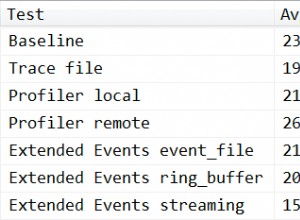
Esto depende completamente del motor DBMS que se utilice. SQL en sí mismo no ordena cómo se almacenan las cosas físicamente, solo cómo se ven lógicamente.
Por ejemplo, su DBMS puede asignar espacio en la fila para el tamaño máximo, además de algunos bytes adicionales para almacenar la longitud. En ese caso, habría una gran diferencia entre varchar(10) y varchar(1000) ya que desperdiciarías bastante espacio por fila.
Alternativamente, puede usar un grupo de búfer para el varchar data y almacena solo la longitud y la "dirección de inicio" del grupo de búfer en la fila. En ese caso, cada fila almacenaría información de tamaño idéntico para un varchar independientemente de su tamaño, pero habría un paso adicional para extraer los datos reales en esa columna (siguiendo el enlace al grupo de búfer).
La razón por la que usa un varchar es exactamente por eso que se llama varchar . Le permite almacenar elementos de datos de tamaño variable. Normalmente, char(10) le da diez caracteres, no importa qué, rellenando con espacios si inserta algo más corto. Puede recortar los espacios finales a medida que los extrae, pero eso no funcionará tan bien si los datos que desea almacenar son en realidad "hello " , con un espacio final que desea conservar.
Un motor DBMS decente puede decidir hacer una compensación dependiendo del tamaño máximo del varchar columna. Para los cortos, simplemente podría almacenarlo en línea en la fila y consumir los bytes adicionales para el tamaño.
varchar más largo las columnas se pueden "subcontratar" a un grupo de búfer separado para garantizar que la lectura de filas se mantenga eficiente (al menos hasta que necesite el gran varchar columna, de todos modos).
Lo que debe hacer es volver a hacer la pregunta para su DBMS específico para obtener una respuesta más específica.
O, con toda honestidad, diseñe su base de datos para almacenar solo el tamaño máximo. Si sabe que es 10, entonces varchar(1000) es un desperdicio Si, en el futuro, necesita ampliar la columna, que es el momento de hacerlo, en lugar de ahora (ver YAGNI
).
Para MySQL, querrá consultar Chapter 14 Storage Engines
de la documentación en línea.
Cubre los diversos motores de almacenamiento (como InnoDB y MyISAM) que usa MySQL y, al mirar lo suficientemente profundo, puede ver cómo se almacena físicamente la información.
Por ejemplo, en MyISAM, la presencia de datos de longitud variable en una tabla (varchar incluido) generalmente significa tablas dinámicas
. Esto sigue un esquema más o menos análogo al concepto de grupo de búfer que mencioné anteriormente, con la ventaja de que se desperdicia menos espacio para columnas de tamaño variable y la desventaja de que las filas pueden fragmentarse.
El otro formato de almacenamiento (descontando el formato comprimido ya que solo se usa para tablas de solo lectura) es el estático , donde los datos se almacenan en una sola fila física.
Puede encontrar información sobre las estructuras físicas de InnoDB aquí . Dependiendo de si usa el formato de archivo Antelope o Barracuda, terminará con la situación de "toda la información es una fila física" o "grupo de búfer", similar a la distinción MyISAM entre dinámico y estático.