No. Dado que no existe un orden natural de filas en una tabla de base de datos, todo lo que tiene que trabajar son los valores en su tabla.
Bueno, existen las columnas del sistema específicas de Postgres cmin y ctid usted podría abuso hasta cierto punto.
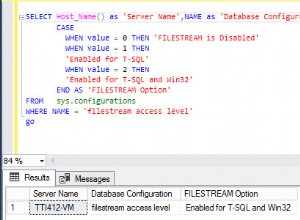
El ID de la tupla (ctid ) contiene el número de bloque de archivo y la posición en el bloque de la fila. Esto representa el ordenamiento físico actual en el disco. Las adiciones posteriores tendrán un ctid más grande , normalmente . Su declaración SELECT podría verse así
SELECT *, ctid -- save ctid from last row in last_ctid
FROM tbl
WHERE ctid > last_ctid
ORDER BY ctid
ctid tiene el tipo de dato tid . Ejemplo:'(0,9)'::tid
Sin embargo, no es estable como identificador a largo plazo, ya que VACUUM o cualquier UPDATE concurrente o algunas otras operaciones pueden cambiar la ubicación física de una tupla en cualquier momento. Sin embargo, durante la duración de una transacción es estable. Y si solo está insertando y nada de lo contrario, debería funcionar localmente para su propósito.
Agregaría una columna de marca de tiempo con now() predeterminado además del serial columna ...
También dejaría una columna predeterminada rellena tu id columna (una serial o IDENTITY columna). Eso recupera el número de la secuencia en una etapa posterior a la obtención explícita y luego la inserción, minimizando así (pero no eliminando) la ventana para una condición de carrera:la posibilidad de que un id más bajo se insertaría en un momento posterior. Instrucciones detalladas:
- Columna de tabla de incremento automático