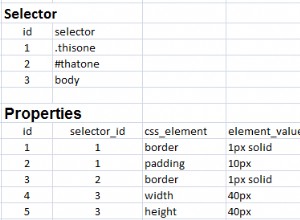
2 millones de bases de datos? Supongo que quisiste decir "filas".
De todos modos, con respecto a las limitaciones:una de las cosas más importantes a tener en cuenta es que NDB/MySQL Cluster no es una base de datos de propósito general. En particular, las operaciones de unión, pero también las subconsultas y las operaciones de rango (consultas como:pedidos creados entre ahora y hace una semana), pueden ser considerablemente más lentas de lo que cabría esperar. Esto se debe en parte al hecho de que los datos se distribuyen en varios nodos. Aunque se han realizado algunas mejoras, el rendimiento de Join aún puede ser muy decepcionante.
Por otro lado, si necesita lidiar con muchas transacciones simultáneas (preferiblemente pequeñas) (por lo general, actualizaciones/inserciones/eliminación de búsquedas de una sola fila por clave principal) y quiere mantener todos sus datos en la memoria, entonces puede ser muy solución escalable y eficiente.
Deberías preguntarte por qué quieres un clúster. Si simplemente desea la base de datos ordinaria que tiene ahora, excepto con una disponibilidad adicional del 99,999 %, es posible que se sienta decepcionado. Ciertamente, el clúster de MySQL puede proporcionarle una gran disponibilidad y tiempo de actividad, pero es posible que la carga de trabajo de su aplicación no sea muy adecuada para las cosas para las que es bueno el clúster. Además, es posible que pueda utilizar otra solución de alta disponibilidad para aumentar el tiempo de actividad de su base de datos tradicional.
Por cierto, aquí hay una lista de limitaciones según el documento:http://dev.mysql.com/doc/refman/5.1/en/mysql-cluster-limitations.html
Pero hagas lo que hagas, prueba el clúster, mira si es bueno para ti. El clúster de MySQL no es "MySQL + 5 nueves". Lo descubrirás cuando lo intentes.