Quería participar con la opción de resolver su tarea con BigQuery puro (SQL estándar)
Requisitos previos/suposiciones :los datos de origen están en sandbox.temp.id1_id2_pairs
Debe reemplazar esto con el suyo propio o si desea probar con datos ficticios de su pregunta, puede crear esta tabla como se muestra a continuación (por supuesto, reemplace sandbox.temp con tu propio project.dataset )
Asegúrese de configurar la tabla de destino correspondiente
Nota :puede encontrar todas las Consultas respectivas (como texto) en la parte inferior de esta respuesta, pero por ahora estoy ilustrando mi respuesta con capturas de pantalla, por lo que se presenta todo:consulta, resultado y opciones utilizadas
Entonces, habrá tres pasos:
Paso 1 - Inicialización
Aquí, solo hacemos la agrupación inicial de id1 según las conexiones con id2:
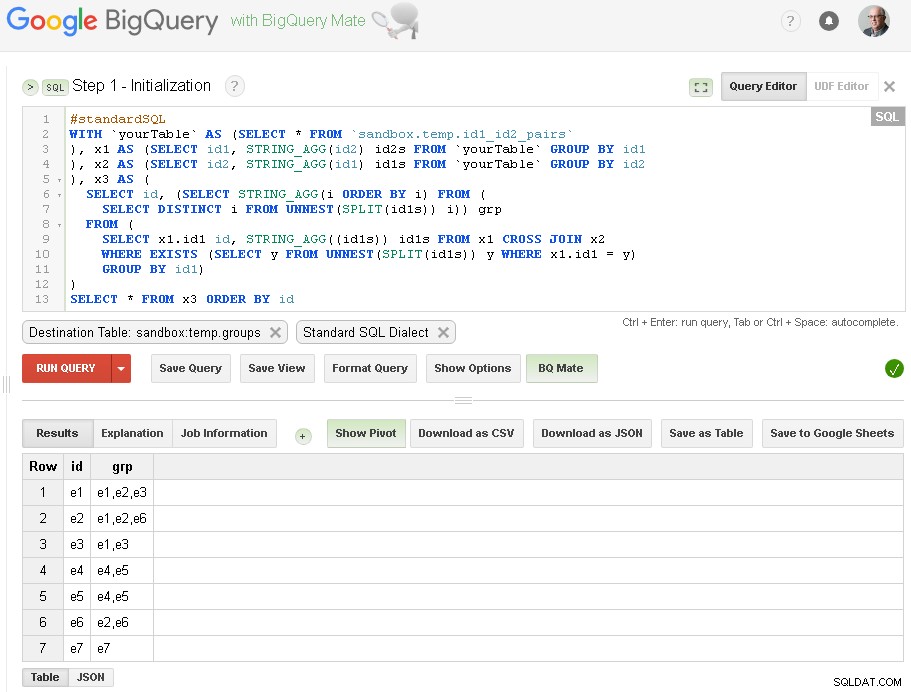
Como puede ver aquí, creamos una lista de todos los valores id1 con las conexiones respectivas basadas en una conexión simple de un nivel a través de id2
La tabla de salida es sandbox.temp.groups
Paso 2:Iteraciones de agrupación
En cada iteración, enriqueceremos la agrupación en función de los grupos ya establecidos.
La fuente de la consulta es la tabla de salida del paso anterior (sandbox.temp.groups ) y Destination es la misma tabla (sandbox.temp.groups ) con Sobrescribir
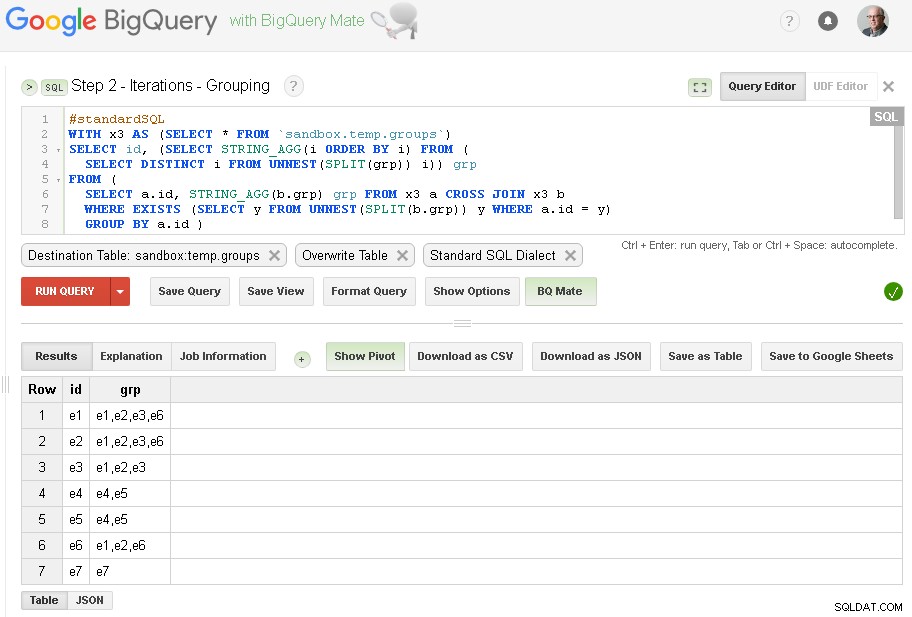
Continuaremos con las iteraciones hasta que el recuento de grupos encontrados sea el mismo que en la iteración anterior
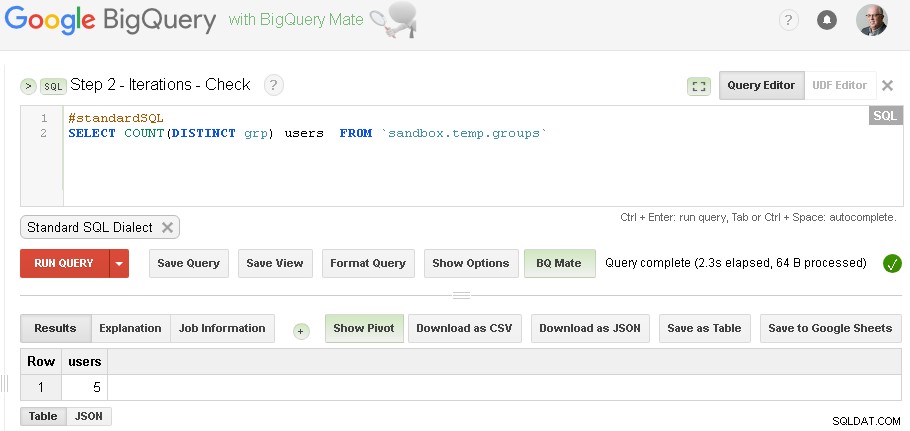
Nota :solo puede tener abiertas dos pestañas de la interfaz de usuario web de BigQuery (como se muestra arriba) y, sin cambiar ningún código, simplemente ejecute Agrupación y luego verifique una y otra vez hasta que la iteración converja
(para datos específicos que usé en la sección de requisitos previos, tuve tres iteraciones:la primera iteración produjo 5 usuarios, la segunda iteración produjo 3 usuarios y la tercera iteración produjo nuevamente 3 usuarios, lo que indica que terminamos con las iteraciones.
Por supuesto, en el caso de la vida real, el número de iteraciones podría ser más de tres, por lo que necesitamos algún tipo de automatización (consulte la sección respectiva al final de la respuesta).
Paso 3:agrupación final
Cuando se completa la agrupación id1, podemos agregar la agrupación final para id2
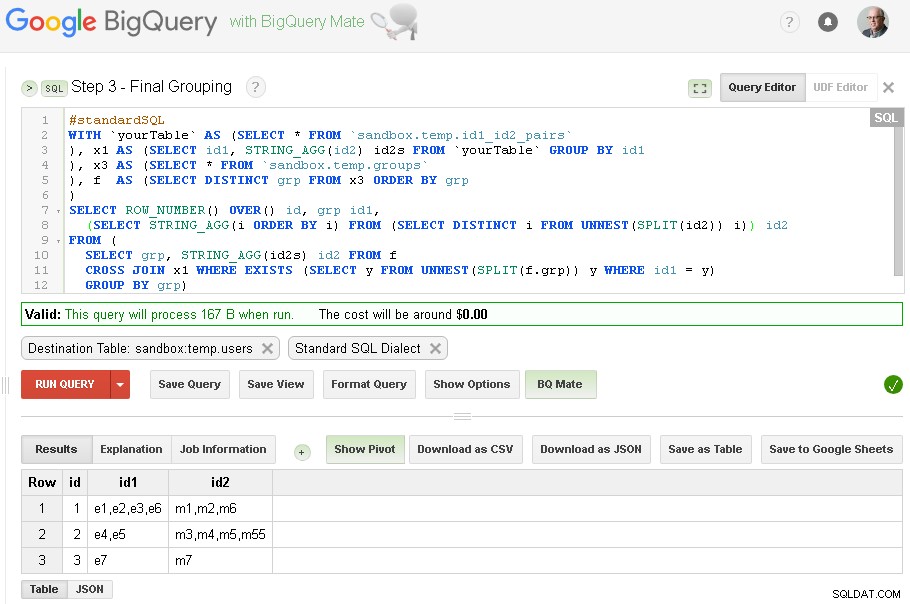
El resultado final ahora está en sandbox.temp.users mesa
Consultas usadas (no olvide establecer las respectivas tablas de destino y sobrescribir cuando sea necesario según la lógica y las capturas de pantalla descritas anteriormente):
Requisitos previos:
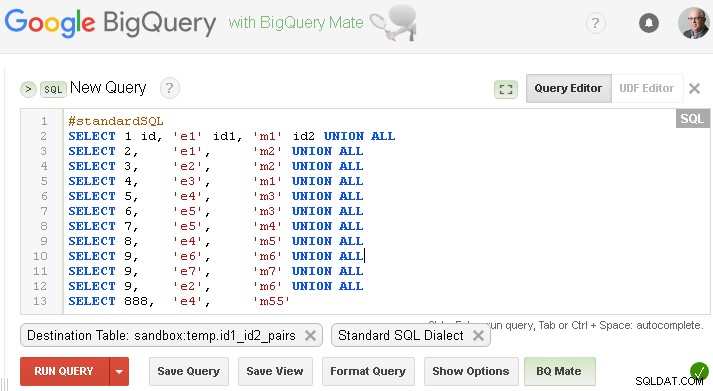
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Paso 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Paso 2 - Agrupación
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Paso 2 - Comprobar
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
Paso 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Automatización :
Por supuesto, el "proceso" anterior se puede ejecutar manualmente en caso de que las iteraciones converjan rápidamente, por lo que terminará con 10-20 ejecuciones. Pero en casos más reales, puede automatizar esto fácilmente con cualquier cliente
de su elección