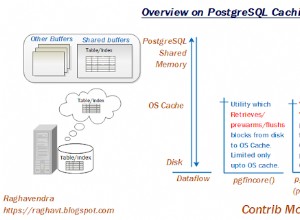
Una solución rápida sería filtrar en la subconsulta:
SELECT count(d.id) AS dcount, s.id, s.name
FROM sites s
LEFT JOIN deals d ON (s.id = d.site_id AND d.is_active = 1)
WHERE (s.is_active = 1)
AND s.id IN(
SELECT g.site_id
FROM gstats g
WHERE g.start_date > '2015-04-30' AND g.site_id = s.id
GROUP BY g.site_id
HAVING SUM(g.results) > 100
)
GROUP BY s.id
ORDER BY dcount ASC
De lo contrario, realiza dicha consulta de agrupación para cada posible candidato. Podemos hacer esto más elegante con EXISTS :
SELECT count(d.id) AS dcount, s.id, s.name
FROM sites s
LEFT JOIN deals d ON (s.id = d.site_id AND d.is_active = 1)
WHERE (s.is_active = 1)
AND EXISTS (
SELECT 1
FROM gstats g
WHERE g.site_id = s.id AND g.start_date > '2015-04-30'
HAVING SUM(g.results) > 100
)
GROUP BY s.id
ORDER BY dcount ASC
Pero aún no hemos terminado, ahora usaremos EXISTS para cada elemento. Eso es extraño ya que la consulta solo depende de s.id , por lo que solo depende del grupo , no las filas individuales. Así que un potencial speedup, pero esto depende de los tamaños de las tablas, etc. es mover la condición a un HAVING declaración:
SELECT count(d.id) AS dcount, s.id, s.name
FROM sites s
LEFT JOIN deals d ON (s.id = d.site_id AND d.is_active = 1)
WHERE (s.is_active = 1)
GROUP BY s.id
ORDER BY dcount ASC
HAVING EXISTS (
SELECT 1
FROM gstats g
WHERE g.site_id = s.id AND g.start_date > '2015-04-30'
HAVING SUM(g.results) > 100
)