para un mejor rendimiento, podría intentar usar un índice compuesto... basado en la columna involucrada en su cláusula where
e intentar cambiar la cláusula IN en una unión interna
asumiendo que el contenido de su cláusula IN es un conjunto de valores fijos podría usar union (o una nueva tabla con el valor que necesita)
por ejemplo, usando la unión (puede hacer algo similar si la cláusula IN es una subconsulta)
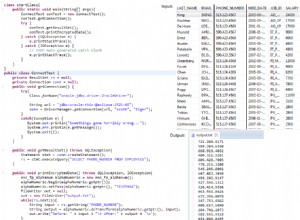
select user_table.colA ,ColB , count(*) as count
from user_table
INNER JOIN (
select 'FIXED1' colA
union
select 'FIXED2'
....
union
select 'FIXEDX'
) t on t.colA = user_table.colA
where colC >='2019-09-01 00:00:00'
and ColB = 17
group by colA ,ColB;
también podría agregar un índice compuesto en la tabla user_table en las columnas
colA, colB, colC
para lo relacionado con el elemento utilizado por el optimizador de consultas mysql para decidir el índice a utilizar allí varios aspectos y para todos estos, el optimizador de consultas asigna un costo
cualquier cosa que deba tener en cuenta
- la columna involucrada en la cláusula Where
- El tamaño de las tablas (y no en este caso el tamaño de las tablas en combinación)
- Una estimación de cuántas filas se recuperarán (para decidir si usar un índice o simplemente escanear la tabla)
- si los tipos de datos coinciden o no entre las columnas de la cláusula jion y where
- El uso de funciones o conversión de tipos de datos, incluida la falta de coincidencia en la intercalación
- El tamaño del índice
- cardinalidad del índice
y para todas estas opciones se evalúa un costo y esto lleva a que el índice elija
En su caso, la colC como fecha podría implicar una conversión de datos (respete los valores literales como cadena) y para esto no se elige el índice.
También es por esto que he sugerido un índice compuesto con la columna más a la izquierda relacionada con valores no convertidos