Generaremos algunas direcciones IP, geolocalizaremos el elemento y las trazaremos:
library(iptools)
library(rgeolocate)
library(tidyverse)
Genere un millón de direcciones IPv4 aleatorias (distribuidas de manera demasiado uniforme):
ips <- ip_random(1000000)
Y, geolocalízalos:
system.time(
rgeolocate::maxmind(
ips, "~/Data/GeoLite2-City.mmdb", c("longitude", "latitude")
) -> xdf
)
## user system elapsed
## 5.016 0.131 5.217
5s para 1m IPv4s. 👍🏼
Ahora, debido a la uniformidad, las burbujas serán estúpidamente pequeñas, así que solo para este ejemplo las redondearemos un poco:
xdf %>%
mutate(
longitude = (longitude %/% 5) * 5,
latitude = (latitude %/% 5) * 5
) %>%
count(longitude, latitude) -> pts
Y, grafícalos:
ggplot(pts) +
geom_point(
aes(longitude, latitude, size = n),
shape=21, fill = "steelblue", color = "white", stroke=0.25
) +
ggalt::coord_proj("+proj=wintri") +
ggthemes::theme_map() +
theme(legend.justification = "center") +
theme(legend.position = "bottom")
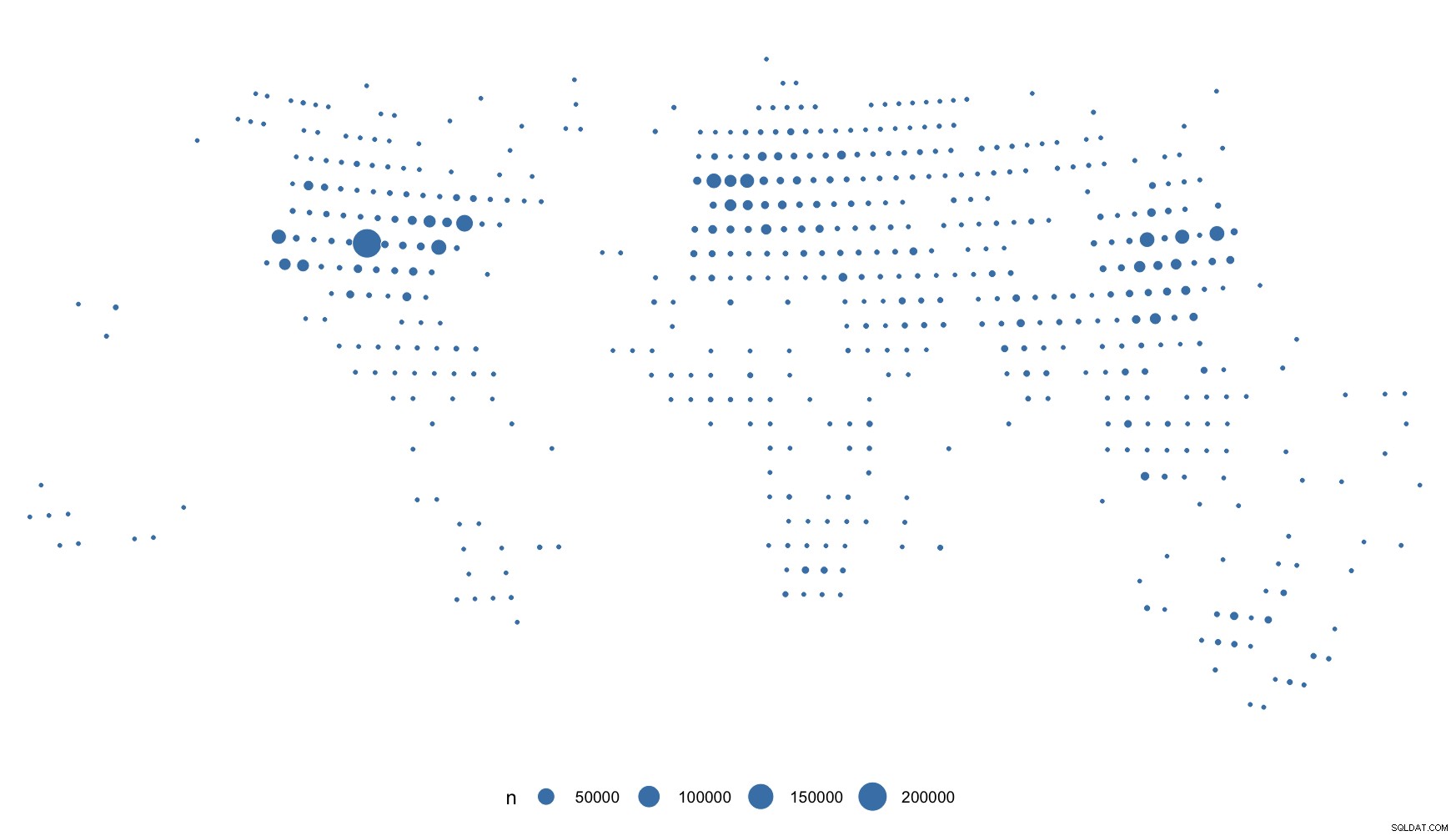
Puedes ver lo que quiero decir con "demasiado uniforme". Pero tiene IPv4 "reales", por lo que debería ser gtg.
Considere usar scale_size_area() , pero, sinceramente, considere no trazar IPv4 en un mapa geográfico. Me gano la vida investigando a escala de Internet y las afirmaciones de precisión dejan mucho que desear. Rara vez voy por debajo de la atribución a nivel de país por ese motivo (y pagamos por datos "reales").