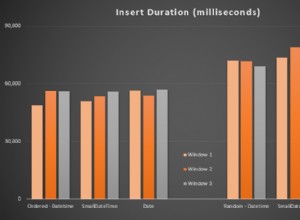
-
Si los modelos no comparten grupos de colores, el diseño sería una tabla:
model [model] comes in color [color] -
Si los modelos comparten grupos de colores, entonces tenga dos tablas:
model [model] comes in the colors of group [group] group [group] has color [color]Estas tablas se unen con proyección a la primera tabla:
SELECT model, color FROM model_group NATURAL JOIN group_color -
Si un modelo puede tener colores excepcionales disponibles y/o no disponibles además o en lugar de un grupo, entonces tenga tablas de excepciones. El grupo de una tabla ahora es su predeterminado colores (si los hay):
model [model] has default color group [group] group [group] has color [color] model [model] is exceptionally available in color [color] model [model] is exceptionally unavailable in color [color]Luego, las tablas de excepción se UNIONAN respectivamente con y MINUSED/EXCEPTed de un JOIN-plus-PROJECT/SELECT para dar la primera tabla:
SELECT group, color FROM model_default NATURAL JOIN group_colour EXCEPT SELECT * FROM model_unavailable UNION SELECT * FROM model_available
La "redundancia" no se trata de valores que aparecen en varios lugares. Se trata de varias filas que indican lo mismo sobre la aplicación.
Cada tabla (y expresión de consulta) tiene una plantilla de declaración de espacios en blanco (con nombre) asociada (también conocida como predicado). Las filas que hacen una afirmación verdadera van en la tabla. Si tiene dos predicados independientes, necesita dos tablas. Los valores relevantes van en las filas de cada uno.
Re filas que hacen declaraciones sobre la aplicación ver esto. (Y busque mis otras respuestas sobre la "declaración" o el "criterio" de una tabla). La normalización ayuda porque reemplaza las tablas cuyas filas indican cosas de la forma "... Y ..." por otras tablas que indican "... " por separado. Ver esto y esto.
Si comparte grupos y solo usa una tabla de dos columnas para modelo y color, entonces su predicado es:
FOR SOME group
model [model] comes in the colors of group [group]
AND group [group] has color [color]
Entonces, la segunda viñeta elimina un solo "Y" de este predicado, es decir, la fuente de una "dependencia multivaluada". De lo contrario, si cambia el grupo de un modelo o los colores de un grupo, tendrá que cambiar simultáneamente varias filas de manera consistente. (El objetivo es reducir los errores y la complejidad de la redundancia, no ahorrar espacio).
Si no desea repetir las cadenas por razones de implementación (dependientes) (espacio ocupado o velocidad de las operaciones a expensas de más uniones), agregue una tabla de identificadores de nombres y cadenas y reemplace las columnas y valores de su nombre anterior por columnas y valores de identificación. (Eso no es normalización, eso complica su esquema en aras de las compensaciones de optimización de datos dependientes de la implementación. Y debe demostrar esto es necesario y funciona).