Name of service template to use
host_name postgres3
service_description PostgreSQL LOG
check_command check_nrpe!check_postgres_log
}Reinicie NRPE y Nagios. Luego podemos ver nuestro cheque en la interfaz de Nagios:
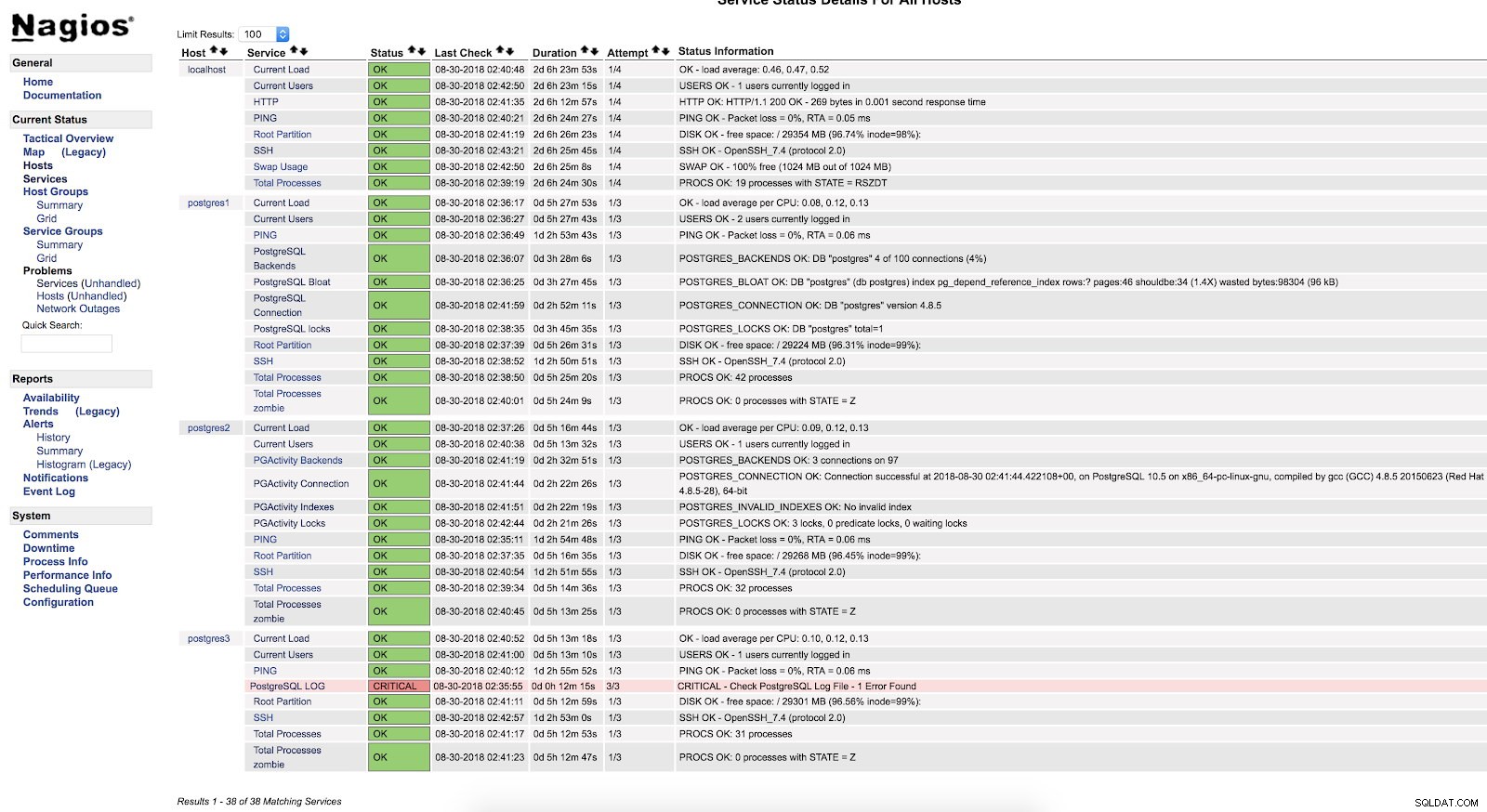 Alertas de secuencias de comandos de Nagios
Alertas de secuencias de comandos de Nagios Como podemos ver se encuentra en un estado CRÍTICO, por lo que si vamos al log, podemos ver lo siguiente:
2018-08-30 02:29:49.531 UTC [22162] FATAL: Peer authentication failed for user "postgres"
2018-08-30 02:29:49.531 UTC [22162] DETAIL: Connection matched pg_hba.conf line 83: "local all all peer"Para obtener más información sobre lo que podemos monitorear en nuestra base de datos de PostgreSQL, le recomiendo que consulte nuestros blogs de rendimiento y monitoreo o este seminario web de rendimiento de Postgres.
Seguridad y rendimiento
Al configurar cualquier monitoreo, ya sea usando complementos o nuestro propio script, debemos tener mucho cuidado con 2 cosas muy importantes:seguridad y rendimiento.
Cuando asignamos los permisos necesarios para la monitorización, debemos ser lo más restrictivos posible, limitando el acceso solo de forma local o desde nuestro servidor de monitorización, utilizando claves seguras, encriptando el tráfico, permitiendo la conexión al mínimo necesario para que la monitorización funcione.
Con respecto al rendimiento, el monitoreo es necesario, pero también es necesario usarlo de manera segura para nuestros sistemas.
Debemos tener cuidado de no generar un acceso al disco excesivamente alto o ejecutar consultas que afecten negativamente el rendimiento de nuestra base de datos.
Si tenemos muchas transacciones por segundo generando gigas de logs, y seguimos buscando errores continuamente, probablemente no sea lo mejor para nuestra base de datos. Por lo tanto, debemos mantener un equilibrio entre lo que monitoreamos, con qué frecuencia y el impacto en el rendimiento.
Conclusión
Hay múltiples formas de implementar el monitoreo o configurarlo. Podemos llegar a hacerlo tan complejo o tan simple como queramos. El objetivo de este blog fue introducirte en el monitoreo de PostgreSQL utilizando una de las herramientas de código abierto más utilizadas. También hemos visto que la configuración es muy flexible y se puede adaptar a diferentes necesidades.
Y no olvides que siempre podemos confiar en la comunidad, por eso te dejo algunos enlaces que pueden ser de gran ayuda.
Foro de soporte:https://support.nagios.com/forum/
Problemas conocidos:https://github.com/NagiosEnterprises/nagioscore/issues
Complementos de Nagios:https://exchange.nagios.org/directory/Plugins
Complemento de Nagios para ClusterControl:https://severalnines.com/blog/nagios-plugin-clustercontrol