Te preguntas sobre ¿Cómo calculo cuáles son las ciudades más cercanas? Por ejemplo. Si estuviera mirando la ciudad 1 (París), los resultados deberían ser:Londres (2), Nueva York (3) y según el conjunto de datos proporcionado, solo hay una cosa que relacionar, que son las etiquetas comunes entre las ciudades, por lo que las ciudades que comparten las etiquetas comunes serían las más cercanas a continuación, es la subconsulta que encuentra las ciudades (aparte de la que se proporciona a encontrar sus ciudades más cercanas) que comparte las etiquetas comunes
SELECT * FROM `cities` WHERE id IN (
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Trabajando
Supongo que ingresará una de las identificaciones o el nombre de la ciudad para encontrar la más cercana en mi caso, "París" tiene la identificación
SELECT tag_id FROM `cities_tags` WHERE city_id=1
Encontrará todas las etiquetas de identificación que tiene París entonces
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Obtendrá todas las ciudades excepto París que tiene las mismas etiquetas que también tiene París
Aquí está tu Fiddle
Al leer sobre la similitud/índice de Jaccard Encontré algunas cosas para entender sobre lo que realmente son los términos, tomemos este ejemplo, tenemos dos conjuntos A y B
Ahora muévete hacia tu escenario
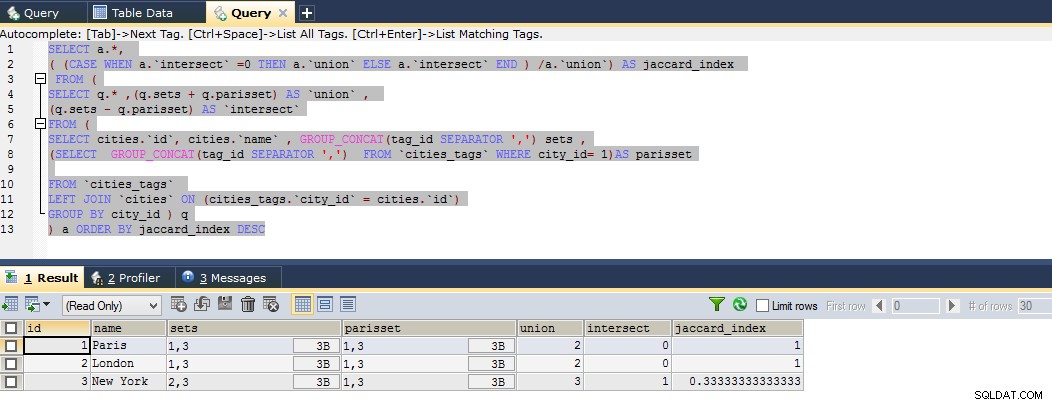
Aquí está la consulta hasta ahora que calcula el índice jaccard perfecto; puede ver el siguiente ejemplo de violín
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`)
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
En la consulta anterior, he derivado el conjunto de resultados a dos subselecciones para obtener mis alias calculados personalizados
Puede agregar el filtro en la consulta anterior para no calcular la similitud consigo mismo
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`) WHERE cities.`id` !=1
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
Entonces, el resultado muestra que París está estrechamente relacionada con Londres y luego con Nueva York
Fiddle de similitud de Jaccard