Entrar en producción es una tarea muy importante que debe ser cuidadosamente pensada y planificada de antemano. Algunas decisiones no tan buenas pueden corregirse fácilmente después, pero otras no. Por lo tanto, siempre es mejor dedicar ese tiempo adicional a leer los documentos oficiales, los libros y las investigaciones realizadas por otros antes que lamentarse más tarde. Esto es cierto para la mayoría de las implementaciones de sistemas informáticos y PostgreSQL no es una excepción.
Planificación Inicial del Sistema
Algunas decisiones deben tomarse desde el principio, antes de que el sistema entre en funcionamiento. El DBA de PostgreSQL debe responder a una serie de preguntas:¿Se ejecutará la base de datos en bare metal, máquinas virtuales o incluso en contenedores? ¿Se ejecutará en las instalaciones de la organización o en la nube? ¿Qué sistema operativo se utilizará? ¿El almacenamiento será del tipo discos giratorios o SSD? Para cada escenario o decisión, hay pros y contras y la llamada final se hará en cooperación con las partes interesadas de acuerdo con los requisitos de la organización. Tradicionalmente, la gente solía ejecutar PostgreSQL en bare metal, pero esto ha cambiado drásticamente en los últimos años con más y más proveedores de nube que ofrecen PostgreSQL como una opción estándar, lo que es una señal de la amplia adopción y el resultado de la creciente popularidad de PostgreSQL. Independientemente de la solución específica, el DBA debe garantizar que los datos estarán seguros, lo que significa que la base de datos podrá sobrevivir a los bloqueos, y este es el criterio número uno al tomar decisiones sobre hardware y almacenamiento. ¡Así que esto nos lleva al primer consejo!
Consejo 1
No importa lo que anuncie el controlador de disco, el fabricante del disco o el proveedor de almacenamiento en la nube, siempre debe asegurarse de que el almacenamiento no mienta sobre fsync. Una vez que fsync regresa OK, los datos deben estar seguros en el medio sin importar lo que suceda después (bloqueo, falla de energía, etc.). Una buena herramienta que lo ayudará a probar la confiabilidad de la caché de reescritura de sus discos es diskchecker.pl.
Simplemente lea las notas:https://brad.livejournal.com/2116715.html y haga la prueba.
Use una máquina para escuchar eventos y la máquina real para probar. Deberías ver:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0al final del informe sobre la máquina probada.
La segunda preocupación después de la confiabilidad debe ser sobre el rendimiento. Las decisiones sobre el sistema (CPU, memoria), solían ser mucho más vitales ya que era bastante difícil cambiarlas más tarde. Pero en la actualidad, en la era de la nube, podemos ser más flexibles con respecto a los sistemas en los que se ejecuta la base de datos. Lo mismo ocurre con el almacenamiento, especialmente en las primeras etapas de la vida de un sistema y mientras los tamaños aún son pequeños. Cuando la base de datos supera la cifra de TB en tamaño, se vuelve cada vez más difícil cambiar los parámetros básicos de almacenamiento sin la necesidad de copiar completamente la base de datos, o peor aún, realizar un pg_dump, pg_restore. El segundo consejo es sobre el rendimiento del sistema.
Consejo 2
De manera similar a probar siempre las promesas de los fabricantes con respecto a la confiabilidad, lo mismo debe hacer con el rendimiento del hardware. Bonnie ++ es el punto de referencia de rendimiento de almacenamiento más popular para sistemas similares a Unix. Para las pruebas generales del sistema (CPU, memoria y también almacenamiento), nada es más representativo que el rendimiento de la base de datos. Por lo tanto, la prueba de rendimiento básica en su nuevo sistema sería ejecutar pgbench, el conjunto de referencia oficial de PostgreSQL basado en TCP-B.
Comenzar con pgbench es bastante fácil, todo lo que tiene que hacer es:
[email protected]:~$ createdb pgbench
[email protected]:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
[email protected]:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
[email protected]:~$Siempre debe consultar pgbench después de cualquier cambio importante que desee evaluar y comparar los resultados.
Implementación, Automatización y Supervisión del Sistema
Una vez que entre en funcionamiento, es muy importante tener los componentes principales de su sistema documentados y reproducibles, tener procedimientos automatizados para crear servicios y tareas recurrentes y también tener las herramientas para realizar un monitoreo continuo.
Consejo 3
Una forma práctica de comenzar a usar PostgreSQL con todas sus funciones empresariales avanzadas es ClusterControl de Variousnines. Uno puede tener un clúster PostgreSQL de clase empresarial, con solo hacer unos pocos clics. ClusterControl proporciona todos los servicios antes mencionados y muchos más. Configurar ClusterControl es bastante fácil, solo siga las instrucciones en la documentación oficial. Una vez que haya preparado sus sistemas (generalmente uno para ejecutar CC y otro para PostgreSQL para una configuración básica) y haya realizado la configuración de SSH, debe ingresar los parámetros básicos (IP, número de puerto, etc.), y si todo va bien, debería ver un resultado como el siguiente:
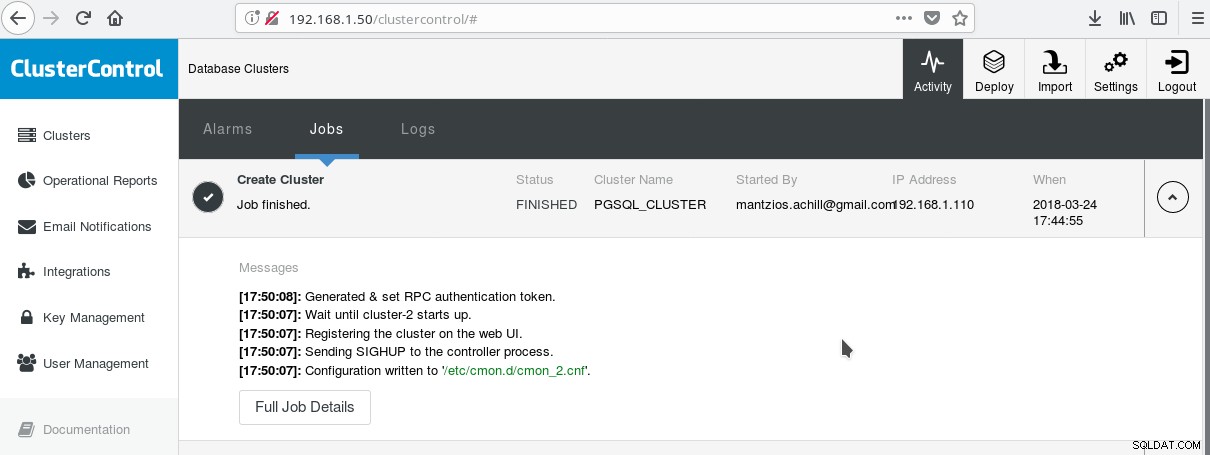
Y en la pantalla principal de clústeres:
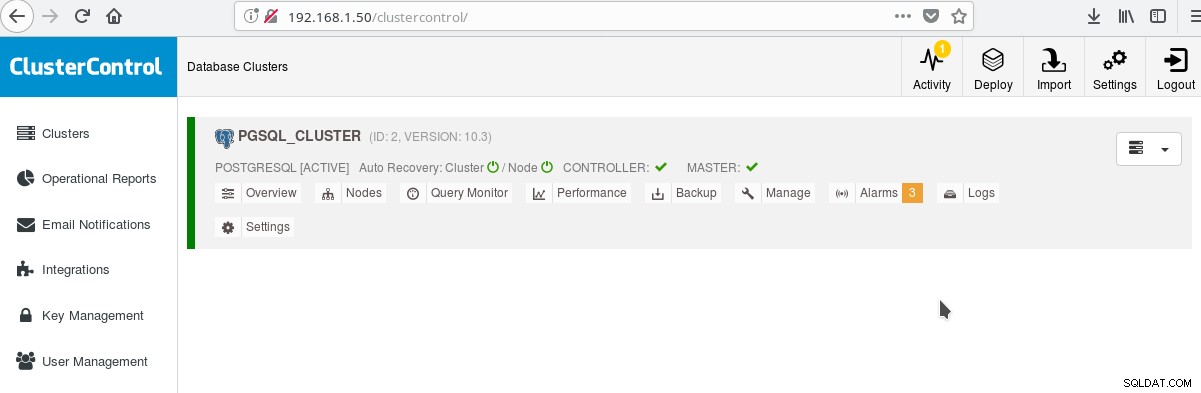
¡Puede iniciar sesión en su servidor maestro y comenzar a crear su esquema! Por supuesto, puede usar como base el clúster que acaba de crear para desarrollar aún más su infraestructura (topología). En general, una buena idea es tener un diseño de sistema de archivos de servidor estable y una configuración final en su servidor PostgreSQL y bases de datos de usuarios/aplicaciones antes de comenzar a crear clones y standby (esclavos) basados en su nuevo servidor recién creado.
Diseño, parámetros y configuraciones de PostgreSQL
En la fase de inicialización del clúster, la decisión más importante es si utilizar sumas de comprobación de datos en las páginas de datos o no. Si desea la máxima seguridad de datos para sus datos valiosos (futuros), entonces este es el momento de hacerlo. Si existe la posibilidad de que desee esta función en el futuro y se olvida de hacerlo en esta etapa, no podrá cambiarla más adelante (sin pg_dump/pg_restore). Este es el siguiente consejo:
Consejo 4
Para habilitar las sumas de verificación de datos, ejecute initdb de la siguiente manera:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Tenga en cuenta que esto debe hacerse en el momento del consejo 3 que describimos anteriormente. Si ya creó el clúster con ClusterControl, tendrá que volver a ejecutar pg_createcluster a mano, ya que en el momento de escribir este artículo no hay forma de decirle al sistema o CC que incluya esta opción.
Otro paso muy importante antes de entrar en producción es la planificación del diseño del sistema de archivos del servidor. La mayoría de las distribuciones modernas de Linux (al menos las basadas en Debian) montan todo en / pero con PostgreSQL normalmente no quieres eso. Es beneficioso tener su(s) espacio(s) de tablas en volúmenes separados, tener un volumen dedicado para los archivos WAL y otro para el registro pg. Pero lo más importante es mover el WAL a su propio disco. Esto nos lleva al siguiente consejo.
Consejo 5
Con PostgreSQL 10 en Debian Stretch, puede mover su WAL a un nuevo disco con los siguientes comandos (suponiendo que el nuevo disco se llame /dev/sdb):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlEs extremadamente importante configurar correctamente la configuración regional y la codificación de sus bases de datos. Pase por alto esto en la fase createdb y se arrepentirá mucho, ya que su aplicación/base de datos se traslada a los territorios i18n, l10n. El siguiente consejo muestra cómo hacerlo.
Consejo 6
Debe leer los documentos oficiales y decidir sobre la configuración de COLLATE y CTYPE (createdb --locale=) (responsable del orden de clasificación y clasificación de caracteres), así como la configuración del juego de caracteres (createdb --encoding=). Especificar UTF8 como codificación permitirá que su base de datos almacene texto en varios idiomas.
Descargue el documento técnico hoy Gestión y automatización de PostgreSQL con ClusterControl Obtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnicoAlta disponibilidad de PostgreSQL
Desde PostgreSQL 9.0, cuando la replicación de transmisión se convirtió en una característica estándar, se hizo posible tener uno o más modos de espera activos de solo lectura, lo que permitió la posibilidad de dirigir el tráfico de solo lectura a cualquiera de los esclavos disponibles. Existen nuevos planes para la replicación multimaestro, pero en el momento de escribir este artículo (10.3) solo es posible tener un maestro de lectura y escritura, al menos en el producto oficial de código abierto. Para el siguiente consejo que trata exactamente de esto.
Consejo 7
Usaremos nuestro ClusterControl PGSQL_CLUSTER creado en el Consejo 3. Primero creamos una segunda máquina que actuará como nuestro esclavo de solo lectura (espera en caliente en la terminología de PostgreSQL). Luego hacemos clic en Agregar esclavo de replicación, y seleccionamos nuestro maestro y el nuevo esclavo. Después de que finalice el trabajo, debería ver este resultado:
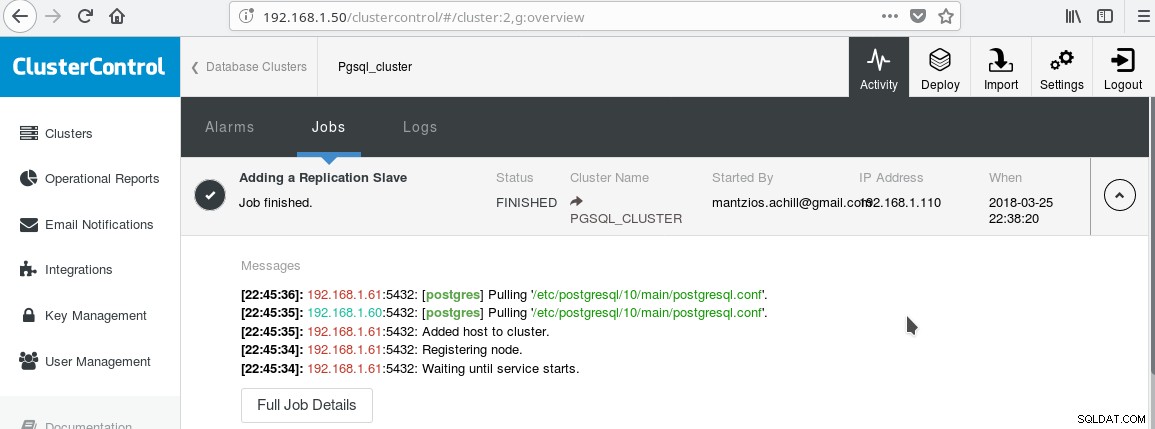
Y el clúster ahora debería verse así:
Tenga en cuenta el icono verde "marcado" en la etiqueta "ESCLAVOS" junto a "MAESTRO". Puede verificar que la replicación de transmisión funciona creando un objeto de base de datos (base de datos, tabla, etc.) o insertando algunas filas en una tabla en el maestro y ver el cambio en el modo de espera.
La presencia del standby de solo lectura nos permite realizar el equilibrio de carga para los clientes realizando consultas de solo selección entre los dos servidores disponibles, el maestro y el esclavo. Esto nos lleva al consejo 8.
Consejo 8
Puede habilitar el equilibrio de carga entre los dos servidores mediante HAProxy. Con ClusterControl esto es bastante fácil de hacer. Hace clic en Administrar-> Equilibrador de carga. Después de elegir su servidor HAProxy, ClusterControl instalará todo por usted:xinetd en todas las instancias que especificó y HAProxy en su servidor designado HAProxy. Después de que el trabajo se haya completado con éxito, debería ver:
Tenga en cuenta la marca verde HAPROXY junto a los ESCLAVOS. Ahora puedes probar que HAProxy funciona:
[email protected]:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Consejo 9
Además de configurar HA y equilibrio de carga, siempre es beneficioso tener algún tipo de grupo de conexiones frente al servidor PostgreSQL. Pgpool y Pgbouncer son dos proyectos provenientes de la comunidad de PostgreSQL. Muchos servidores de aplicaciones empresariales también proporcionan sus propios grupos. Pgbouncer ha sido muy popular debido a su simplicidad, velocidad y la función de "agrupación de transacciones", por la cual, la conexión al servidor se libera una vez que finaliza la transacción, lo que lo hace reutilizable para transacciones posteriores que pueden provenir de la misma sesión o diferente. . La configuración de la agrupación de transacciones rompe algunas características de la agrupación de sesiones, pero en general la conversión a una configuración lista para la "agrupación de transacciones" es fácil y las desventajas no son tan importantes en el caso general. Una configuración común es configurar el grupo del servidor de aplicaciones con conexiones semipersistentes:un grupo bastante más grande de conexiones por usuario o por aplicación (que se conectan a pgbouncer) con largos tiempos de inactividad. De esta forma, el tiempo de conexión desde la aplicación es mínimo, mientras que pgbouncer ayudará a mantener las conexiones al servidor en el menor número posible.
Una cosa que probablemente será motivo de preocupación una vez que comience a usar PostgreSQL es comprender y corregir las consultas lentas. Las herramientas de monitoreo que mencionamos en el blog anterior como pg_stat_statements y también las pantallas de herramientas como ClusterControl lo ayudarán a identificar y posiblemente sugerir ideas para corregir consultas lentas. Sin embargo, una vez que identifique la consulta lenta, deberá ejecutar EXPLAIN o EXPLAIN ANALYZE para ver exactamente los costos y los tiempos involucrados en el plan de consulta. El siguiente consejo es sobre una herramienta muy útil para hacer eso.
Consejo 10
Debe ejecutar EXPLAIN ANALYZE en su base de datos, y luego copiar el resultado y pegarlo en la herramienta en línea de análisis de explicación de depesz y hacer clic en enviar. Luego verá tres pestañas:HTML, TEXTO y ESTADÍSTICAS. HTML contiene costo, tiempo y número de bucles para cada nodo en el plan. La pestaña ESTADÍSTICAS muestra estadísticas por tipo de nodo. Debe observar la columna "% de la consulta", para saber dónde sufre exactamente su consulta.
¡A medida que se familiarice con PostgreSQL, encontrará muchos más consejos por su cuenta!