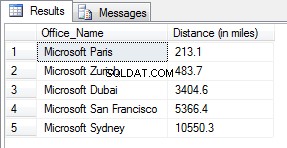
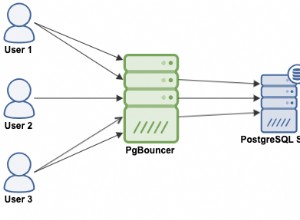
Intentaría lo siguiente:
Primero, asegúrese de que haya índices en las siguientes tablas y columnas (cada conjunto de columnas entre paréntesis debe ser un índice separado):
table1 : (subscribe, CDate)
(CU_id)
table2 : (O_cid)
(O_ref)
table3 : (I_oref)
(I_pid)
table4 : (P_id)
(P_cat)
table5 : (C_id, store)
En segundo lugar, si agregar los índices anteriores no mejoró las cosas tanto como le gustaría, intente reescribir la consulta como
SELECT DISTINCT t1.first_name, t1.last_name, t1.email FROM
(SELECT CU_id, t1.first_name, t1.last_name, t1.email
FROM table1
WHERE subscribe = 1 AND
CDate >= $startDate AND
CDate <= $endDate) AS t1
INNER JOIN table2 AS t2
ON t1.CU_id = t2.O_cid
INNER JOIN table3 AS t3
ON t2.O_ref = t3.I_oref
INNER JOIN table4 AS t4
ON t3.I_pid = t4.P_id
INNER JOIN (SELECT C_id FROM table5 WHERE store = 2) AS t5
ON t4.P_cat = t5.C_id
Espero aquí que la primera subselección reduzca significativamente la cantidad de filas que se considerarán para unirse, con suerte haciendo que las uniones posteriores hagan menos trabajo. Lo mismo ocurre con el razonamiento detrás de la segunda subselección en la tabla 5.
En cualquier caso, métete con eso. Quiero decir, en última instancia, es solo una SELECCIÓN:realmente no puedes dañar nada con eso. Examine los planes generados por cada permutación diferente e intente descubrir qué es bueno o malo en cada uno.
Comparte y disfruta.