La gestión de la memoria en PostgreSQL es importante para mejorar el rendimiento del servidor de la base de datos. El archivo de configuración de PostgreSQL (postgres.conf) administra la configuración del servidor de la base de datos. Utiliza valores predeterminados de los parámetros, pero podemos cambiar estos valores para reflejar mejor la carga de trabajo y el entorno operativo.
En este blog, cubriremos estos parámetros relacionados con la memoria. Pero antes de comenzar, echemos un vistazo a la arquitectura de memoria en PostgreSQL.
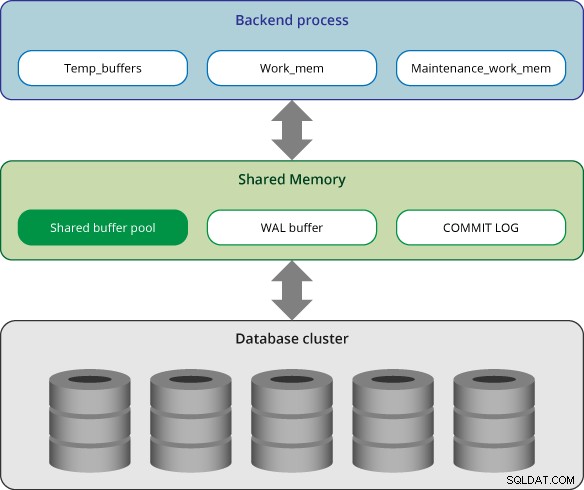
Arquitectura de memoria
La memoria en PostgreSQL se puede clasificar en dos categorías:
- Área de memoria local:es asignada por cada proceso de back-end para su propio uso.
- Área de memoria compartida:Es utilizada por todos los procesos de un servidor PostgreSQL.
Área de memoria local
En PostgreSQL, cada proceso de back-end asigna memoria local para el procesamiento de consultas; cada área se divide en subáreas cuyos tamaños son fijos o variables.
Las subáreas son las siguientes.
Mem_trabajo
El ejecutor usa esta área para ordenar tuplas por operaciones ORDER BY y DISTINCT. También lo usa para unir tablas mediante operaciones de fusión y combinación.
Mantenimiento_trabajo_mem
Este parámetro se utiliza para algunos tipos de operaciones de mantenimiento (VACUUM, REINDEX).
Temp_buffers
El ejecutor usa esta área para almacenar tablas temporales.
Área de memoria compartida
El servidor PostgreSQL asigna el área de memoria compartida cuando se inicia. Esta área se divide en varias subáreas de tamaño fijo.
Grupo de búfer compartido
PostgreSQL carga páginas dentro de tablas e índices desde el almacenamiento persistente a un grupo de búfer compartido y luego opera en ellos directamente.
Búfer WAL
PostgreSQL admite el mecanismo WAL (registro de escritura anticipada) para garantizar que no se pierdan datos después de una falla del servidor. Los datos WAL son realmente un registro de transacciones en PostgreSQL y el búfer WAL es un área de almacenamiento en búfer de los datos WAL antes de escribirlos en un almacenamiento persistente.
Registro de confirmación
El registro de compromiso (CLOG) mantiene los estados de todas las transacciones y es parte del mecanismo de control de concurrencia. El registro de confirmación se asigna a la memoria compartida y se usa durante el procesamiento de transacciones.
PostgreSQL define los siguientes cuatro estados de transacción.
- EN_PROGRESO
- COMPROMETIDO
- ABORTADO
- SUBCOMPROMETIDO
Ajuste de los parámetros de memoria de PostgreSQL
Hay algunos parámetros importantes que se recomiendan para la gestión de memoria en PostgreSQL. Debes tener en cuenta lo siguiente.
Búferes_compartidos
Este parámetro designa la cantidad de memoria utilizada para los búferes de memoria compartida. El parámetro shared_buffers determina cuánta memoria se dedica al servidor para almacenar datos en caché. El valor predeterminado de shared_buffers suele ser de 128 megabytes (128 MB).
El valor predeterminado de este parámetro es muy bajo porque en algunas plataformas, como las versiones anteriores de Solaris y SGI, tener valores grandes requiere una acción invasiva como volver a compilar el kernel. Incluso en los sistemas Linux modernos, es probable que el kernel no permita configurar shared_buffers a más de 32 MB sin ajustar primero la configuración del kernel.
El mecanismo ha cambiado en PostgreSQL 9.4 y versiones posteriores, por lo que no será necesario ajustar la configuración del kernel allí.
Si hay mucha carga en el servidor de la base de datos, establecer un valor alto mejorará el rendimiento.
Si tiene un servidor de base de datos dedicado con 1 GB o más de RAM, un valor inicial razonable para el parámetro de configuración shared_buffer es el 25 % de la memoria de su sistema.
Valor predeterminado de shared_buffers =128 MB. El cambio requiere reiniciar el servidor PostgreSQL.
La recomendación general para configurar shared_buffers es la siguiente.
- Por debajo de 2 GB de memoria, establezca el valor de shared_buffers en el 20 % de la memoria total del sistema.
- Por debajo de 32 GB de memoria, establezca el valor de shared_buffers en el 25 % de la memoria total del sistema.
- Por encima de 32 GB de memoria, establezca el valor de shared_buffers en 8 GB
Mem_trabajo
Este parámetro especifica la cantidad de memoria que utilizarán las operaciones de clasificación interna y las tablas hash antes de escribir en archivos de disco temporales. Si están ocurriendo muchas ordenaciones complejas y tiene suficiente memoria, entonces aumentar el parámetro work_mem le permite a PostgreSQL hacer ordenaciones en memoria más grandes que serán más rápidas que los equivalentes basados en disco.
Tenga en cuenta que para una consulta compleja, es posible que se ejecuten en paralelo muchas operaciones de clasificación o hash. Cada operación podrá usar tanta memoria como este valor especifique antes de comenzar a escribir datos en los archivos temporales. Existe la posibilidad de que varias sesiones puedan estar realizando este tipo de operaciones al mismo tiempo. Por lo tanto, la memoria total utilizada podría ser muchas veces el valor del parámetro work_mem.
Recuerde eso al elegir el valor correcto. Las operaciones de clasificación se utilizan para ORDER BY, DISTINCT y fusiones. Las tablas hash se utilizan en combinaciones hash, procesamiento basado en hash de subconsultas IN y agregación basada en hash.
El parámetro log_temp_files se puede usar para registrar clasificaciones, hashes y archivos temporales que pueden ser útiles para determinar si las clasificaciones se están derramando en el disco en lugar de caber en la memoria. Puede verificar los tipos que se derraman en el disco usando los planes EXPLAIN ANALYZE. Por ejemplo, en el resultado de EXPLAIN ANALYZE, si ve una línea como:“Método de clasificación:combinación externa de disco:7528kB ”, un work_mem de al menos 8 MB mantendría los datos intermedios en la memoria y mejoraría el tiempo de respuesta de las consultas.
El valor predeterminado de work_mem =4 MB.
La recomendación general para configurar work_mem es la siguiente.
- Comience con un valor bajo:32-64 MB
- Luego busque las líneas de "archivo temporal" en los registros
- Establecido en 2 o 3 veces el archivo temporal más grande
mantenimiento _work_mem
Este parámetro especifica la cantidad máxima de memoria utilizada por operaciones de mantenimiento como VACUUM, CREATE INDEX y ALTER TABLE ADD FOREIGN KEY. Dado que una sesión de base de datos solo puede ejecutar una de estas operaciones a la vez y una instalación de PostgreSQL no tiene muchas de ellas ejecutándose simultáneamente, es seguro establecer el valor de maintenance_work_mem significativamente mayor que work_mem.
Establecer el valor más grande podría mejorar el rendimiento para aspirar y restaurar volcados de bases de datos.
Es necesario recordar que cuando se ejecuta autovacuum, se puede asignar hasta autovacuum_max_workers veces esta memoria, así que tenga cuidado de no establecer un valor predeterminado demasiado alto.
El valor predeterminado de maintenance_work_mem =64 MB.
La recomendación general para establecer maintenance_work_mem es la siguiente.
- Establezca el valor 10 % de la memoria del sistema, hasta 1 GB
- Tal vez puedas configurarlo aún más alto si tienes problemas de VACUUM
Tamaño_caché_efectivo
El tamaño_caché_efectivo debe establecerse en una estimación de cuánta memoria está disponible para el almacenamiento en caché del disco por parte del sistema operativo y dentro de la propia base de datos. Esta es una guía sobre la cantidad de memoria que espera que esté disponible en el sistema operativo y las cachés de búfer de PostgreSQL, no una asignación.
El planificador de consultas de PostgreSQL usa este valor para averiguar si los planes que está considerando caben en la memoria RAM o no. Si se establece demasiado bajo, es posible que los índices no se utilicen para ejecutar consultas de la forma esperada. Como la mayoría de los sistemas Unix son bastante agresivos con el almacenamiento en caché, al menos el 50 % de la RAM disponible en un servidor de base de datos dedicado estará lleno de datos en caché.
La recomendación general para tamaño_caché_efectivo es la siguiente.
- Establezca el valor en la cantidad de caché del sistema de archivos disponible
- Si no lo sabe, establezca el valor en el 50 % de la memoria total del sistema
El valor predeterminado de tamaño_caché_efectivo =4 GB.
Temp_buffers
Este parámetro establece el número máximo de búferes temporales utilizados por cada sesión de base de datos. Los búferes locales de sesión se utilizan solo para acceder a las tablas temporales. La configuración de este parámetro se puede cambiar dentro de sesiones individuales, pero solo antes del primer uso de tablas temporales dentro de la sesión.
La base de datos PostgreSQL utiliza esta área de memoria para almacenar las tablas temporales de cada sesión, estas se borrarán cuando se cierre la conexión.
El valor predeterminado de temp_buffer =8 MB.
Conclusión
Comprender la arquitectura de la memoria y ajustar los parámetros apropiados es importante para mejorar el rendimiento. Esto es especialmente necesario para sistemas de alta carga de trabajo. Para obtener sugerencias de ajuste de rendimiento más genéricas, consulte esta hoja de trucos de rendimiento para PostgreSQL.



