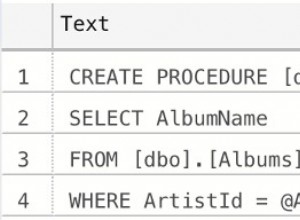
La partición en postgresql funciona muy bien para registros grandes. Primero cree la tabla principal:
create table game_history_log (
gameid integer,
views integer,
plays integer,
likes integer,
log_date date
);
Ahora crea las particiones. En este caso uno para cada mes, 900k filas, estaría bien:
create table game_history_log_201210 (
check (log_date between '2012-10-01' and '2012-10-31')
) inherits (game_history_log);
create table game_history_log_201211 (
check (log_date between '2012-11-01' and '2012-11-30')
) inherits (game_history_log);
Observe las restricciones de verificación en cada partición. Si intenta insertar en la partición incorrecta:
insert into game_history_log_201210 (
gameid, views, plays, likes, log_date
) values (1, 2, 3, 4, '2012-09-30');
ERROR: new row for relation "game_history_log_201210" violates check constraint "game_history_log_201210_log_date_check"
DETAIL: Failing row contains (1, 2, 3, 4, 2012-09-30).
Una de las ventajas de la partición es que solo buscará en la partición correcta, lo que reducirá de manera drástica y constante el tamaño de la búsqueda, independientemente de cuántos años de datos haya. Aquí la explicación para la búsqueda de una fecha determinada:
explain
select *
from game_history_log
where log_date = date '2012-10-02';
QUERY PLAN
------------------------------------------------------------------------------------------------------
Result (cost=0.00..30.38 rows=9 width=20)
-> Append (cost=0.00..30.38 rows=9 width=20)
-> Seq Scan on game_history_log (cost=0.00..0.00 rows=1 width=20)
Filter: (log_date = '2012-10-02'::date)
-> Seq Scan on game_history_log_201210 game_history_log (cost=0.00..30.38 rows=8 width=20)
Filter: (log_date = '2012-10-02'::date)
Tenga en cuenta que, aparte de la tabla principal, solo escaneó la partición correcta. Obviamente, puede tener índices en las particiones para evitar un escaneo secuencial.