Asumiendo Postgres 9.1 o posterior.
Simplifiqué/optimicé su consulta básica para recuperar los valores más recientes:
SELECT DISTINCT ON (1,2)
c.unique_id, a.attname AS col, c.value
FROM pg_attribute a
LEFT JOIN changes c ON c.column_name = a.attname
AND c.table_name = 'instances'
-- AND c.unique_id = 3 -- uncomment to fetch single row
WHERE a.attrelid = 'instances'::regclass -- schema-qualify to be clear?
AND a.attnum > 0 -- no system columns
AND NOT a.attisdropped -- no deleted columns
ORDER BY 1, 2, c.updated_at DESC;
Consulto el catálogo de PostgreSQL en lugar del esquema de información estándar porque es más rápido. Tenga en cuenta el lanzamiento especial a ::regclass .
Ahora, eso te da una mesa . Quiere todos los valores para un unique_id en una fila .
Para conseguirlo tienes básicamente tres opciones:
-
Una subselección (o unión) por columna. Caro y difícil de manejar. Pero una opción válida solo para unas pocas columnas.
-
Un gran
CASEdeclaración. -
Una función pivote . PostgreSQL proporciona el
crosstab()función en el módulo adicionaltablefuncpara eso.
Instrucciones básicas:- Consulta de tabulación cruzada de PostgreSQL
Tabla dinámica básica con crosstab()
Reescribí completamente la función:
SELECT *
FROM crosstab(
$x$
SELECT DISTINCT ON (1, 2)
unique_id, column_name, value
FROM changes
WHERE table_name = 'instances'
-- AND unique_id = 3 -- un-comment to fetch single row
ORDER BY 1, 2, updated_at DESC;
$x$,
$y$
SELECT attname
FROM pg_catalog.pg_attribute
WHERE attrelid = 'instances'::regclass -- possibly schema-qualify table name
AND attnum > 0
AND NOT attisdropped
AND attname <> 'unique_id'
ORDER BY attnum
$y$
)
AS tbl (
unique_id integer
-- !!! You have to list all columns in order here !!! --
);
Separé la búsqueda de catálogo de la consulta de valor, como crosstab() La función con dos parámetros proporciona nombres de columna por separado. Los valores que faltan (sin entrada en los cambios) se sustituyen por NULL automáticamente. ¡Una combinación perfecta para este caso de uso!
Suponiendo que attname coincide con column_name . Excluyendo unique_id , que juega un papel especial.
Automatización completa
Dirigiéndose a su comentario:Hay una manera para proporcionar la lista de definición de columna automáticamente. Sin embargo, no es para los débiles de corazón.
Utilizo una serie de funciones avanzadas de Postgres aquí:crosstab() , función plpgsql con SQL dinámico, manejo de tipos compuestos, cotización avanzada en dólares, búsqueda de catálogo, función agregada, función de ventana, tipo de identificador de objeto, ...
Entorno de prueba:
CREATE TABLE instances (
unique_id int
, col1 text
, col2 text -- two columns are enough for the demo
);
INSERT INTO instances VALUES
(1, 'foo1', 'bar1')
, (2, 'foo2', 'bar2')
, (3, 'foo3', 'bar3')
, (4, 'foo4', 'bar4');
CREATE TABLE changes (
unique_id int
, table_name text
, column_name text
, value text
, updated_at timestamp
);
INSERT INTO changes VALUES
(1, 'instances', 'col1', 'foo11', '2012-04-12 00:01')
, (1, 'instances', 'col1', 'foo12', '2012-04-12 00:02')
, (1, 'instances', 'col1', 'foo1x', '2012-04-12 00:03')
, (1, 'instances', 'col2', 'bar11', '2012-04-12 00:11')
, (1, 'instances', 'col2', 'bar17', '2012-04-12 00:12')
, (1, 'instances', 'col2', 'bar1x', '2012-04-12 00:13')
, (2, 'instances', 'col1', 'foo2x', '2012-04-12 00:01')
, (2, 'instances', 'col2', 'bar2x', '2012-04-12 00:13')
-- NO change for col1 of row 3 - to test NULLs
, (3, 'instances', 'col2', 'bar3x', '2012-04-12 00:13');
-- NO changes at all for row 4 - to test NULLs
Función automatizada para una tabla
CREATE OR REPLACE FUNCTION f_curr_instance(int, OUT t public.instances) AS
$func$
BEGIN
EXECUTE $f$
SELECT *
FROM crosstab($x$
SELECT DISTINCT ON (1,2)
unique_id, column_name, value
FROM changes
WHERE table_name = 'instances'
AND unique_id = $f$ || $1 || $f$
ORDER BY 1, 2, updated_at DESC;
$x$
, $y$
SELECT attname
FROM pg_catalog.pg_attribute
WHERE attrelid = 'public.instances'::regclass
AND attnum > 0
AND NOT attisdropped
AND attname <> 'unique_id'
ORDER BY attnum
$y$) AS tbl ($f$
|| (SELECT string_agg(attname || ' ' || atttypid::regtype::text
, ', ' ORDER BY attnum) -- must be in order
FROM pg_catalog.pg_attribute
WHERE attrelid = 'public.instances'::regclass
AND attnum > 0
AND NOT attisdropped)
|| ')'
INTO t;
END
$func$ LANGUAGE plpgsql;
La tabla instances está codificado de forma rígida, el esquema calificado para ser inequívoco. Tenga en cuenta el uso del tipo de tabla como tipo de retorno. Hay un tipo de fila registrado automáticamente para cada tabla en PostgreSQL. Esto está obligado a coincidir con el tipo de retorno de crosstab() función.
Esto vincula la función al tipo de tabla:
- Recibirás un mensaje de error si intentas
DROPla mesa - Su función fallará después de un
ALTER TABLE. Tienes que recrearlo (sin cambios). Considero que esto es un error en 9.1.ALTER TABLEno debería interrumpir silenciosamente la función, sino generar un error.
Esto funciona muy bien.
Llamar:
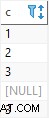
SELECT * FROM f_curr_instance(3);
unique_id | col1 | col2
----------+-------+-----
3 |<NULL> | bar3x
Observe cómo col1 es NULL aquí.
Úselo en una consulta para mostrar una instancia con sus valores más recientes:
SELECT i.unique_id
, COALESCE(c.col1, i.col1)
, COALESCE(c.col2, i.col2)
FROM instances i
LEFT JOIN f_curr_instance(3) c USING (unique_id)
WHERE i.unique_id = 3;
Automatización completa para cualquier mesa
(Agregado en 2016. Esto es dinamita).
Requiere Postgres 9.1 o después. (Se podría hacer que funcionara con la página 8.4, pero no me molesté en parchear).
CREATE OR REPLACE FUNCTION f_curr_instance(_id int, INOUT _t ANYELEMENT) AS
$func$
DECLARE
_type text := pg_typeof(_t);
BEGIN
EXECUTE
(
SELECT format
($f$
SELECT *
FROM crosstab(
$x$
SELECT DISTINCT ON (1,2)
unique_id, column_name, value
FROM changes
WHERE table_name = %1$L
AND unique_id = %2$s
ORDER BY 1, 2, updated_at DESC;
$x$
, $y$
SELECT attname
FROM pg_catalog.pg_attribute
WHERE attrelid = %1$L::regclass
AND attnum > 0
AND NOT attisdropped
AND attname <> 'unique_id'
ORDER BY attnum
$y$) AS ct (%3$s)
$f$
, _type, _id
, string_agg(attname || ' ' || atttypid::regtype::text
, ', ' ORDER BY attnum) -- must be in order
)
FROM pg_catalog.pg_attribute
WHERE attrelid = _type::regclass
AND attnum > 0
AND NOT attisdropped
)
INTO _t;
END
$func$ LANGUAGE plpgsql;
Llamada (proporcionando el tipo de tabla con NULL::public.instances :
SELECT * FROM f_curr_instance(3, NULL::public.instances);
Relacionado:
- Refactorice una función PL/pgSQL para devolver el resultado de varias consultas SELECT
- Cómo establecer el valor del campo variable compuesto usando SQL dinámico