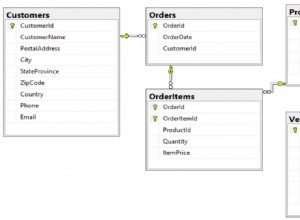
Hablé con el arquitecto de la base de datos de wordpress.com, el servicio de alojamiento de WordPress. Dijo que comenzaron con una base de datos, alojando a todos los clientes juntos. Después de todo, el contenido de un solo sitio de blog no es mucho. Es lógico pensar que una sola base de datos es más manejable.
Esto funcionó bien para ellos hasta que obtuvieron cientos y miles de clientes, se dieron cuenta de que necesitaban escalar horizontalmente , ejecutando varios servidores físicos y alojando un subconjunto de sus clientes en cada servidor. Cuando agregan un servidor, sería fácil migrar clientes individuales al nuevo servidor, pero sería más difícil separar los datos dentro de una sola base de datos que pertenece al blog de un cliente individual.
A medida que los clientes van y vienen, y los blogs de algunos clientes tienen un gran volumen de actividad mientras que otros se vuelven obsoletos, el reequilibrio entre varios servidores se convierte en un trabajo de mantenimiento aún más complejo. También es más fácil monitorear el tamaño y la actividad por base de datos individual.
Del mismo modo, hacer una copia de seguridad o restauración de la base de datos de una sola base de datos que contiene terabytes de datos, frente a copias de seguridad y restauraciones de bases de datos individuales de unos pocos megabytes cada una, es un factor importante. Considere:un cliente llama y dice que sus datos se interrumpieron debido a una mala entrada de datos, y ¿podría restaurar los datos de la copia de seguridad de ayer? ¿Cómo restaurarías uno? los datos del cliente si todos sus clientes comparten una sola base de datos?
Eventualmente, decidieron que dividirse en una base de datos separada por cliente , aunque complejo de administrar, les ofreció una mayor flexibilidad y rediseñaron su servicio de hospedaje a este modelo.
Entonces, mientras que desde un modelado de datos perspectiva, parece lo correcto mantener todo en una sola base de datos, algo de administración de bases de datos las tareas se vuelven más fáciles a medida que pasa un determinado punto de interrupción del volumen de datos.