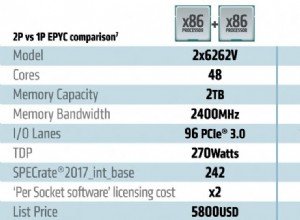
He estado jugando.
Creo que usar su diseño actual de datos podría hacerse como:-
SELECT COALESCE(IF(vote_candidate_b IN (4,3,5), NULL, vote_candidate_b),
IF(vote_candidate_c IN (4,3,5), NULL, vote_candidate_c),
IF(vote_candidate_d IN (4,3,5), NULL, vote_candidate_d),
IF(vote_candidate_e IN (4,3,5), NULL, vote_candidate_e),
IF(vote_candidate_f IN (4,3,5), NULL, vote_candidate_f)) AS vote_candidate,
COUNT(*)
FROM votes
WHERE vote_candidate_a = 4
GROUP BY vote_candidate;
Esto es más o menos como ha respondido fancypants. No estoy interesado en esto, ya que no parece fácil de leer y (si la cantidad de datos es grande) es probable que sea ineficiente.
Me inclinaría más a dividir los datos en una estructura de tabla diferente, con varias filas por conjunto de votos, una por candidato. Esto sería mucho más fácil de hacer si el sistema se encuentra en las primeras etapas de desarrollo (es decir, solo genera las tablas nuevas).
Suponiendo que sus datos existentes se configuraron de la siguiente manera:-
CREATE TABLE votes
(
vote_id INT NOT NULL AUTO_INCREMENT,
vote_candidate_a INT,
vote_candidate_b INT,
vote_candidate_c INT,
vote_candidate_d INT,
vote_candidate_e INT,
vote_candidate_f INT
);
INSERT INTO votes
VALUES
(NULL, 4, 1, 6, 3, 2, 5),
(NULL, 4, 3, 1, 6, 2, 5),
(NULL, 4, 5, 6, 2, 3, 1),
(NULL, 4, 3, 1, 5, 6, 2);
mi formato podría generarse de la siguiente manera:-
CREATE TABLE vote_orders
(
id INT NOT NULL AUTO_INCREMENT,
vote_id INT,
vote_order INT,
vote_candidate INT
);
INSERT INTO vote_orders (id, vote_id, vote_order, vote_candidate)
SELECT NULL, vote_id, 1, vote_candidate_a FROM votes
UNION
SELECT NULL, vote_id, 2, vote_candidate_b FROM votes
UNION
SELECT NULL, vote_id, 3, vote_candidate_c FROM votes
UNION
SELECT NULL, vote_id, 4, vote_candidate_d FROM votes
UNION
SELECT NULL, vote_id, 5, vote_candidate_e FROM votes
UNION
SELECT NULL, vote_id, 6, vote_candidate_f FROM votes;
Luego, simplemente puede usar lo siguiente para obtener los votos. Esto usa una subconsulta para obtener el voto más alto que aún no se haya usado y luego lo une contra los datos.
SELECT vote_candidate, COUNT(*)
FROM vote_orders a
INNER JOIN
(
SELECT vote_id, MIN(vote_order) AS min_vote_order
FROM vote_orders
WHERE vote_candidate NOT IN (4,3,5)
GROUP BY vote_id
) b
ON a.vote_id = b.vote_id
AND a.vote_order = b.min_vote_order
INNER JOIN
(
SELECT vote_id
FROM vote_orders
WHERE vote_candidate = 4
AND vote_order = 1
) c
ON a.vote_id = c.vote_id
GROUP BY vote_candidate
violín SQL aquí:-
http://www.sqlfiddle.com/#!2/7d48c/10
Una solución híbrida (¡lo peor de ambos mundos!):-
SELECT vote_candidate, COUNT(*)
FROM
(
SELECT vote_id, 1 AS vote_order, vote_candidate_a AS vote_candidate FROM votes WHERE vote_candidate_a = 4
UNION
SELECT vote_id, 2, vote_candidate_b FROM votes WHERE vote_candidate_a = 4
UNION
SELECT vote_id, 3, vote_candidate_c FROM votes WHERE vote_candidate_a = 4
UNION
SELECT vote_id, 4, vote_candidate_d FROM votes WHERE vote_candidate_a = 4
UNION
SELECT vote_id, 5, vote_candidate_e FROM votes WHERE vote_candidate_a = 4
UNION
SELECT vote_id, 6, vote_candidate_f FROM votes WHERE vote_candidate_a = 4
) a
INNER JOIN
(
SELECT vote_id, MIN(vote_order) AS min_vote_order
FROM
(
SELECT vote_id, 2 AS vote_order, vote_candidate_b AS vote_candidate FROM votes
UNION
SELECT vote_id, 3, vote_candidate_c FROM votes
UNION
SELECT vote_id, 4, vote_candidate_d FROM votes
UNION
SELECT vote_id, 5, vote_candidate_e FROM votes
UNION
SELECT vote_id, 6, vote_candidate_f FROM votes
) a
WHERE vote_candidate NOT IN (4,3,5)
GROUP BY vote_id
) b
ON a.vote_id = b.vote_id
AND a.vote_order = b.min_vote_order
GROUP BY vote_candidate;