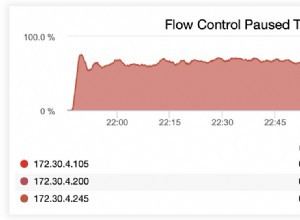
Afortunadamente, estás usando PostgreSQL. La función de ventana generate_series() es tu amigo.
Caso de prueba
Dada la siguiente tabla de prueba (que usted debería haber proporcionado):
CREATE TABLE event(event_id serial, ts timestamp);
INSERT INTO event (ts)
SELECT generate_series(timestamp '2018-05-01'
, timestamp '2018-05-08'
, interval '7 min') + random() * interval '7 min';
Un evento por cada 7 minutos (más 0 a 7 minutos, al azar).
Solución básica
Esta consulta cuenta eventos para cualquier intervalo de tiempo arbitrario. 17 minutos en el ejemplo:
WITH grid AS (
SELECT start_time
, lead(start_time, 1, 'infinity') OVER (ORDER BY start_time) AS end_time
FROM (
SELECT generate_series(min(ts), max(ts), interval '17 min') AS start_time
FROM event
) sub
)
SELECT start_time, count(e.ts) AS events
FROM grid g
LEFT JOIN event e ON e.ts >= g.start_time
AND e.ts < g.end_time
GROUP BY start_time
ORDER BY start_time;
-
La consulta recupera
tsmínimo y máximo de la tabla base para cubrir el rango de tiempo completo. En su lugar, puede utilizar un intervalo de tiempo arbitrario. -
Proporcione cualquiera intervalo de tiempo según sea necesario.
-
Produce una fila para cada franja horaria Si no ocurrió ningún evento durante ese intervalo, el conteo es
0. -
Asegúrese de controlar los límites superior e inferior correctamente:
- Resultados inesperados de una consulta SQL con marcas de tiempo BETWEEN
-
La función de ventana
lead()tiene una característica que a menudo se pasa por alto:puede proporcionar un valor predeterminado para cuando no existe una fila inicial. Proporcionar'infinity'en el ejemplo. De lo contrario, el último intervalo se cortaría con un límite superiorNULL.
Equivalente mínimo
La consulta anterior usa un CTE y lead() y sintaxis detallada. Elegante y quizás más fácil de entender, pero un poco más caro. Aquí hay una versión mínima, más corta y más rápida:
SELECT start_time, count(e.ts) AS events
FROM (SELECT generate_series(min(ts), max(ts), interval '17 min') FROM event) g(start_time)
LEFT JOIN event e ON e.ts >= g.start_time
AND e.ts < g.start_time + interval '17 min'
GROUP BY 1
ORDER BY 1;
Ejemplo para "cada 15 minutos en la última semana"`
Y formateando con to_char() .
SELECT to_char(start_time, 'YYYY-MM-DD HH24:MI'), count(e.ts) AS events
FROM generate_series(date_trunc('day', localtimestamp - interval '7 days')
, localtimestamp
, interval '15 min') g(start_time)
LEFT JOIN event e ON e.ts >= g.start_time
AND e.ts < g.start_time + interval '15 min'
GROUP BY start_time
ORDER BY start_time;
Todavía ORDER BY y GROUP BY en la marca de tiempo subyacente valor , no en la cadena formateada. Eso es más rápido y más confiable.
db<>violín aquí
Respuesta relacionada que produce un conteo continuo durante el período de tiempo:
- PostgreSQL:conteo continuo de filas para una consulta 'por minuto'